 设计模式 - 设计思想
设计模式 - 设计思想
# 1. 基于接口而非实现编程
# 1. 什么是“基于接口而非实现编程”
定义:
“基于接口而非实现编程”(Program to an interface, not an implementation)是指在软件开发中,应该让代码依赖于抽象(接口或抽象类),而非具体的实现。其目的是让程序具有更高的扩展性、灵活性和可维护性,便于应对未来的需求变化。
- 抽象:是指通过接口或抽象类描述程序的行为,而不关心具体实现的细节。
- 实现:是接口的具体功能实现,可能会随着需求的变化而更新。
背景:
这一设计原则最早出现在 1994 年 GoF(Gang of Four)的《设计模式》一书中,书中的设计模式大多是基于该原则的。设计模式的目的是提供一套通用的解决方案,帮助开发者解决重复出现的问题。在基于接口编程的方式中,接口代表了一种通用行为或协议,而具体的实现则可以根据需求变化灵活替换。
适用性:
- 接口:接口不仅指编程语言中的
interface,还可以是抽象类,或者任何代表协议或约定的抽象层。 - 实现类:实现类是对接口的具体实现,代表了某种特定的功能。
# 2. 为什么要“基于接口而非实现编程”
主要目标:
- 降低耦合:依赖接口,而不是具体实现,可以将代码的依赖关系降到最低,使得系统的模块能够独立修改而不影响其他模块。
- 提高扩展性:通过依赖抽象,能够更方便地替换或扩展功能,而不会对现有代码造成较大影响。
- 增强灵活性:抽象的接口可以支持多个实现,开发者可以根据不同的需求选择不同的实现方式,而不需要修改上层代码。
问题的根源:
在编程中,最大的挑战之一就是应对需求变化。需求的变化往往会导致系统中某些部分的实现需要更改。如果代码直接依赖具体实现,那么当实现发生变化时,调用该实现的所有代码都可能需要修改。这样会增加代码维护的复杂度。
# 3. 理解“接口”中的抽象含义
接口不仅仅是语言中的 interface:
“接口”在这里并不是仅仅指 Java 或其他语言中的 interface 关键字,而是广义上的抽象层。在不同的场景中,接口可以是不同的东西:
- 在软件层面上,接口可以是某个服务对外暴露的功能列表或 API;
- 在类设计层面,接口可以是类的抽象父类或者直接定义为一个接口;
- 在设计模式中,接口可以理解为一种“协议”或行为契约,定义了某个模块的功能行为而不涉及实现细节。
面向抽象的编程:
编写代码时,不应该直接依赖具体的实现,而是要通过抽象的接口来实现功能。通过这种方式,可以将代码的通用部分抽象出来,使得具体的实现细节可以随着需求变化而灵活变动。
# 4. 实战场景:图片存储系统的设计
场景问题描述:
假设我们正在开发一个图片处理系统,需要将处理后的图片上传到阿里云的存储服务中。在初期开发中,整个系统只需要支持阿里云这一种存储方式,于是我们实现了如下代码:
public class AliyunImageStore {
// 创建 bucket,如果不存在的话
public void createBucketIfNotExisting(String bucketName) {
// 创建 bucket 相关代码逻辑
}
// 生成访问阿里云的 access token
public String generateAccessToken() {
// 根据 accessKey 和 secretKey 生成访问凭证
return "accessToken";
}
// 上传图片到阿里云
public String uploadToAliyun(Image image, String bucketName, String accessToken) {
// 上传图片到阿里云的逻辑
return "imageUrl"; // 返回图片的 URL
}
// 从阿里云下载图片
public Image downloadFromAliyun(String url, String accessToken) {
// 下载图片的逻辑
return new Image(); // 返回图片对象
}
}
// AliyunImageStore 的使用
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
public void process() {
Image image = ...; // 处理图片,生成 Image 对象
AliyunImageStore imageStore = new AliyunImageStore();
imageStore.createBucketIfNotExisting(BUCKET_NAME);
String accessToken = imageStore.generateAccessToken();
imageStore.uploadToAliyun(image, BUCKET_NAME, accessToken);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
问题分析:
- 系统灵活性不足:如果将来我们需要将图片存储在其他云平台或自建私有云,代码中大量依赖
AliyunImageStore的部分将不得不进行修改,改动范围较大。 - 命名暴露实现细节:方法名如
uploadToAliyun()和downloadFromAliyun()直接暴露了具体的实现,这会让未来的更改更加复杂。 - 需求变化难以应对:未来如果阿里云的存储方式发生了变化,或者我们需要支持多种存储方式(如自建私有云),这些变化会导致代码的复杂度大幅增加。
# 5. 改进:基于接口设计
为了让代码更灵活,我们可以通过“基于接口而非实现编程”的原则进行改造。
第一步:定义接口
我们首先定义一个通用的 ImageStore 接口,将图片的上传和下载逻辑抽象化:
public interface ImageStore {
// 上传图片接口,返回图片存储的 URL
String upload(Image image, String bucketName);
// 下载图片接口,返回 Image 对象
Image download(String url);
}
2
3
4
5
6
7
第二步:具体的实现类
- 阿里云存储的实现:
我们将原来存储到阿里云的逻辑实现为
AliyunImageStore类,并实现ImageStore接口。
public class AliyunImageStore implements ImageStore {
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
String accessToken = generateAccessToken();
// 上传图片到阿里云
return "imageUrl"; // 返回阿里云上的图片 URL
}
public Image download(String url) {
String accessToken = generateAccessToken();
// 从阿里云下载图片
return new Image(); // 返回图片对象
}
private void createBucketIfNotExisting(String bucketName) {
// 创建 bucket 相关代码
}
private String generateAccessToken() {
// 生成 access token 的逻辑
return "accessToken";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
- 私有云存储的实现: 假设我们需要支持自建私有云存储,新的实现如下:
public class PrivateImageStore implements ImageStore {
public String upload(Image image, String bucketName) {
createBucketIfNotExisting(bucketName);
// 上传图片到私有云
return "imageUrl"; // 返回私有云的图片 URL
}
public Image download(String url) {
// 从私有云下载图片
return new Image(); // 返回图片对象
}
private void createBucketIfNotExisting(String bucketName) {
// 创建 bucket 的逻辑
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
第三步:依赖接口编程
通过依赖接口 ImageStore,业务逻辑代码不再关心具体的实现细节,而是依赖于抽象的接口。如下是改进后的业务逻辑代码:
public class ImageProcessingJob {
private static final String BUCKET_NAME = "ai_images_bucket";
private ImageStore imageStore;
// 构造函数注入具体的存储实现类
public ImageProcessingJob(ImageStore imageStore) {
this.imageStore = imageStore;
}
public void process() {
Image image = ...; // 处理图片生成 Image 对象
imageStore.upload(image, BUCKET_NAME); // 通过接口上传图片
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
通过这种方式,如果将来需要切换到其他存储平台,我们只需要替换 ImageStore 的具体实现,而不需要修改业务逻辑的代码。
# 6. 解决问题的关键点
封装实现细节:
具体的存储实现类(如 AliyunImageStore 和 PrivateImageStore)不对外暴露任何实现细节。上层代码只依赖接口 ImageStore,而不依赖具体的实现类。
接口定义足够抽象:
接口 ImageStore 的设计只定义了上传和下载的功能,并没有暴露实现细节。这样,当新的实现方式加入时(如其他云服务),接口可以保持不变。
适应需求变化:
通过接口和实现分离,当需求发生变化时,系统的扩展性和灵活性都得到了保障。无论是新增存储服务,还是修改存储逻辑,上层代码都不需要进行大幅度修改。
# 7. 是否需要为每个类定义接口
在实际开发中,关于是否要为每个类定义接口,不需要走极端,以下是需要重点考虑的几个原则和建议:
不必为每个实现类都定义接口: 并不是所有类都需要强制定义接口,尤其是当某个类的实现很简单且没有替换的需求时,直接使用实现类即可。例如,如果一个类的功能很固定,未来也不会有多个实现,定义接口反而会增加不必要的复杂性。
适度使用接口: 在设计中要讲究适度,过度使用“基于接口编程”可能导致接口泛滥,增加开发和维护负担。接口的引入应该是为了应对需求变化、提升代码的灵活性和扩展性,而不是为了遵守原则而滥用接口。
设计原则的初衷: 这个原则的核心目标是将不稳定的实现细节封装起来,对外暴露稳定的接口,从而让代码更具扩展性和灵活性。这样,当实现发生变化时,调用代码几乎不需要做修改,系统的耦合性降低了,扩展性和维护性增强了。
何时不需要定义接口: 如果某个功能只有唯一的实现方式,并且未来也不可能被替换,那就没有必要为其定义接口。直接使用实现类既可以简化代码,又避免了不必要的抽象。
何时需要定义接口: 当系统存在较大的不确定性、需求变化频繁,或者可能出现多种实现时,为类定义接口是非常有必要的。接口可以保证系统能够灵活地替换实现而不影响上层代码的逻辑。
总结:接口的设计应该围绕着系统的不稳定性来权衡,越是不稳定、变化较大的功能,越需要通过接口来解耦、扩展。而对于稳定的系统或功能,直接使用实现类即可,避免过度设计和增加维护成本。
# 2. 多用组合少用继承
在面向对象编程中,有一条非常经典的设计原则:多用组合,少用继承(Favor composition over inheritance)。这个原则帮助开发者设计更灵活、可维护的代码结构。接下来,我们将围绕以下三个问题进行详细讲解:
- 为什么不推荐使用继承?
- 组合相比继承有哪些优势?
- 如何判断该用组合还是继承?
# 1. 为什么不推荐使用继承
继承是 OOP 的四大特性之一,用来表达类之间的 is-a 关系,并支持代码复用。但是,继承的层次越深、关系越复杂,代码的可维护性就越差。让我们通过一个简单的例子,逐步分析为什么继承有时会带来问题。
# 1.1 问题示例:鸟类继承的设计
假设我们要设计一个关于鸟类的系统。我们可以将「鸟」这种概念抽象成一个父类 AbstractBird,然后所有的具体鸟类(例如麻雀、鸽子、乌鸦等)都继承这个父类。
public class AbstractBird {
// ...省略其他属性和方法...
public void fly() {
// 实现飞行功能
}
}
2
3
4
5
6
现在的问题来了——虽然大多数鸟类都会飞,但也有例外。例如,鸵鸟不能飞。如果鸵鸟继承了 AbstractBird,就继承了 fly() 方法,显然不符合现实情况。为了解决这个问题,我们可以在鸵鸟类中重写 fly() 方法,使其抛出一个异常:
public class Ostrich extends AbstractBird {
@Override
public void fly() {
throw new UnsupportedOperationException("I can't fly.");
}
}
2
3
4
5
6
虽然这种设计可以解决鸵鸟不会飞的问题,但它并不优雅,原因有以下几点:
- 破坏了直观逻辑:鸵鸟继承了
fly()这样不适合它的行为,虽然重写了这个方法抛出了异常,但从设计角度来看,不应该让不具备飞行能力的类拥有fly()方法。 - 代码复杂化:如果有更多不会飞的鸟类(如企鹅、鸡),我们都需要逐一重写
fly()方法并抛出异常,这显然增加了不必要的代码量。 - 不必要的暴露:子类鸵鸟暴露了不该暴露的
fly()方法,增加了被误用的风险。任何调用fly()的代码都可能意外触发异常。
# 1.2 继承导致的复杂性
为了避免每个不会飞的鸟类都重写 fly() 方法,我们可以将鸟类的继承体系进一步细化。例如,我们可以将 AbstractBird 进一步拆分为两个抽象类:AbstractFlyableBird(会飞的鸟类)和 AbstractUnFlyableBird(不会飞的鸟类)。这样,所有会飞的鸟继承 AbstractFlyableBird,不会飞的鸟继承 AbstractUnFlyableBird。
public abstract class AbstractFlyableBird extends AbstractBird {
public abstract void fly();
}
public abstract class AbstractUnFlyableBird extends AbstractBird {
public void fly() {
throw new UnsupportedOperationException("I can't fly.");
}
}
2
3
4
5
6
7
8
9
但是,问题还没有结束。我们现在只处理了“是否会飞”的问题。如果我们再考虑其他行为,例如鸟是否会叫,那么我们可能会陷入继承关系的组合爆炸。新的继承关系可能变得非常复杂,如下所示:
- 会飞会叫的鸟:
AbstractFlyableTweetableBird - 会飞不会叫的鸟:
AbstractFlyableUnTweetableBird - 不会飞会叫的鸟:
AbstractUnFlyableTweetableBird - 不会飞不会叫的鸟:
AbstractUnFlyableUnTweetableBird
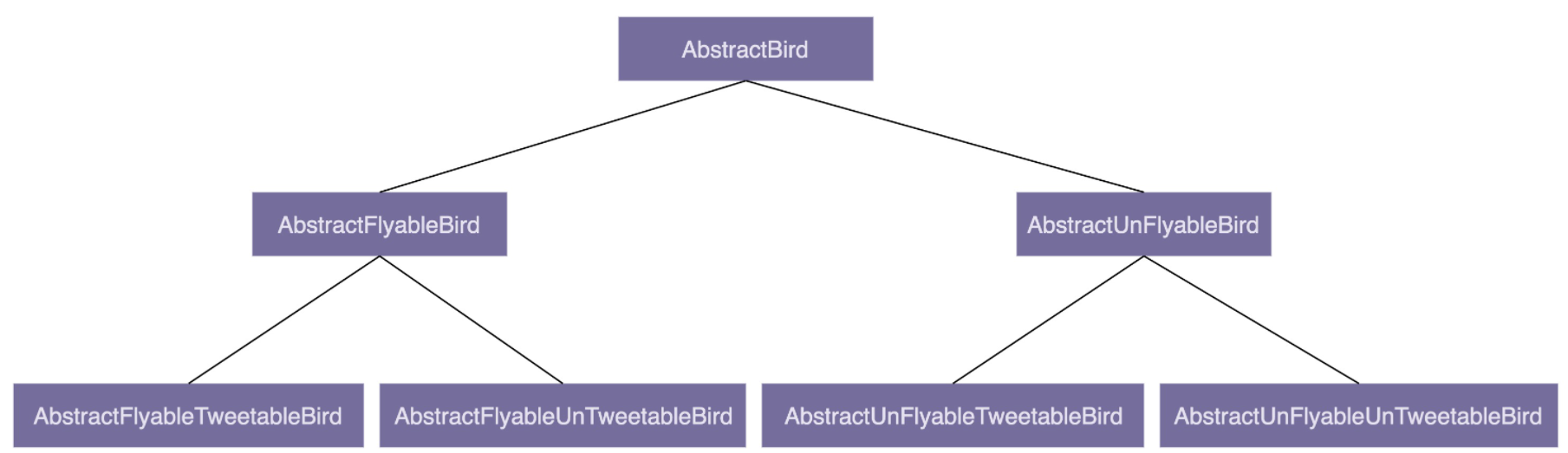
随着行为维度的增加,类的数量也会成倍增加,继承层次也会变得非常深。这种情况会导致以下问题:
- 代码可读性下降:开发者必须逐层阅读父类和祖父类的代码,才能理解某个子类的全部行为。
- 维护难度增加:任何对父类的修改都会影响子类,容易引发连锁反应。
- 耦合度高:子类依赖父类的实现细节,父类的一点变动可能影响多个子类的功能。
总结来说,继承层次过深、继承关系过于复杂,会影响代码的可读性、扩展性和维护性。这也是为什么在现代软件设计中,我们会建议尽量减少对继承的使用。
# 2. 组合相比继承有哪些优势?
相比于继承,组合(composition)通过接口、委托(delegation)等技术手段,可以提供更灵活的解决方案。组合的核心思想是将行为与对象进行分离,通过对象的组合来实现多样化的功能。与继承相比,组合有以下几个优势:
# 2.1 灵活性更高
继承是静态的,在编译时确定类与类之间的关系。而组合是动态的,可以在运行时通过组合不同的对象来实现新的功能。组合的灵活性允许对象根据需求在运行时装配不同的行为。
示例:通过组合实现鸟类行为
我们可以通过定义接口来描述鸟类的行为特性。这样,所有的鸟类根据它们的实际特性,实现对应的接口,而不必再通过继承来实现。
public interface Flyable {
void fly();
}
public interface Tweetable {
void tweet();
}
public interface EggLayable {
void layEgg();
}
2
3
4
5
6
7
8
9
10
11
接下来,我们让不同的鸟类根据其特性,实现相应的接口:
public class Ostrich implements Tweetable, EggLayable {
@Override
public void tweet() {
System.out.println("Ostrich tweets.");
}
@Override
public void layEgg() {
System.out.println("Ostrich lays egg.");
}
}
public class Sparrow implements Flyable, Tweetable, EggLayable {
@Override
public void fly() {
System.out.println("Sparrow flies.");
}
@Override
public void tweet() {
System.out.println("Sparrow tweets.");
}
@Override
public void layEgg() {
System.out.println("Sparrow lays egg.");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
通过这种方式,每种鸟类只实现它需要的行为,而不必通过继承去继承不必要的功能。这种设计使代码更加灵活,也符合现实中的需求变化。
# 2.2 更好的代码复用
继承是通过共享父类的方法来实现代码复用,但当不同类之间的功能不完全相同时,继承就会带来问题。而组合通过将通用的行为封装到独立的类中,再通过委托来复用代码,实现了更灵活的代码共享。
示例:通过组合与委托实现代码复用
假设所有的鸟类下蛋的行为是一样的。我们可以将 layEgg() 方法提取到一个单独的类中,所有鸟类通过组合这个类来实现 layEgg() 行为,而不需要每个类都重新实现。
public class EggLayAbility implements EggLayable {
@Override
public void layEgg() {
System.out.println("Lays egg.");
}
}
public class Ostrich implements Tweetable, EggLayable {
private EggLayAbility eggLayAbility = new EggLayAbility(); // 组合
@Override
public void tweet() {
System.out.println("Ostrich tweets.");
}
@Override
public void layEgg() {
eggLayAbility.layEgg(); // 委托
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
通过委托,Ostrich 类复用了 EggLayAbility 类中的 layEgg() 方法,而不需要重新实现。相比于继承,组合和委托实现了更灵活的代码复用,且避免了继承层次过深的问题。
# 2.3 降低耦合,增强扩展性
继承会导致父类和子类之间的紧密耦合,而组合则通过对象的组合关系,使类之间的依赖关系更加松散。通过组合,可以根据需要灵活地替换对象的行为,实现扩展性。
# 3. 如何判断该用组合还是继承
虽然组合比继承更灵活,但并不意味着继承在所有情况下都是错误的设计。在实际开发中,如何选择组合还是继承,取决于具体的场景和需求。
# 3.1 系统的稳定性
继承适用于稳定系统:如果类之间的继承关系比较稳定,继承层次较浅,且不太可能发生变更,那么使用继承是合适的。例如,继承层次简单、业务逻辑清晰的场景下,继承可以减少代码冗余。
组合适用于不稳定系统:如果系统中的类关系复杂,继承层次较深,且需求频繁变化,组合是更好的选择。组合的灵活性能够应对不确定的需求变化,同时降低类与类之间的耦合度。
# 3.2 设计模式的选择
一些设计模式天然适合组合,而另一些则依赖于继承。例如:
- 装饰者模式(Decorator Pattern)、策略模式(Strategy Pattern) 都是基于组合来实现的。
- 模板方法模式(Template Method Pattern) 则依赖于继承来定义操作的骨架。
根据使用的设计模式,合理选择组合或继承。
# 3.3 代码复用的场景
继承可以用于代码复用,但不应该为代码复用而强行创建父类。当两个类之间并没有天然的继承关系时(例如 Crawler 和 PageAnalyzer),仅仅为了复用某个功能而创建一个父类,可能会导致设计不合理。这种情况下,使用组合会更灵活合理。
public class Url {
// URL 相关操作
}
public class Crawler {
private Url url; // 组合
public Crawler() {
this.url = new Url();
}
}
public class PageAnalyzer {
private Url url; // 组合
public PageAnalyzer() {
this.url = new Url();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3.4 必须使用继承的特殊情况
在某些场景下,继承是唯一可行的方案。例如,当你使用某个外部库或框架中的类,但无法修改其实现时,继承是实现定制化功能的唯一选择。
public class CustomizedFeignClient extends FeignClient {
@Override
public void encode(String url) {
// 重写方法
}
}
2
3
4
5
6
在这种情况下,继承能够帮助你扩展现有类的功能,而不需要改变其接口。
总结
- 多用组合,少用继承 是为了避免继承带来的复杂性和耦合性。通过组合、接口和委托技术,类的行为可以更加灵活地进行组合和复用。
- 继承适用于稳定且简单的系统,而组合则更适合应对复杂、不确定的系统需求。
- 无论是组合还是继承,都有其适用场景,合理选择取决于需求的复杂性、设计模式的使用以及系统的扩展性需求。
# 3. 通过封装、抽象、模块化、中间层等解耦代码
在软件设计和开发过程中,解耦 是提高系统可维护性、扩展性和灵活性的重要手段。代码解耦的核心是降低模块、类之间的依赖性,从而减少系统内部的复杂耦合,使得代码更易于修改、测试和扩展。解耦不仅仅适用于类与类之间的关系,也可以用于系统、模块、接口等不同层次的设计。通过封装、抽象、模块化和引入中间层,开发者能够有效控制代码的复杂度,使系统更加稳健。
# 1. 解耦为何如此重要
1. 复杂性是软件开发的最大挑战
软件开发的核心问题之一是如何应对复杂性。随着系统规模的扩大,模块、类之间的依赖关系会变得越来越复杂,代码的可读性和可维护性也会随之下降。如果模块之间耦合过于紧密,那么任何一次修改都会牵一发而动全身,造成修改成本极高,甚至可能导致系统出现难以排查的 bug。
通过解耦,可以将模块或类之间的关系简化,使得系统的每一部分都能独立运行和修改。这就大大降低了维护成本,提高了代码的灵活性。
2. 高内聚、松耦合的代码结构更加清晰
高内聚、松耦合 是软件设计中的核心原则。内聚性指的是一个模块或类内部各部分的紧密程度,高内聚意味着模块内部的职责单一、相关性强。松耦合指的是模块或类之间的依赖尽量少且松散。通过解耦设计,代码模块能够保持独立性,减少复杂的相互依赖,提升系统的可维护性和可读性。
这种设计不仅能应用于细粒度的类与类之间,还可以用于粗粒度的系统、架构与模块设计。通过高内聚、松耦合,我们可以让开发人员在修改代码时,专注于单一模块或功能,而不必担心修改会影响其他部分。这种设计能有效减少引入 bug 的概率,同时提高代码的测试性。
3. 更少的依赖意味着更高的可测试性
解耦后的代码通常更容易进行单元测试,因为模块或类之间的依赖关系被弱化,开发者可以轻松使用 mock 技术隔离外部依赖来进行测试。通过减少模块间的依赖,我们可以更加专注于单一模块的功能测试,避免因依赖其他模块而引发的复杂问题。
4. 提高系统的扩展性与可维护性
松散耦合的代码使得系统扩展和维护更为简单。如果系统中的某个模块需要升级或替换,解耦设计能够保证更改只会影响到少数模块,而不会导致大范围的修改。这样,系统的长期维护成本将大大降低。
# 2. 如何判断代码是否需要解耦
判断代码是否需要解耦是一个非常重要的问题。过度耦合的代码不仅难以维护,还可能导致系统崩溃或者难以扩展。以下是判断代码耦合程度的一些标准和方法:
1. 直接衡量标准:依赖关系图
通过绘制系统中各个模块、类之间的依赖关系图,可以清晰地看到模块或类之间的依赖性。如果依赖关系图复杂、混乱,那么这表明系统的耦合度很高,代码的可读性和可维护性较差。此时,需要通过重构来解耦,使依赖关系变得更加简单、清晰。
例如,在某个系统中,如果多个模块直接依赖同一个底层模块(如数据库存储层),则可以考虑引入中间层来简化依赖关系。
2. 间接衡量标准:修改代码的影响范围
另一个判断代码是否需要解耦的有效方法是观察代码修改时的影响范围。如果修改一个模块或类的代码,会导致许多其他模块或类同时需要修改,说明系统的耦合度较高。这种现象表明系统的模块设计过于依赖其他模块,需要通过解耦来减少这种紧密的依赖。
系统中每次修改代码时,如果需要修改多个不相关的部分,这种牵连效应就是过度耦合的表现。解耦可以有效地将修改影响的范围限制在局部,减少不必要的代码变动。
# 3. 如何进行代码解耦
实现代码解耦的手段有很多,包括封装、抽象、中间层、模块化等设计手段。通过这些方法,开发者能够有效地减少系统中的依赖性,使系统结构更加灵活。
# 3.1 封装与抽象
封装 和 抽象 是面向对象设计中的基本概念,也是解耦的核心手段之一。
封装:封装通过隐藏实现细节,只暴露必要的接口,从而减少模块与外部的直接依赖。外部模块只需要调用接口,而不必关心模块的内部实现逻辑。这样,当内部实现变化时,只要接口不变,外部模块就不会受到影响。
抽象:抽象是通过接口或抽象类来定义模块的行为规范,屏蔽具体的实现细节。通过抽象,系统可以依赖接口而非具体实现,从而降低模块之间的耦合度。
示例:使用接口进行封装和抽象
public interface PaymentProcessor {
void processPayment(double amount);
}
public class PayPalProcessor implements PaymentProcessor {
@Override
public void processPayment(double amount) {
// 使用 PayPal 处理支付
}
}
public class StripeProcessor implements PaymentProcessor {
@Override
public void processPayment(double amount) {
// 使用 Stripe 处理支付
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在这个例子中,PaymentProcessor 是一个抽象的支付接口,不同的支付处理器如 PayPal 和 Stripe 实现了这个接口。调用方只需依赖 PaymentProcessor,而不关心具体的支付方式。这种设计使得系统可以轻松切换支付处理器,而不需要修改调用方的代码。
# 3.2 中间层的引入
中间层 是一种常见且有效的解耦手段,它通过在模块之间引入一个中间的层级,帮助减少各个模块直接依赖底层实现的情况。中间层作为一个抽象层或适配层,负责模块之间的协调和通信,使得模块间的依赖关系更加松散,并且可以有效降低耦合性。
通过中间层,多个上层模块不再直接依赖底层的实现细节(例如缓存系统、数据库等),而是通过中间层来与这些底层服务进行交互。中间层负责处理复杂的底层操作,屏蔽实现细节,上层模块只需调用中间层提供的接口。这种设计使系统更加灵活,便于扩展和维护。
引入中间层简化依赖关系的示例
在没有中间层的设计中,假设多个业务模块(例如 A、B、C 模块)都直接依赖于多个底层服务(如内存缓存、Redis 缓存、数据库)。这样的依赖关系可能会导致各个业务模块需要了解和处理不同的底层逻辑,增加了系统的复杂度,也提高了维护和修改的成本。
通过引入一个中间层,所有业务模块(如 A、B、C)都只需要与中间层交互,而不需要直接处理底层服务。中间层负责统一管理对内存缓存、Redis 和数据库的访问逻辑。这样,业务模块对底层服务的依赖被中间层隔离,大大简化了系统的依赖结构。
引入中间层的优势
简化依赖关系:模块不再直接依赖底层服务,系统的层次更加分明,模块之间的依赖关系被简化,降低了耦合度。
增强灵活性:由于中间层屏蔽了底层的实现细节,上层模块可以更灵活地与中间层交互。如果底层服务发生变化(例如替换缓存系统),只需要调整中间层,而无需修改所有依赖这些服务的业务模块。
提高可维护性:中间层将复杂的底层逻辑封装在一个独立的模块中,业务模块不需要关心具体的底层实现,减少了系统中各个模块对底层服务的依赖,使得维护和扩展更加容易。
支持逐步重构:引入中间层还可以为系统的重构提供一个过渡手段。开发人员可以逐步迁移系统的依赖,先通过中间层进行适配,然后再逐步替换或修改底层服务,避免一次性的大规模改动。
# 3.3 模块化设计
模块化 是构建复杂系统的常用手段。模块化的目标是将系统拆分为多个独立的、自治的模块,每个模块负责处理特定的功能。这不仅能减少系统的复杂度,还能提升团队协作效率和系统的可维护性。
模块化设计使得开发者可以独立开发、测试、修改某个模块,而不会影响到其他模块。每个模块通过明确的接口进行通信,减少了模块之间的紧密耦合。
示例:模块化设计
public class UserModule {
public void createUser(String name) {
// 创建用户的逻辑
}
}
public class OrderModule {
public void createOrder(String userId) {
// 创建订单的逻辑
}
}
2
3
4
5
6
7
8
9
10
11
在这个例子中,用户模块和订单模块是相互独立的。通过这种模块化设计,用户和订单的功能可以独立开发和维护,减少了相互依赖的风险。
# 3.4 依赖注入
依赖注入(Dependency Injection, DI) 是一种通过将模块的依赖关系动态注入到类中来实现解耦的设计模式。通过依赖注入,模块不再直接依赖具体实现,而是通过外部注入依赖,从而降低模块之间的耦合度。
依赖注入常与接口结合使用,使得模块可以动态切换依赖的实现,而不需要修改模块本身的代码。
示例:依赖注入
public class OrderService {
private final PaymentProcessor paymentProcessor;
public OrderService(PaymentProcessor paymentProcessor) {
this.paymentProcessor = paymentProcessor;
}
public void createOrder(double amount) {
paymentProcessor.processPayment(amount);
}
}
2
3
4
5
6
7
8
9
10
11
在这个例子中,OrderService 依赖 PaymentProcessor 接口,但具体的支付处理器是在运行时通过依赖注入提供的。这样,OrderService 可以根据需求灵活地切换不同的支付处理器,而不需要修改 OrderService 的代码。
# 3.5 常见的设计原则与模式
除了上面提到的封装、抽象和模块化,许多经典的设计原则和设计模式也可以用于解耦代码:
- 单一职责原则(SRP):一个类应该只有一个职责,从而减少模块之间的相互依赖。
- 基于接口而非实现编程:通过依赖抽象接口,而非具体实现,来实现代码的松耦合。
- 多用组合少用继承:继承会导致类之间的强耦合,组合通过松散的对象关系实现灵活的功能扩展。
- 迪米特法则(最少知识原则):模块之间只应该有必要的通信,尽量减少不必要的依赖关系。
- 观察者模式:通过事件通知机制,解耦发布者和订阅者之间的关系。
# 4. 代码复用
无论是开发哪种软件产品,成本和时间都是最重要的。较少的开发时间意味着可以比竞争对手更早进入市场。较低的开发成本意味着能够留出更多的营销资金,覆盖更广泛的潜在客户。
其中,代码复用是减少开发成本最常用的方式之一,其目的非常明显,即:与其反复从头开发,不如在新对象中重用已有的代码。
这个想法表面看起来很棒,但实际上要让已有的代码在全新的代码中工作,还是需要付出额外努力的。组件间紧密的耦合、对具体类而非接口的依赖和硬编码的行为都会降低代码的灵活性,使得复用这些代码变得更加困难。
使用设计模式是增加软件组件灵活性并使其易于复用的方式之一。但是,这可能也会让组件变得更加复杂。
一般情况下,复用可以分为三个层次。在最底层,可以复用类、类库、容器,也许还有一些类的「团体(例如容器和迭代器)」。
框架位于最高层。它们能帮助你精简自己的设计,可以明确解决问题所需的抽象概念,然后用类来表示这些概念并定义其关系。例如,JUnit 是一个小型框架,也是框架的 Hello, world,其中定义了 Test、TestCase 和 TestSuite 这几个类及其关系。框架通常比单个类的颗粒度要大。你可以通过在某处构建子类来与框架建立联系。这些子类信奉「别给我们打电话,我们会给你打电话的。」
还有一个中间层次。这是我觉得设计模式所处的位置。设计模式比框架更小且更抽象。它们实际上是对一组类的关系及其互动方式的描述。当你从类转向模式,并最终到达框架的过程中,复用程度会不断增加。
中间层次的优点在于模式提供的复用方式要比框架的风险小。创建框架是一项投入重大且风险很高的工作,模式则能让你独立于具体代码来复用设计思想和理念。
# 4. 扩展性
需求变化是程序员生命中唯一不变的事情。比如以下几种场景:
- 你在 Windows 平台上发布了一款游戏,现在人们想要 Mac OS 的版本
- 你创建了一个使用方形按钮的 GUI 框架,但几个月后开始流行原型按钮
- 你设计了一款优秀的电子商务网站,但仅仅几个月后,客户就要求新增电话订单的功能
每个软件开发者都经历过许多相似的故事,导致它们发生的原因也不少。
首先,在完成了第一版的程序后,我们就应该做好了从头开始优化重写代码的准备,因为现在你已经能在很多方面更好的理解问题了,同时在专业水平上也有所提高,所以之前的代码现在看上去可能会显得很糟糕。
其次,可能是在你掌控之外的某些事情发生了变化,这也是导致许多开发团队转变最初想法的原因。比如,每位在网络应用中使用 Flash 的开发者都必须重新开发或移植代码,因为不断地有浏览器停止对 Flash 格式地支持。
最后,可能是需求的改变,之前你的客户对当前版本的程序感到满意,但是现在希望对程序进行 11 个「小小」的改动,使其可完成原始计划阶段中完全没有提到的功能,新增或改变功能。
当然这也有好的一面,如果有人要求你对程序进行修改,至少说明还有人关心它。因此在设计程序架构时,有经验的开发者都会尽量选择支持未来任何可能变更的方式。