 DDD分层架构与微服务代码模型
DDD分层架构与微服务代码模型
DDD 并没有给出标准的代码模型,不同的人可能会有不同理解。这里我们在使用的时候还是建议按照欧创新架构师总结的来进行适用,具体如下:
# 一、代码模型总目录结构

根据 DDD 分层架构模型建立了标准的微服务代码模型,在代码模型里面,各代码对象各据其位、各司其职,共同协作完成微服务的业务逻辑。它包括用户接口层、应用层、领域层和基础层,分层架构各层的职责边界非常清晰,又能有条不紊地分层协作。
- 用户接口层:面向前端提供服务适配,面向资源层提供资源适配。这一层聚集了接口适配相关的功能。
- 应用层职责:实现服务组合和编排,适应业务流程快速变化的需求。这一层聚集了应用服务和事件相关的功能。
- 领域层:实现领域的核心业务逻辑。这一层聚集了领域模型的聚合、聚合根、实体、值对象、领域服务和事件等领域对象,以及它们组合所形成的业务能力。
- 基础层:贯穿所有层,为各层提供基础资源服务。这一层聚集了各种底层资源相关的服务和能力。
业务逻辑从领域层、应用层到用户接口层逐层封装和协作,对外提供灵活的服务,既实现了各层的分工,又实现了各层的协作。
# 1.微服务一级目录结构

微服务一级目录是按照 DDD 分层架构的分层职责来定义的。从下面这张图中,我们可以看到,在代码模型里分别为用户接口层、应用层、领域层和基础层,建立了 interfaces、application、domain 和 infrastructure 四个一级代码目录。
# 2.用户接口层目录结构、职能和代码形态
主要存放用户接口层与前端交互、展现数据相关的代码。前端应用通过这一层的接口,向应用服务获取展现所需的数据。这一层主要用来处理用户发送的 Restful 请求,解析用户输入的配置文件,并将数据传递给 Application 层。数据的组装、数据传输格式以及 Facade 接口等代码都会放在这一层目录里。
具体如下:
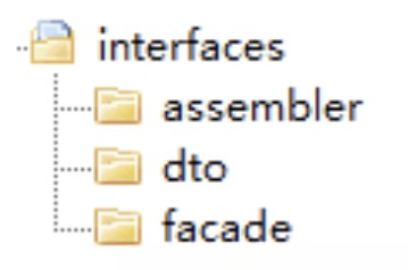
- Assembler:实现 DTO 与领域对象之间的相互转换和数据交换。一般来说 Assembler 与 DTO 总是一同出现。
- Dto:它是数据传输的载体,内部不存在任何业务逻辑,我们可以通过 DTO 把内部的领域对象与外界隔离。
- Facade:提供较粗粒度的调用接口,将用户请求委派给一个或多个应用服务进行处理。
# 3.应用层目录结构、职能和代码形态
主要存放应用层服务组合和编排相关的代码。应用服务****向下基于微服务内的领域服务或外部微服务的应用服务完成服务的编排和组合*,*向上为用户接口层提供各种应用数据展现支持服务**。应用服务和事件等代码会放在这一层目录里。
具体如下:
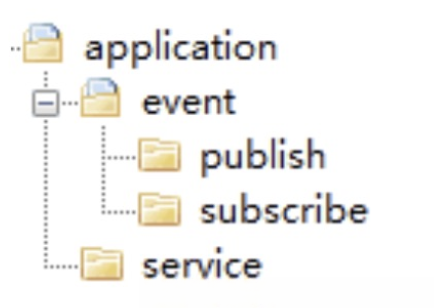
- Event(事件):这层目录主要存放事件相关的代码。它包括两个子目录:publish 和 subscribe。前者主要存放事件发布相关代码,后者主要存放事件订阅相关代码(事件处理相关的核心业务逻辑在领域层实现)。为了实现事件的统一管理,建议你将微服务内所有事件的发布和订阅的处理都统一放到应用层,事件相关的核心业务逻辑实现放在领域层。通过应用层调用领域层服务,来实现完整的事件发布和订阅处理流程。
- Service(应用服务):这层的服务是应用服务。应用服务会对多个领域服务或外部应用服务进行封装、编排和组合,对外提供粗粒度的服务。应用服务主要实现服务组合和编排,是一段独立的业务逻辑。你可以将所有应用服务放在一个应用服务类里,也可以把一个应用服务设计为一个应用服务类,以防应用服务类代码量过大。
# 4.领域层目录结构、职能和代码形态
主要存放领域层核心业务逻辑相关的代码。领域层可以包含多个聚合代码包,它们共同实现领域模型的核心业务逻辑。聚合以及聚合内的实体、方法、领域服务和事件等代码会放在这一层目录里。
具体如下:
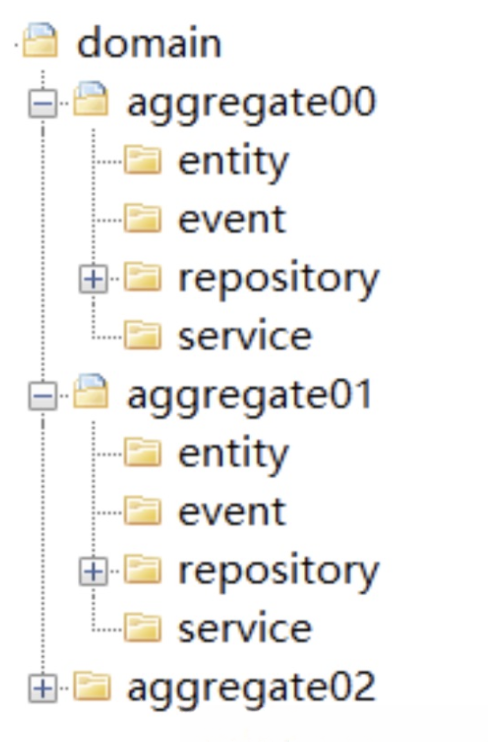
- Aggregate(聚合):它是聚合软件包的根目录,可以根据实际项目的聚合名称命名,比如****权限聚合****。在聚合内定义聚合根、实体和值对象以及领域服务之间的关系和边界。聚合内实现高内聚的业务逻辑,它的代码可以独立拆分为微服务。以聚合为单位的代码放在一个包里的主要目的是为了业务内聚,而更大的目的是为了以后微服务之间聚合的重组。聚合之间清晰的代码边界,可以让你轻松地实现以聚合为单位的微服务重组,在微服务架构演进中有着很重要的作用。
- Entity(实体):它存放聚合根、实体、值对象以及工厂模式(Factory)相关代码。实体类采用充血模型,同一实体相关的业务逻辑都在实体类代码中实现。跨实体的业务逻辑代码在领域服务中实现。
- Event(事件):它存放事件实体以及与事件活动相关的业务逻辑代码。
- Service(领域服务):它存放领域服务代码。一个领域服务是多个实体组合出来的一段业务逻辑。你可以将聚合内所有领域服务都放在一个领域服务类中,你也可以把每一个领域服务设计为一个类。如果领域服务内的业务逻辑相对复杂,建议将一个领域服务设计为一个领域服务类,避免由于所有领域服务代码都放在一个领域服务类中,而出现代码臃肿的问题。领域服务封装多个实体或方法后向上层提供应用服务调用。
- Repository(仓储):它存放所在聚合的查询或持久化领域对象的代码,通常包括仓储接口和仓储实现方法。为了方便聚合的拆分和组合,我们设定了一个原则:一个聚合对应一个仓储。(特别说明:按照 DDD 分层架构,仓储实现本应该属于基础层代码,但为了在微服务架构演进时,保证代码拆分和重组的便利性,把聚合仓储实现的代码放到了聚合包内。)
# 5.基础层层目录结构、职能和代码形态
主要存放基础资源服务相关的代码,为其它各层提供的通用技术能力、三方软件包、数据库服务、配置和基础资源服务的代码都会放在这一层目录里。
具体如下:
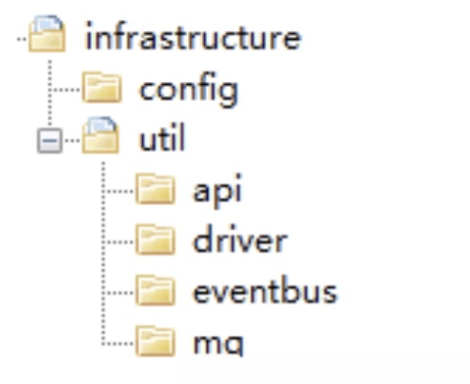
- Config:主要存放配置相关代码。
- Util:主要存放平台、开发框架、消息、数据库、缓存、文件、总线、网关、第三方类库、通用算法等基础代码,你可以为不同的资源类别建立不同的子目录。
# 二、应用层的领域对象分析
应用层的主要领域对象是应用服务和事件的发布以及订阅。
在事件风暴或领域故事分析时,我们往往会根据用户或系统发起的命令,来设计服务或实体方法。为了响应这个命令,我们需要分析和记录:
- 在应用层和领域层分别会发生哪些业务行为;
- 各层分别需要设计哪些服务或者方法;
- 这些方法和服务的分层以及领域类型(比如实体方法、领域服务和应用服务等),它们之间的调用和组合的依赖关系。
在严格分层架构模式下,不允许服务的跨层调用,每个服务只能调用它的下一层服务。服务从下到上依次为:实体方法、领域服务和应用服务。建议采用服务逐层封装的方式,服务的封装和调用主要有以下几种方式:
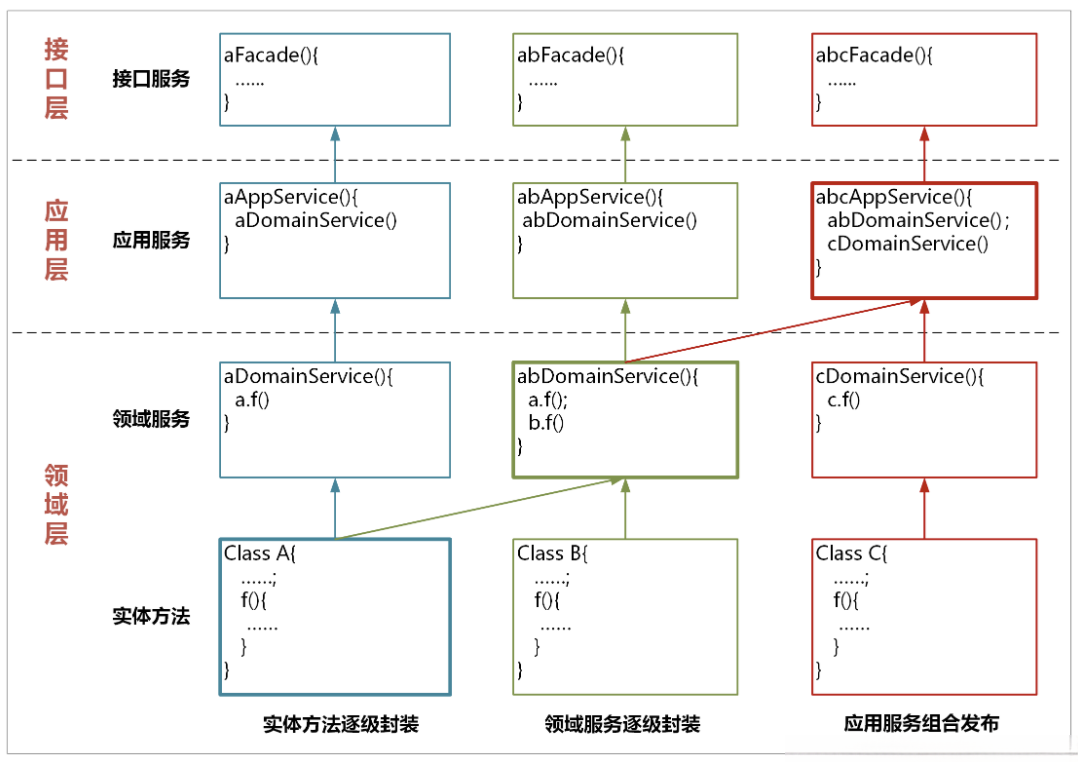
# 1.实体方法的封装
实体方法是最底层的原子业务逻辑。
- 如果单一实体的方法需要被跨层调用,你可以将它封装成领域服务,这样封装的领域服务就可以被应用服务调用和编排了。
- 如果它还需要被用户接口层调用,需要将这个领域服务封装成应用服务。
经过逐层服务封装,实体方法就可以暴露给上面不同的层,实现跨层调用。
封装时服务前面的名字可以保持一致,你****可以用 *DomainService 或 *AppService 后缀来区分领域服务或应用服务****。
# 2.领域服务的组合和封装
领域服务会对多个实体和实体方法进行组合和编排,供应用服务调用。
如果它需要暴露给用户接口层,领域服务就需要封装成应用服务。
# 3.应用服务的组合和编排
应用服务会对多个领域服务进行组合和编排,暴露给用户接口层,供前端应用调用。
多个应用服务可能会对多个同样的领域服务重复进行同样业务逻辑的组合和编排。当出现这种情况时,就需要分析是不是领域服务可以整合了。可以将这几个不断重复组合的领域服务,合并到一个领域服务中实现,这样领域模型将会越来越精炼,更能适应业务的要求。
应用服务类放在应用层 Service 目录结构下。领域事件的发布和订阅类放在应用层 Event 目录结构下。
# 三、领域层的领域对象分析
事件风暴结束时,领域模型聚合内一般会有:聚合、实体、命令和领域事件等领域对象。
在完成故事分析和微服务设计后,微服务的聚合内一般会有:聚合、聚合根、实体、值对象、领域事件、领域服务和仓储等领域对象。
# 1.设计实体
大多数情况下,领域模型的业务实体与微服务的数据库实体是一一对应的。
但某些领域模型的实体在微服务设计时,可能会被设计为多个数据实体,或者实体的某些属性被设计为值对象。
在分层架构里,实体采用充血模型,在实体类内实现实体的全部业务逻辑。这些不同的实体都有自己的方法和业务行为,比如地址实体有新增和修改地址的方法,银行账号实体有新增和修改银行账号的方法。
实体类放在领域层的 Entity 目录结构下。
# 2.找出聚合根
聚合根来源于领域模型,聚合根是一种特殊的实体,它有自己的属性和方法。聚合根可以实现聚合之间的对象引用,还可以引用聚合内的所有实体。
- 在个人客户聚合里,个人客户这个实体是聚合根,它负责管理地址、电话以及银行账号的生命周期。
- 个人客户聚合根通过工厂和仓储模式,实现聚合内地址、银行账号等实体和值对象数据的初始化和持久化。
聚合根类放在代码模型的 Entity 目录结构下。聚合根有自己的实现方法,比如生成客户编码,新增和修改客户信息等方法。
# 3.设计值对象
根据需要将某些实体的某些属性或属性集设计为值对象。值对象类放在代码模型的 Entity 目录结构下。
在个人客户聚合中,客户拥有客户证件类型,它是以枚举值的形式存在,所以将它设计为值对象。
有些领域对象可以设计为值对象,也可以设计为实体,我们需要根据具体情况来分析:
- 如果这个领域对象在其它聚合内维护生命周期,且在它依附的实体对象中只允许整体替换,我们就可以将它设计为值对象。
- 如果这个对象是多条且需要基于它做查询统计,建议将它设计为实体。
# 4.设计领域事件
如果领域模型中领域事件会触发下一步的业务操作,我们就需要设计领域事件。
- 首先确定领域事件发生在微服务内还是微服务之间。
- 然后设计事件实体对象,事件的发布和订阅机制,以及事件的处理机制。
- 判断是否需要引入事件总线或消息中间件。
领域事件实体和处理类放在领域层的 Event 目录结构下。领域事件的发布和订阅类建议放在应用层的 Event 目录结构下。
# 5.设计领域服务
如果一个业务动作或行为跨多个实体,我们就需要设计领域服务。
领域服务通过对多个实体和实体方法进行组合,完成核心业务逻辑。可以认为领域服务是位于实体方法之上和应用服务之下的一层业务逻辑。
按照严格分层架构层的依赖关系:
- 如果实体的方法需要暴露给应用层,它需要封装成领域服务后才可以被应用服务调用。
- 如果有的实体方法需要被前端应用调用,我们会将它封装成领域服务,然后再封装为应用服务。
领域服务类放在领域层的 Service 目录结构下。
# 6.设计仓储
每一个聚合都有一个仓储,仓储主要用来完成数据查询和持久化操作。
仓储包括仓储的接口和仓储实现,通过依赖倒置实现应用业务逻辑与数据库资源逻辑的解耦。
仓储代码放在领域层的 Repository 目录结构下。
# 四、代码模型强调内容
# 第一点:聚合之间的代码边界一定要清晰。
聚合之间的服务调用和数据关联应该是尽可能的松耦合和低关联,聚合之间的服务调用应该通过上层的应用层组合实现调用,原则上不允许聚合之间直接调用领域服务。
这种松耦合的代码关联,在以后业务发展和需求变更时,可以很方便地实现业务功能和聚合代码的重组,在微服务架构演进中将会起到非常重要的作用。
# 第二点:你一定要有代码分层的概念。
写代码时一定要搞清楚代码的职责,将它放在职责对应的代码目录内。
应用层代码主要完成服务组合和编排,以及聚合之间的协作,它是很薄的一层,不应该有核心领域逻辑代码。
领域层是业务的核心,领域模型的核心逻辑代码一定要在领域层实现。
如果将核心领域逻辑代码放到应用层,你的基于 DDD 分层架构模型的微服务慢慢就会演变成传统的三层架构模型了。