 ElasticSearch - 倒排索引
ElasticSearch - 倒排索引
# 1. 简单的介绍
倒排索引(Inverted Index)是搜索引擎(包括 Elasticsearch)中用来加速查询的核心数据结构。它将文档中的“词”(关键词)映射到包含这些词的文档列表中。这与我们平时的思维方式相反:我们通常会从一个文档中找到所有的词,而倒排索引是通过一个词来找到所有包含该词的文档。
打个比方:我们平时写的书或文章,通常都会在最后有一个索引页,它列出了每个重要的词,并且告诉我们在哪些页能找到这些词。倒排索引类似于书的索引页,只不过它是专门用于搜索的,效率更高。
# 2. 正排索引 vs 倒排索引
为了更清楚地了解倒排索引,我们先看看什么是正排索引。正排索引是我们通常用来存储文档的方式。它将文档映射到文档内容,比如:
文档1: 我爱编程,编程很有趣
文档2: 编程使世界更美好
文档3: 我爱学习,学习让人进步
2
3
如果你想知道“编程”这个词在哪些文档中出现,你需要一个个文档去扫描,找到哪些文档中包含这个词。这就是正排索引的工作方式,它效率较低,因为查询时需要依次检查所有文档。
而倒排索引则相反。它记录了词和文档的关系,存储的方式是词到文档的映射:
词项“编程” -> 文档1, 文档2
词项“学习” -> 文档3
词项“有趣” -> 文档1
2
3
这样,当你搜索“编程”时,倒排索引可以立即告诉你“编程”出现在哪些文档中,查询效率非常高。
# 3. 为什么需要倒排索引?
当我们需要在大量的文档中快速找到包含特定词项的文档时,倒排索引的优势就体现出来了。倒排索引通过直接找到词项与文档的关系,避免了对每个文档内容进行扫描,从而使得查询速度非常快。
假设你要在成千上万的文章中找到所有包含“编程”的文章。如果没有倒排索引,你需要逐个检查每篇文章的内容,这样不仅耗时,而且会占用大量资源。而通过倒排索引,你只需要查找“编程”这个词的倒排列表,就可以快速找到哪些文章中包含这个词。
# 4. 倒排索引是怎么工作的?
倒排索引的创建和使用过程大致可以分为三个步骤:
文档分词
每个文档在存储时,都会被分解成一个个独立的词项(Term)。分词器会将文档的文本内容按照空格、标点符号等进行分割。例如,文档“我爱编程,编程很有趣”可能会被分成三个词项:“我爱”、“编程”、“有趣”。构建倒排列表
将这些词项和文档的编号关联起来。对于每个词项,记录下在哪些文档中出现过。例如:- 词项“编程” -> 文档1, 文档2
- 词项“有趣” -> 文档1
查询时的使用
当用户查询某个词项(如“编程”)时,倒排索引立即返回包含该词项的所有文档。这避免了逐一扫描每个文档,大大提升了查询速度。
# 5. 举个详细的例子
假设我们有以下三个文档:
- 文档1:
我爱编程 - 文档2:
编程很有趣 - 文档3:
编程使世界更美好
# 1. 文档分词
在这一步,Elasticsearch 会对每个文档的文本进行分词。例如:
- 文档1 -> 词项:“我爱”、“编程”
- 文档2 -> 词项:“编程”、“有趣”
- 文档3 -> 词项:“编程”、“世界”、“美好”
# 2. 构建倒排索引
接下来,Elasticsearch 会为每个词项构建一个倒排列表,记录哪些文档中包含了这个词项。得到的倒排索引可能如下所示:
| 词项 | 出现的文档 |
|---|---|
| 我爱 | 文档1 |
| 编程 | 文档1, 文档2, 文档3 |
| 有趣 | 文档2 |
| 世界 | 文档3 |
| 美好 | 文档3 |
在这个表中,你可以看到每个词项对应的文档。例如,词项“编程”出现在文档1、文档2和文档3中。
# 3. 使用倒排索引查询
当用户查询词项“编程”时,倒排索引会直接返回包含“编程”的文档:文档1、文档2、文档3。这一步非常快,因为倒排索引已经提前为每个词项记录了所有相关的文档。
如果用户查询多个词项,比如“编程”和“有趣”,Elasticsearch 还可以通过倒排索引快速返回同时包含这两个词项的文档:文档2。
# 6. 倒排索引的结构
倒排索引是支持高效搜索的核心结构,它由两个主要部分组成:
词典(Dictionary):
词典是倒排索引中的第一部分,记录了索引中所有不同的词项(Term)。每个词项是通过分词器从文档中提取出来的,它类似于一本字典,按字母顺序或其他高效的排序方式存储。例如,词典中可能包含以下词项:“编程”、“有趣”、“美好”、“生活”等。每个词项都指向该词项在文档中的详细信息(即倒排列表)。词典的作用:
- 通过查找词典,可以快速确定某个词是否存在于索引中。
- 词典中每个词项指向该词项的倒排列表。
倒排列表(Posting List):
倒排列表是每个词项对应的文档 ID 列表,记录了该词项在哪些文档中出现。它不仅包含文档 ID,还可以记录该词项在文档中的相关信息,如:- 词项出现的位置(Position):记录该词项在文档中的具体位置,适用于短语查询和位置相关的搜索。
- 词频(Term Frequency, TF):记录词项在每个文档中出现的次数,词频越高,通常表明该文档与查询的相关性越高。
倒排列表的作用:
- 当你搜索某个词时,Elasticsearch 通过词典找到对应的倒排列表,然后遍历该列表以定位包含该词的文档。
- 通过倒排列表中的词频、词项位置等信息,Elasticsearch 可以计算每个文档与查询的相关性,并返回最相关的文档。
# 1. 举例:倒排索引结构
假设有两个文档:
- 文档1:
"我喜欢编程,编程非常有趣" - 文档2:
"编程让生活更美好"
倒排索引的结构可能如下:
词典(Dictionary):
“我”→ 倒排列表“喜欢”→ 倒排列表“编程”→ 倒排列表“非常”→ 倒排列表“有趣”→ 倒排列表“让”→ 倒排列表“生活”→ 倒排列表“美好”→ 倒排列表
倒排列表(Posting List):每个词项对应的文档及其相关信息如下:
| 词项 | 倒排列表 | 词频(TF) | 词项位置(Position) |
|---|---|---|---|
| 我 | 文档1 | 1 | 1 |
| 喜欢 | 文档1 | 1 | 2 |
| 编程 | 文档1, 文档2 | 文档1: 2, 文档2: 1 | 文档1: [3, 6], 文档2: [1] |
| 非常 | 文档1 | 1 | 5 |
| 有趣 | 文档1 | 1 | 7 |
| 让 | 文档2 | 1 | 2 |
| 生活 | 文档2 | 1 | 3 |
| 美好 | 文档2 | 1 | 5 |
详细解释:
- 对于词项“编程”,它在文档1中出现了两次(词频为 2),在文档2中出现了一次(词频为 1)。倒排列表还记录了“编程”在文档中的具体位置,比如在文档1中的第 3 位和第 6 位,以及在文档2中的第 1 位。
- 对于词项“生活”,它只在文档2中出现了一次,词频为 1,出现的位置是第 3 位。
# 2. 词频(TF)在查询中的作用
在查询时,词频(TF)是非常重要的信息。Elasticsearch 使用词频来衡量某个词项在文档中的重要性。通常来说,一个词在文档中出现的次数越多,这个词对该文档的相关性越强。因此,Elasticsearch 会倾向于优先返回包含搜索词项并且词频较高的文档。
# 3. 相关性评分(TF-IDF 和 BM25)
Elasticsearch 通过计算相关性评分(Relevance Score)来确定搜索结果的排序顺序,最常用的相关性计算算法是 BM25,它是对经典的 TF-IDF 算法的改进。下面我们详细说明这两种算法及其如何使用词频。
# 3.1 TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是一种经典的相关性评分算法,它结合了词频(TF) 和 逆文档频率(IDF),计算某个词项在文档中的重要性。基本思想是:
- 词频(TF):词项在某个文档中出现的次数。词频越高,说明该词对这个文档的重要性越大。
- 逆文档频率(IDF):词项在整个文档集合中出现的频率。如果一个词在很多文档中都出现过,那么这个词的区分度较低,重要性也较低。常见词(如“的”、“是”)的 IDF 值会比较低,而较少见的词(如“编程”)的 IDF 值会较高。
TF-IDF 公式:
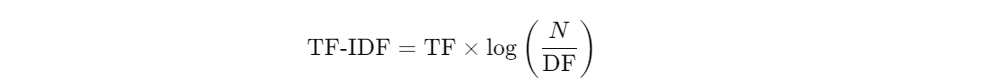
其中:
- TF:词频,表示词项在某个文档中出现的次数。
- N:文档总数。
- DF:文档频率,表示某个词项在多少个文档中出现。
简单总结:如果一个词在某篇文档中频繁出现(高 TF),且在整个文档库中较少出现(高 IDF),那么它对这篇文档的相关性贡献较大。
# 3.2 BM25
BM25 是一种对 TF-IDF 改进的算法,也是 Elasticsearch 默认的相关性评分算法。它更好地处理了词频和文档长度对相关性的影响。BM25 计算相关性的方式类似于 TF-IDF,但在词频和文档长度方面进行了调整,使得算法更加稳定和准确。
BM25 的公式比 TF-IDF 更复杂一些,但核心思想是相似的:词频高且文档长度适中时,文档的相关性得分较高。BM25 还会根据词项的逆文档频率(IDF)来调整分数,使得常见词的权重较低。
# 4. 查询时优先返回词频高的文档
在实际查询时,Elasticsearch 会根据每个词项的词频(TF)来计算文档的相关性分数,并优先返回那些相关性得分较高的文档。例如:
- 如果你搜索“编程”,文档1中“编程”出现了 2 次,而文档2中只出现了 1 次,那么文档1的相关性得分会高于文档2,因此 Elasticsearch 会优先返回文档1。
此外,Elasticsearch 还会综合多个词项的词频,来对查询结果进行排序。例如,如果你搜索“编程 有趣”,文档1中这两个词项都出现过,而文档2中只有“编程”出现过,那么文档1的相关性得分会更高。
# 5. 查询排序的优先级
查询时,Elasticsearch 会根据以下因素对文档进行排序:
- 词频(TF):词在文档中出现的次数越多,文档的相关性得分越高。
- 逆文档频率(IDF):词在整个索引中的出现频率越低,文档的相关性得分越高。也就是说,稀有词比常见词更能提升文档的相关性。
- 文档长度:BM25 会根据文档的长度进行调整。较长的文档可能包含更多词项,因此分数会略微下降。
小结
- 倒排索引不仅记录词项出现的文档,还记录每个词项在文档中的出现次数(词频 TF)。
- 词频(TF)越高的文档,通常会被认为与查询更相关,因此在搜索结果中排名更靠前。
- Elasticsearch 使用的相关性评分算法(如 BM25)综合了词频(TF)和逆文档频率(IDF),确保搜索结果的排序既考虑词项在文档中的频率,又考虑词项在整个索引中的稀有程度。
# 7. 倒排索引的优化
Elasticsearch 不仅使用倒排索引来进行查询,还对其进行了优化:
压缩存储:
倒排索引可能会变得很大,为了节省空间,Elasticsearch 使用了高效的压缩算法来存储这些索引。跳跃表(Skip List):
为了提高查询速度,倒排列表还会使用跳跃表(类似于目录),这样 Elasticsearch 就可以在需要的时候快速跳过不必要的部分,加快查询速度。
# 8. ES 如何使用倒排索引?
在 Elasticsearch 中,当你向它存储文档时,它会为每个文档的 text 类型字段创建倒排索引。当你查询某个词项时,Elasticsearch 会利用倒排索引快速找到包含该词项的文档。
查询流程
文档写入时创建倒排索引
当你将文档添加到 Elasticsearch 中时,它会自动为文档中的词项创建倒排索引。这是一个后台过程,用户不需要手动干预。查询时使用倒排索引
当你查询某个关键词时,Elasticsearch 会通过倒排索引查找所有包含该词项的文档,快速返回结果。倒排索引的效率远远高于逐个扫描文档。
注意在 Elasticsearch 中,并不只有 text 类型的字段才能使用倒排索引,keyword 类型的字段也会使用倒排索引。另外,倒排索引确实是在你索引文档时,自动创建的,无需手动构建。
# 1. 哪些字段使用倒排索引?
text类型的字段:
用于存储需要分词处理的文本数据。text类型的字段会通过分词器将文本分割成一个个词项(Term),然后基于这些词项创建倒排索引。这意味着你可以对text字段进行模糊查询、全文搜索。keyword类型的字段:
用于存储不需要分词的短文本或精确值,比如标签、ID、状态等。keyword类型的字段不会进行分词,而是直接将整个字段的值作为一个词项存入倒排索引。这使得keyword字段适合用于精确匹配、聚合和排序等操作。
举例:
假设你有一个包含以下字段的文档:
{
"name": "Elasticsearch is awesome",
"status": "active"
}
2
3
4
对于
name字段,如果它的类型是text,Elasticsearch 会对该字段的值进行分词,将其拆分成多个词项(如“elasticsearch”、“is”、“awesome”),然后为每个词项创建倒排索引。你可以通过全文搜索查询“awesome”,然后找到这个文档。对于
status字段,如果它的类型是keyword,Elasticsearch 不会分词,而是将整个字段值“active”作为一个词项直接存入倒排索引。你可以通过精确匹配搜索status: "active"来找到这个文档。
# 2. 自动创建倒排索引
在 Elasticsearch 中,当你向某个索引添加文档时,Elasticsearch 会自动为可以进行搜索的字段创建倒排索引,你不需要手动创建或指定。
对于
text字段:
倒排索引会根据分词结果自动创建。例如,如果你向一个text类型的字段中存入“我爱编程”,倒排索引会为“我爱”和“编程”分别建立倒排列表,记录哪些文档中包含这些词项。对于
keyword字段:
整个字段的值会被作为一个词项存入倒排索引。例如,“status: active”会被视为一个完整的词项,而不会分词。
# 3. 其他类型的字段
并不是所有的字段类型都使用倒排索引。倒排索引主要用于能够进行搜索的字段(如 text 和 keyword 字段)。其他一些字段类型可能不会使用倒排索引,取决于其索引方式:
numeric(数值)类型:
如integer、float、double等类型的字段不会使用倒排索引。这些字段使用其他结构(如 BKD 树)来进行数值范围查询和排序。date类型:
日期类型的数据也不使用倒排索引,而是使用专门的时间索引结构。
# 4. 如何控制倒排索引?
你可以通过字段的 index 属性来控制是否为该字段创建倒排索引。默认情况下,index 是 true,意味着 Elasticsearch 会为该字段创建倒排索引,并且该字段可以用于搜索。如果你不希望为某个字段创建倒排索引,可以将 index 设置为 false。
示例:不创建倒排索引
{
"mappings": {
"properties": {
"description": {
"type": "text",
"index": false // 禁止为 description 字段创建倒排索引
}
}
}
}
2
3
4
5
6
7
8
9
10
在这个例子中,description 字段的 index 被设置为 false,因此 Elasticsearch 不会为该字段创建倒排索引,意味着你无法通过该字段进行搜索。
# 9. 为什么倒排索引很重要?
倒排索引是搜索引擎和全文检索系统的基础,没有倒排索引,搜索引擎将无法高效地在大量数据中找到相关的结果。通过倒排索引,Elasticsearch 可以快速处理海量数据,实现近实时的搜索体验。
总结
倒排索引的核心功能:将词项(关键词)与文档列表关联,以加速查询。与传统的正排索引不同,它的查询效率极高,尤其适用于海量文档的搜索场景。
倒排索引的优点:
- 查询速度快:倒排索引可以直接定位包含某个词项的文档,避免了对所有文档的扫描。
- 支持复杂查询:倒排索引不仅支持简单的关键词匹配,还可以支持布尔查询、短语查询等复杂的搜索需求。