 ElasticSearch - 映射操作
ElasticSearch - 映射操作
# ElasticSearch - 映射基本操作
映射(Mapping)是定义 Elasticsearch 中索引字段及其属性的过程,类似于关系型数据库中的表结构定义。通过映射,用户可以指定字段的数据类型、索引方式、分词规则等,这对于优化数据存储和提高查询性能非常重要。Elasticsearch 的灵活映射功能可以帮助用户根据不同的应用场景进行高效的数据管理和搜索。
# 1. 映射的基本原理
映射(Mapping)在 Elasticsearch 中用于描述索引中文档的字段类型及其属性,类似于关系型数据库中表的定义。它通过预定义的规则告诉 Elasticsearch 如何存储和索引每个字段。
# 映射的作用
映射主要用于以下几个方面:
字段类型定义:指定每个字段的类型,如
text、keyword、integer、date等。字段类型决定了数据的存储方式和查询方法。索引选项:定义字段是否需要索引。如果字段被索引,用户可以基于该字段进行查询;如果不被索引,则无法基于该字段进行搜索。
分词控制:对于
text类型的字段,映射可以指定分词器,用于将文本数据分解为可查询的词组。这对于全文搜索非常有用。存储优化:映射可以指定是否将某些字段独立存储,以提升查询速度,尽管这可能会增加存储开销。
# 映射的组成
字段类型:定义字段的数据类型,如
text(文本)、keyword(关键字)、long(长整型)、date(日期型)等。索引选项:指定字段是否参与索引,如
index: true表示字段可被索引,index: false表示字段不参与索引。分词器:指定如何对
text类型字段进行分词,常见分词器包括standard、whitespace、ik_max_word等。存储选项:字段可以通过
store: true实现独立存储,提升查询速度,但会增加存储开销。
# 2. 创建映射(PUT 请求)
映射可以通过 PUT 请求创建,在创建索引时指定字段类型及其属性,以优化存储和查询性能。
# Postman 操作:创建映射
操作目的:为 student 索引创建映射,定义 name、sex 和 age 三个字段的类型及其属性。
- 请求 URL:
http://127.0.0.1:9200/student/_mapping - 请求方法:
PUT
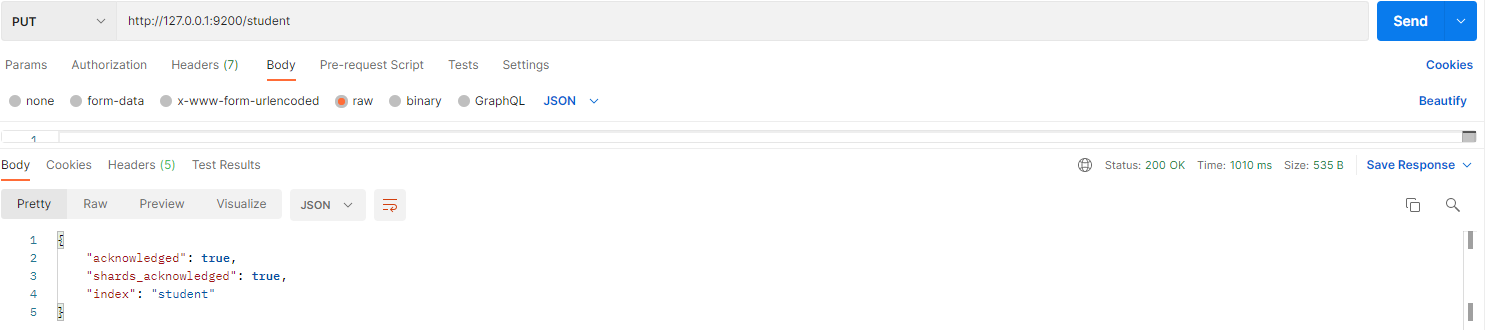
# 第一步:创建 student 索引
在设置映射之前,首先要创建 student 索引:
- 请求 URL:
http://127.0.0.1:9200/student - 请求方法:
PUT
创建索引成功后的截图如下:
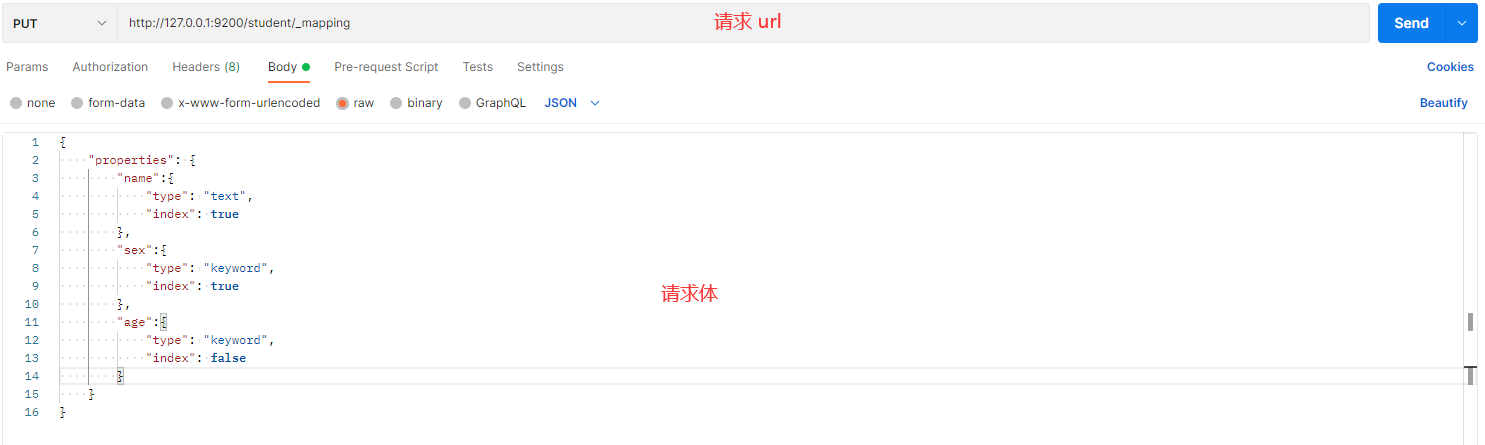
# 第二步:为 student 索引添加映射
请求体内容:
{
"properties": {
"name": {
"type": "text", // 定义字段类型为 text,适合存储大段文本,可进行分词
"index": true // 该字段将被索引,支持模糊搜索和全文检索
},
"sex": {
"type": "keyword", // 定义字段类型为 keyword,不进行分词,适合精确匹配
"index": true // 该字段将被索引,允许基于性别进行搜索
},
"age": {
"type": "integer", // 定义字段类型为 integer,存储整数类型
"index": false // 该字段不参与索引,无法基于年龄进行搜索
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
发送请求的操作截图如下:
# 映射字段详细说明
name 字段:
- type: text:定义为
text类型,适合存储大段文本内容,允许分词。分词后,Elasticsearch 可以根据文本内容的部分进行模糊查询或全文检索。 - index: true:开启索引,允许基于
name字段进行搜索。
- type: text:定义为
sex 字段:
- type: keyword:定义为
keyword类型,不进行分词。适用于固定枚举值(如性别、状态码等)的精确匹配查询。 - index: true:开启索引,允许基于
sex字段进行搜索或聚合操作。
- type: keyword:定义为
age 字段:
- type: integer:定义为整数类型,适合存储年龄等数值字段。
- index: false:该字段不被索引,不能基于该字段进行搜索。
# 字段属性详细说明
type:定义字段的数据类型。常见类型包括:
text:用于存储大段文本内容,支持分词和全文搜索。keyword:用于存储不需要分词的文本,适合精确匹配。integer、long、double:数值类型,分别对应不同大小的整数和浮点数。date:日期类型,支持日期格式存储。
index:决定字段是否参与索引。
true:字段被索引,允许基于该字段进行搜索。false:字段不被索引,不能基于该字段搜索。
analyzer:指定分词器,用于对
text字段进行分词。常用分词器包括:standard:标准分词器,将文本按空格、标点符号等拆分。whitespace:基于空格分词。ik_max_word:中文分词器,能识别中文短语并进行分词。
# Kibana 操作:创建映射
在 Kibana 中,可以通过以下命令为索引添加映射:
PUT /student/_mapping
{
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "keyword",
"index": true
},
"age": {
"type": "integer",
"index": false
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3. 查看映射(GET 请求)
可以通过 GET 请求查看已创建的映射,以了解索引的字段结构及其属性。
# Postman 操作:查看映射
操作目的:查看 student 索引的映射,了解字段类型及其索引状态。
- 请求 URL:
http://127.0.0.1:9200/student/_mapping - 请求方法:
GET
请求发送后的截图如下:
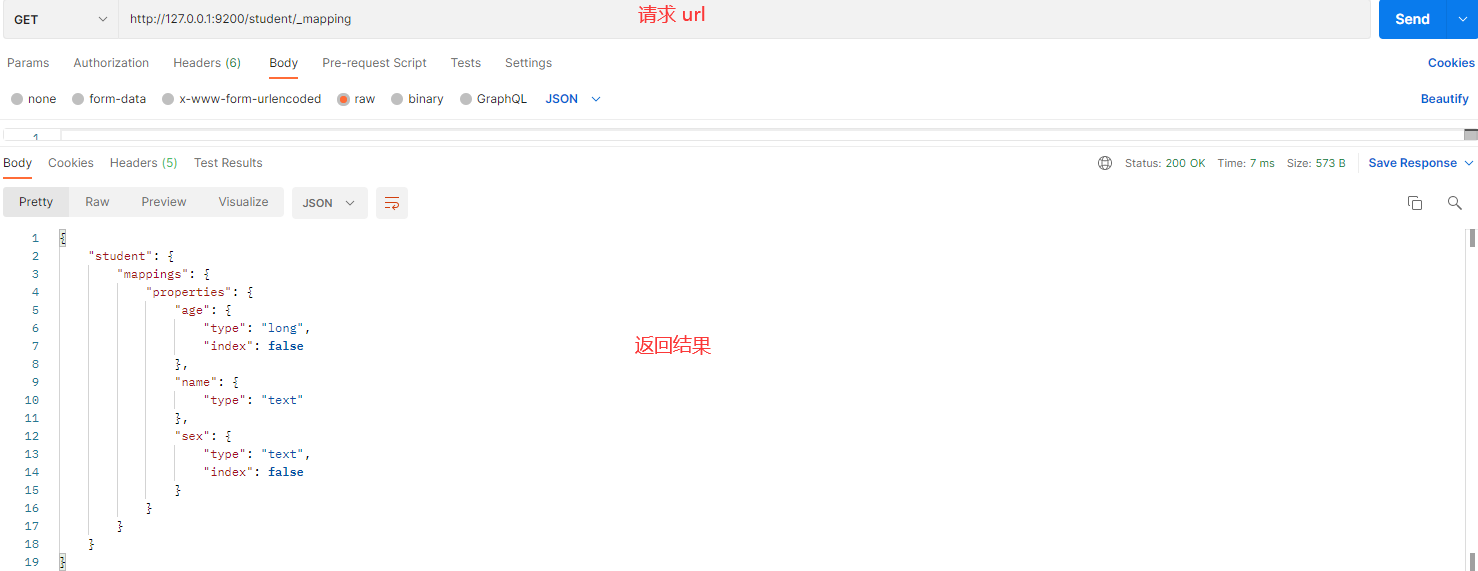
响应内容解释
{
"student": {
"mappings": {
"properties": {
"name": {
"type": "text", // name 字段为文本类型
"index": true // 该字段会被索引
},
"sex": {
"type": "keyword", // sex 字段为 keyword 类型
"index": true // 该字段会被索引
},
"age": {
"type": "integer", // age 字段为整数类型
"index": false // 该字段不会被索引
}
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Kibana 操作:查看映射
在 Kibana 中可以使用以下命令查看索引的映射:
GET /student/_mapping
# 4. 创建带映射的新索引
在创建新索引时,可以直接定义字段的映射,从而使索引创建时就具备优化的数据存储和查询能力。
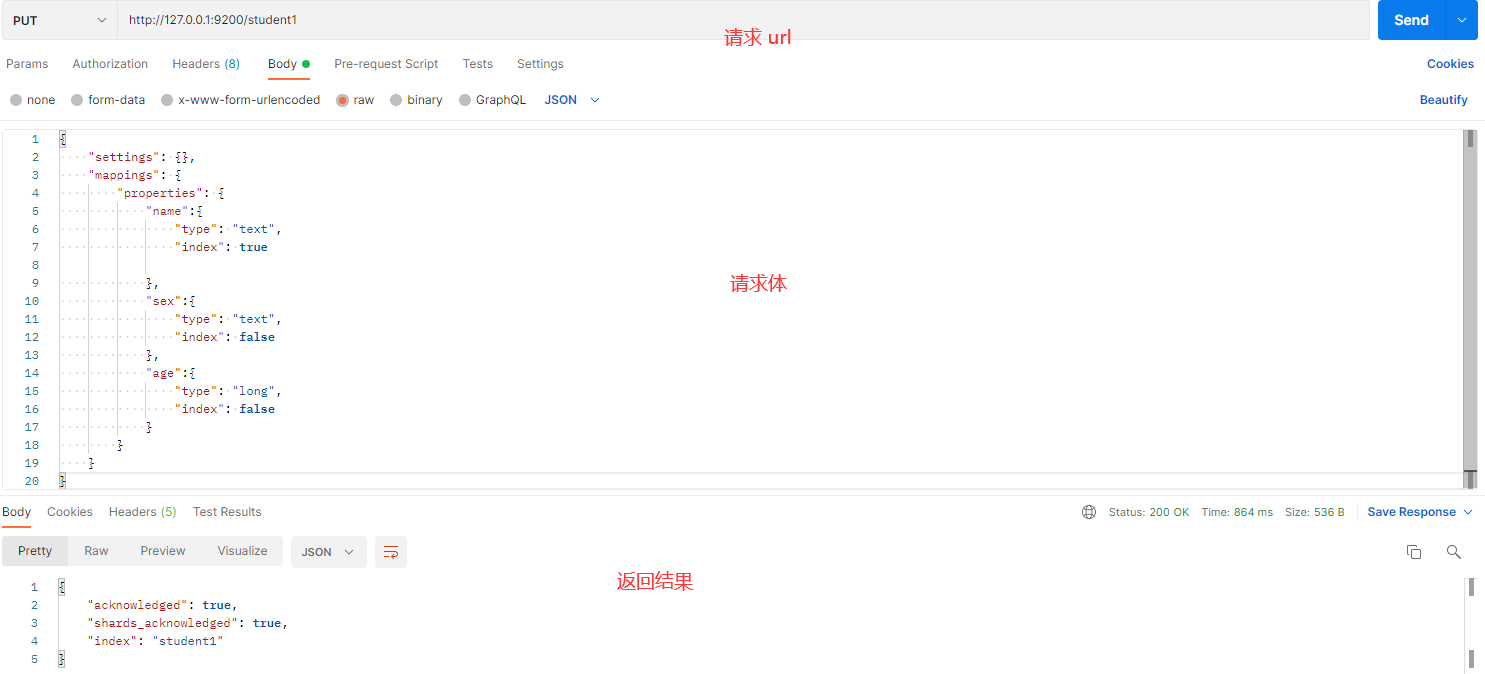
# Postman 操作:创建带映射的新索引
操作目的:创建新索引 student1,并指定 name、sex、age 字段的映射。
- 请求 URL:
http://127.0.0.1:9200/student1 - 请求方法:
PUT
请求体内容
{
"settings": {}, // 索引的配置信息
"mappings": {
"properties": {
"name": {
"
type": "text", // 定义 name 字段为文本类型
"index": true // 该字段会被索引
},
"sex": {
"type": "text", // 定义 sex 字段为文本类型
"index": false // 该字段不会被索引
},
"age": {
"type": "long", // 定义 age 字段为 long 类型
"index": false // 该字段不会被索引
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
发送请求后的截图如下:
# Kibana 操作:创建带映射的新索引
在 Kibana 中可以通过以下命令创建带映射的新索引:
PUT /student1
{
"settings": {},
"mappings": {
"properties": {
"name": {
"type": "text",
"index": true
},
"sex": {
"type": "text",
"index": false
},
"age": {
"type": "long",
"index": false
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# 5. 总结
映射的作用:映射决定了索引中的字段类型、索引方式和存储方式,帮助 Elasticsearch 优化数据存储和检索。
字段类型:
text:适合大段文本,支持分词和全文检索。keyword:用于精确匹配,不进行分词。integer、long:用于数值类型,适合统计和计算。
索引属性:
index: true:字段会被索引,允许搜索。index: false:字段不参与索引,不能基于该字段搜索。
独立存储:可以通过
store: true设置字段为独立存储,提升查询速度,但会增加存储开销。