 ElasticSearch - 高级操作
ElasticSearch - 高级操作
# 数据准备
进行本内容的高级操作前,先往 ElasticSearch 插入一些数据,进行使用
先把上一个内容的 student 索引删除掉
在 Postman 中,向 ES 服务器发 DELETE 请求:http://127.0.0.1:9200/student
或者在 Kibana 里,向 ES 服务器发请求
DELETE /student
Postman
在 Postman 中,向 ES 服务器发五个 POST 请求:http://127.0.0.1:9200/student/_doc/100x,x分别是1,2,3,4,5,每次请求携带自己的请求体,请求体内容在下方代码块里
Kibana
五个数据分开请求插入
POST /student/_doc/1001
{
"name":"zhangsan",
"nickname":"zhangsan",
"sex":"男",
"age":30
}
POST /student/_doc/1002
{
"name":"lisi",
"nickname":"lisi",
"sex":"男",
"age":20
}
POST /student/_doc/1003
{
"name":"wangwu",
"nickname":"wangwu",
"sex":"女",
"age":40
}
POST /student/_doc/1004
{
"name":"zhangsan1",
"nickname":"zhangsan1",
"sex":"女",
"age":50
}
POST /student/_doc/1005
{
"name":"zhangsan2",
"nickname":"zhangsan2",
"sex":"女",
"age":30
}
POST /student/_doc/1006
{
"name":"zhangsan222",
"nickname":"zhangsan222",
"sex":"女",
"age":30
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# 高级查询
名词解释
分词:存到 ElasticSearch 的字符串数据是分开的单个的字符串,如可乐,在 ElasticSearch 的存储格式是可、乐,即无论查询可还是乐,都可以查询出可乐,类似于数据库的模糊查询。
本内容基本都是对请求体进行配置,也是 ElasticSearch 的语法核心所在。查询都是用 GET 请求。
- 分词查询:使用
match查询,进行模糊匹配,类似 SQL 中的LIKE查询。 - 查询所有文档:使用
match_all查询,返回索引中的所有文档,类似 SQL 中的SELECT *。 - 字段匹配查询:使用
multi_match查询,可以在多个字段中同时匹配值。 - 精确查询:使用
term或terms查询进行精确匹配,类似 SQL 中的=和IN查询。 - 多关键字精确查询:使用
terms查询进行多个值的匹配,类似于 SQL 的IN。 - 指定字段查询:通过
_source控制返回的字段,优化查询结果大小。 - 过滤字段:使用
includes和excludes进一步控制返回字段,提升查询效率。 - 组合查询:使用
bool查询,结合must、must_not和should实现复杂的查询逻辑,类似于 SQL 中的AND、OR、NOT。 - 范围查询:使用
range查询,基于数字或日期的区间筛选文档,支持gt、gte、lt、lte运算符。 - 模糊查询:使用
fuzzy查询,匹配与输入值相似的文档,支持自定义编辑距离。 - 多 ID 查询:使用
ids查询,根据一组文档 ID 获取匹配的文档,类似于 SQL 的IN查询。 - 前缀查询:使用
prefix查询,查找字段值以特定前缀开头的文档,适用于文本字段的前缀匹配。 - 单字段排序:使用
sort对结果按照一个字段进行排序,支持asc(升序)和desc(降序)。 - 多字段排序:在
sort中添加多个字段,按顺序应用排序条件,实现更复杂的排序需求。 - 高亮查询:使用
highlight将查询结果中的匹配部分高亮显示,支持自定义前后标签(如 HTML 标签)。 - 分页查询:使用
from和size实现分页,灵活控制查询结果的返回数量。
# 1. 分词查询
分词查询是 Elasticsearch 中的一个强大功能,它可以将存储的文本分词,然后进行模糊匹配,类似于 SQL 中的 LIKE 查询。
Postman 操作
操作目的:查询 name 字段中包含 zhangsan2 的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match": {
"name": "zhangsan2"
}
}
}
2
3
4
5
6
7
发送请求的截图如下:
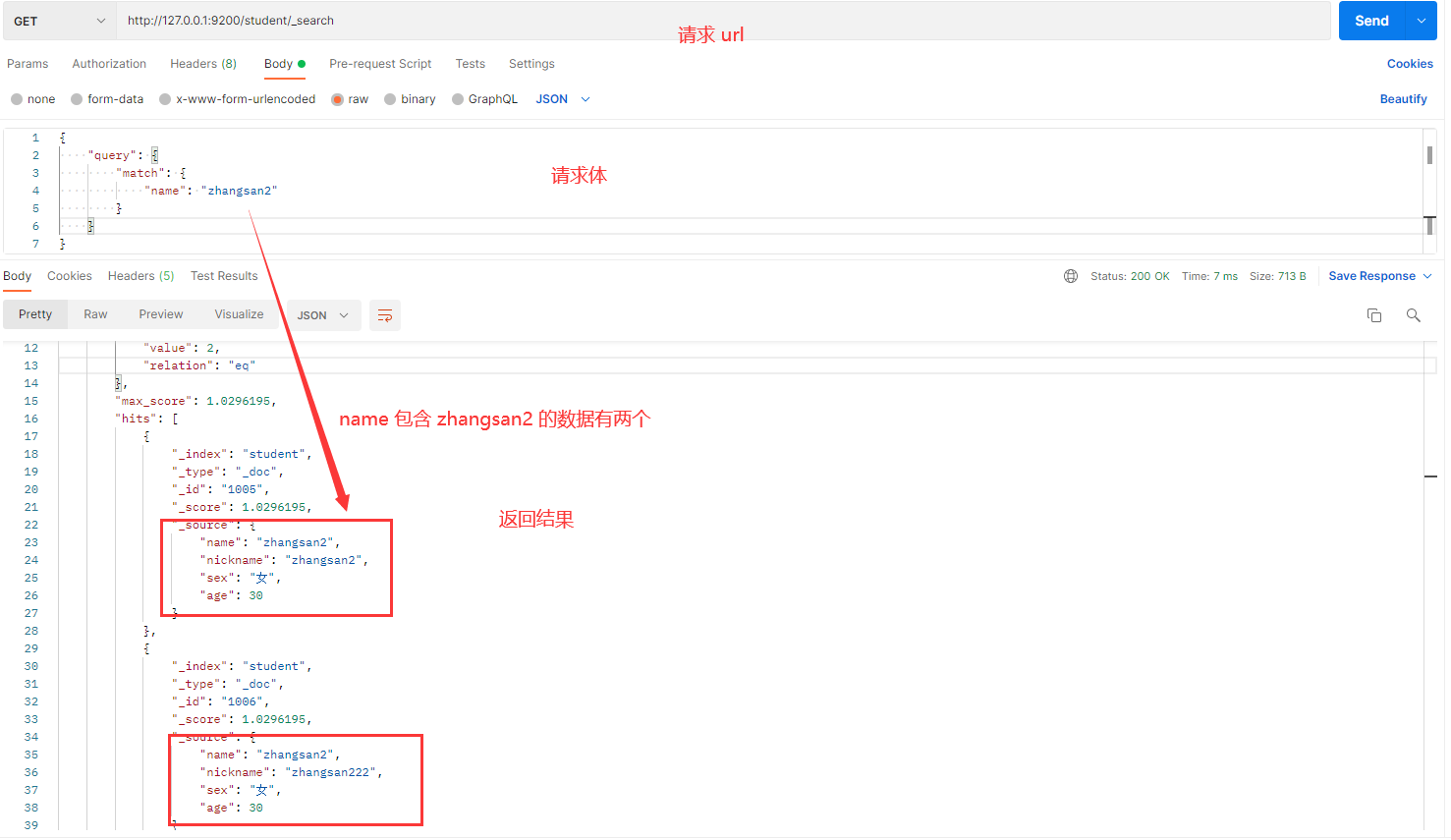
解释:
- match:用于进行分词查询。Elasticsearch 会将字段中的内容进行分词,然后匹配查询条件。
- name:表示查询的字段名。
- zhangsan2:表示要匹配的值。
结果分析:匹配到的 name 字段包含 zhangsan2 或 zhangsan222,因为分词机制可以将 zhangsan222 的前部分与 zhangsan2 匹配。
Kibana 操作
在 Kibana 中执行分词查询的命令如下:
GET /student/_search
{
"query": {
"match": {
"name": "zhangsan2"
}
}
}
2
3
4
5
6
7
8
- 语法说明:
GET /student/_search表示在student索引中进行搜索。match查询会将字段值进行分词并匹配输入值。
# 2. 查询所有文档
match_all 是最简单的查询,类似于 SQL 中的 SELECT *,用于查询索引中的所有文档。
Postman 操作
操作目的:查询 student 索引中的所有文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match_all": {}
}
}
2
3
4
5
发送请求的截图如下:
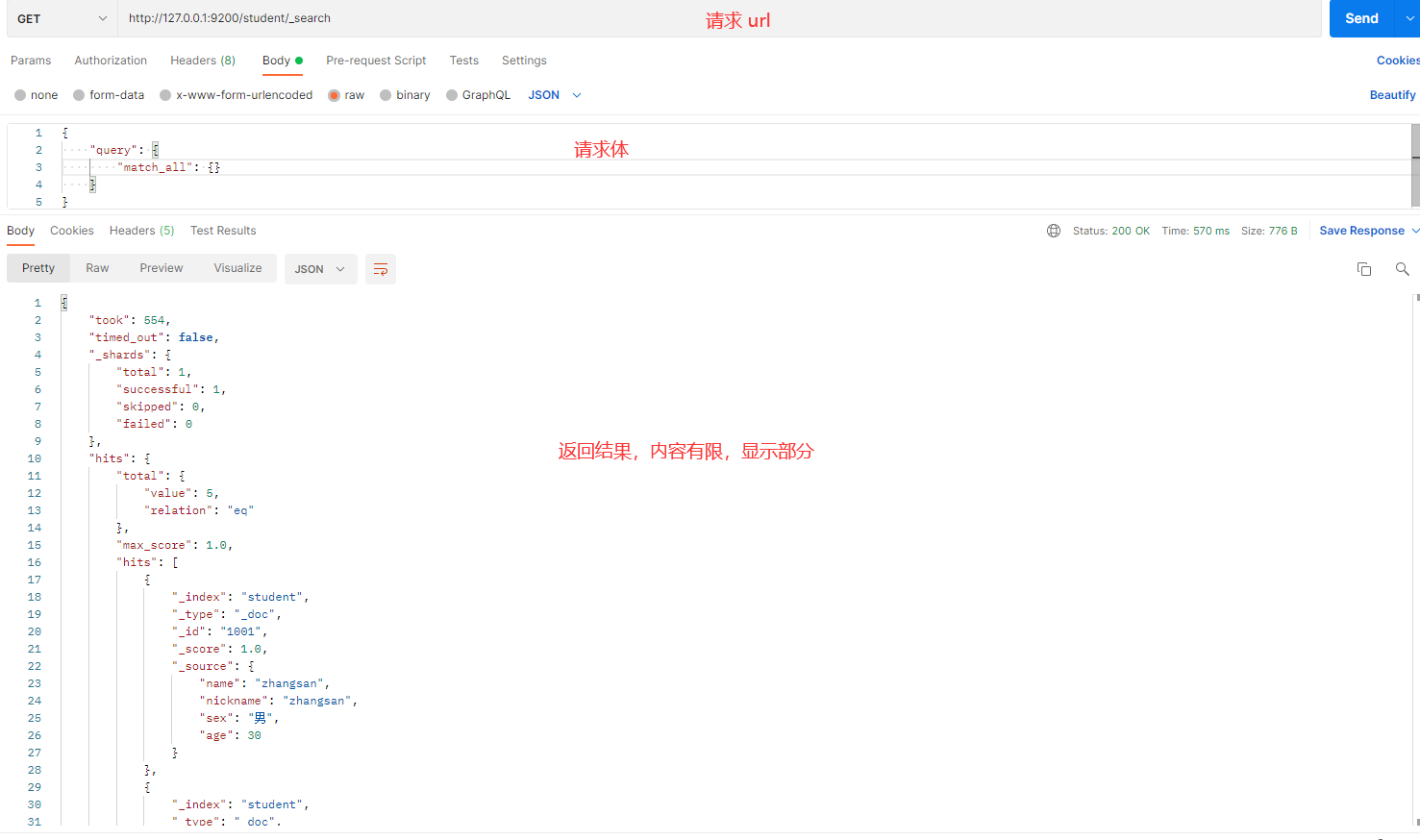
解释:
- match_all:表示查询所有文档。此查询不会进行任何过滤或条件匹配,返回索引中的所有数据。
返回结果说明:
{
"took【查询花费时间,单位毫秒】": 1116,
"timed_out【是否超时】": false,
"_shards【分片信息】": {
"total【总数】": 1,
"successful【成功】": 1,
"skipped【忽略】": 0,
"failed【失败】": 0
},
"hits【搜索命中结果】": {
"total【搜索条件匹配的文档总数】": {
"value【总命中计数的值】":
3,
"relation【计数规则】": "eq"
},
"max_score【匹配度分值】": 1.0,
"hits【命中结果集合】": [
。。。
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- total.value:表示符合条件的文档总数,即所有文档数。
- max_score:表示命中文档的最大匹配分值。
Kibana 操作
在 Kibana 中执行查询所有文档的命令如下:
GET /student/_search
{
"query": {
"match_all": {}
}
}
2
3
4
5
6
- 语法说明:
match_all查询用于检索索引中的所有文档,不带任何过滤条件。
# 3. 字段匹配查询 (multi_match)
multi_match 查询可以在多个字段中进行匹配搜索,类似于 SQL 中的多字段 OR 条件查询。
Postman 操作
操作目的:在 name 和 nickname 字段中匹配 zhangsan 的数据。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name", "nickname"]
}
}
}
2
3
4
5
6
7
8
发送请求的截图如下:
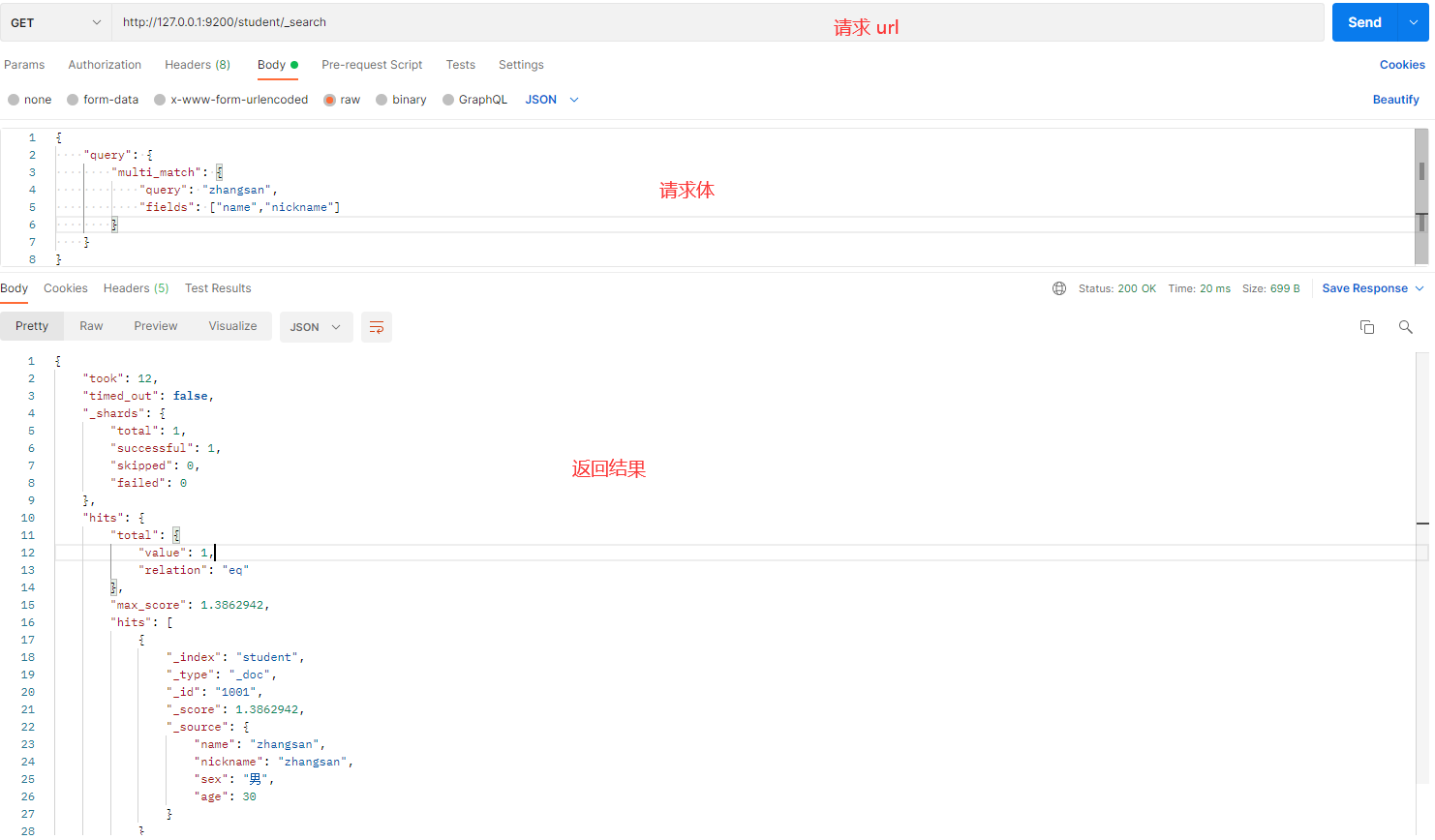
解释:
- multi_match:用于在多个字段中进行匹配查询。
- fields:指定要进行匹配的字段列表,在这里是
name和nickname。 - query:指定查询条件,即匹配
zhangsan。
Kibana 操作
在 Kibana 中执行字段匹配查询的命令如下:
GET /student/_search
{
"query": {
"multi_match": {
"query": "zhangsan",
"fields": ["name", "nickname"]
}
}
}
2
3
4
5
6
7
8
9
- 语法说明:
multi_match查询可以同时在多个字段上匹配指定的值。
# 4. 单关键字精确查询 (term)
term 查询用于精确匹配单个关键字,不进行分词处理,类似于 SQL 中的 = 查询。
Postman 操作
操作目的:精确查询 name 为 zhangsan 的数据。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
发送请求的截图如下:
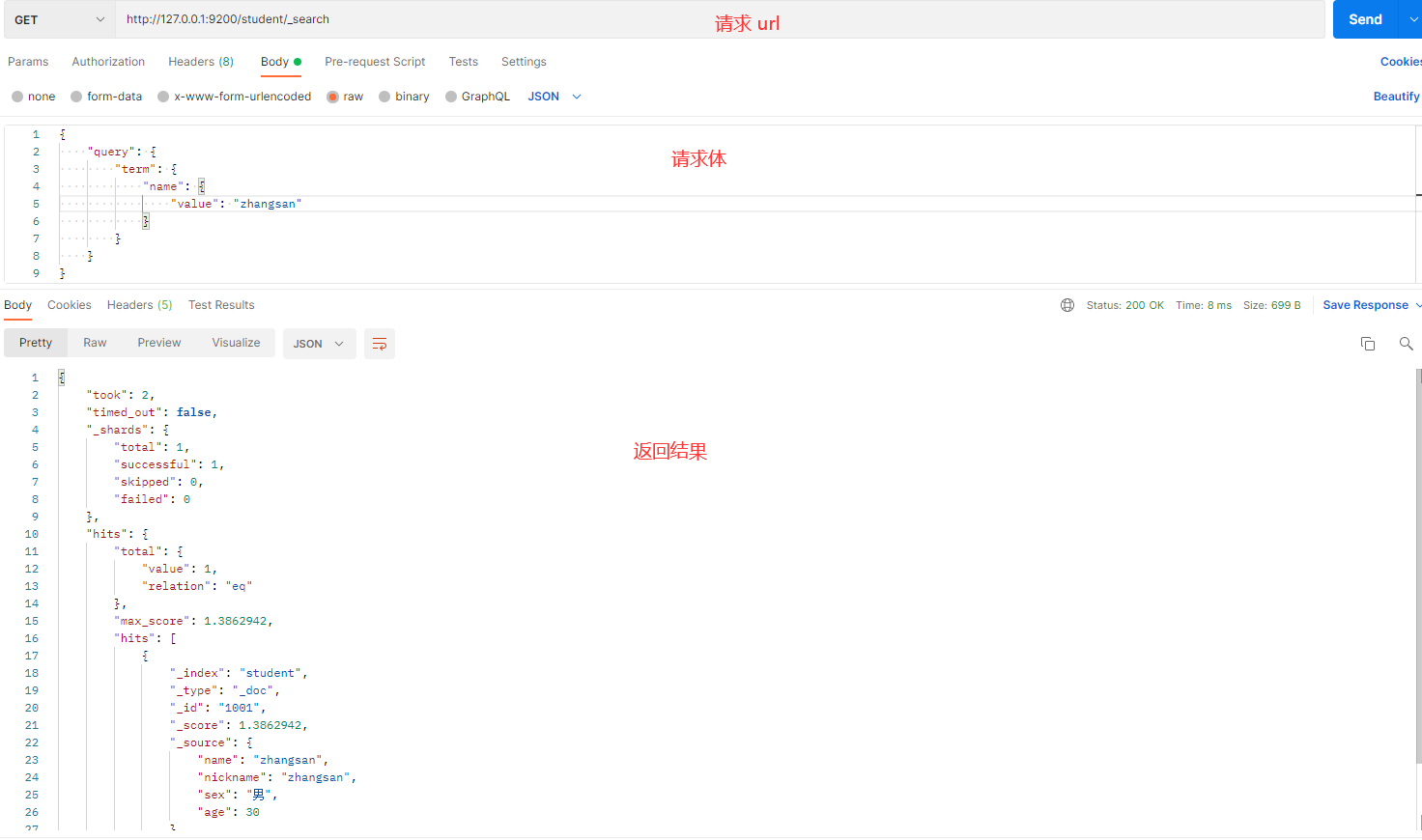
解释:
- term:用于精确匹配查询,查询时不会进行分词。
- name:表示要查询的字段。
- value:表示要匹配的精确值。
Kibana 操作
在 Kibana 中执行精确查询的命令如下:
GET /student/_search
{
"query": {
"term": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
10
- 语法说明:
term查询不会分词,只会匹配完整的字段值。
# 5. 多关键字精确查询 (terms)
terms 查询类似于 SQL 中的 IN 查询,允许匹配多个值中的任意一个。
Postman 操作
操作目的:精确查询 name 为 zhangsan 或 lisi 的数据。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"terms": {
"name": ["zhangsan", "lisi"]
}
}
}
2
3
4
5
6
7
发送请求的截图如下:
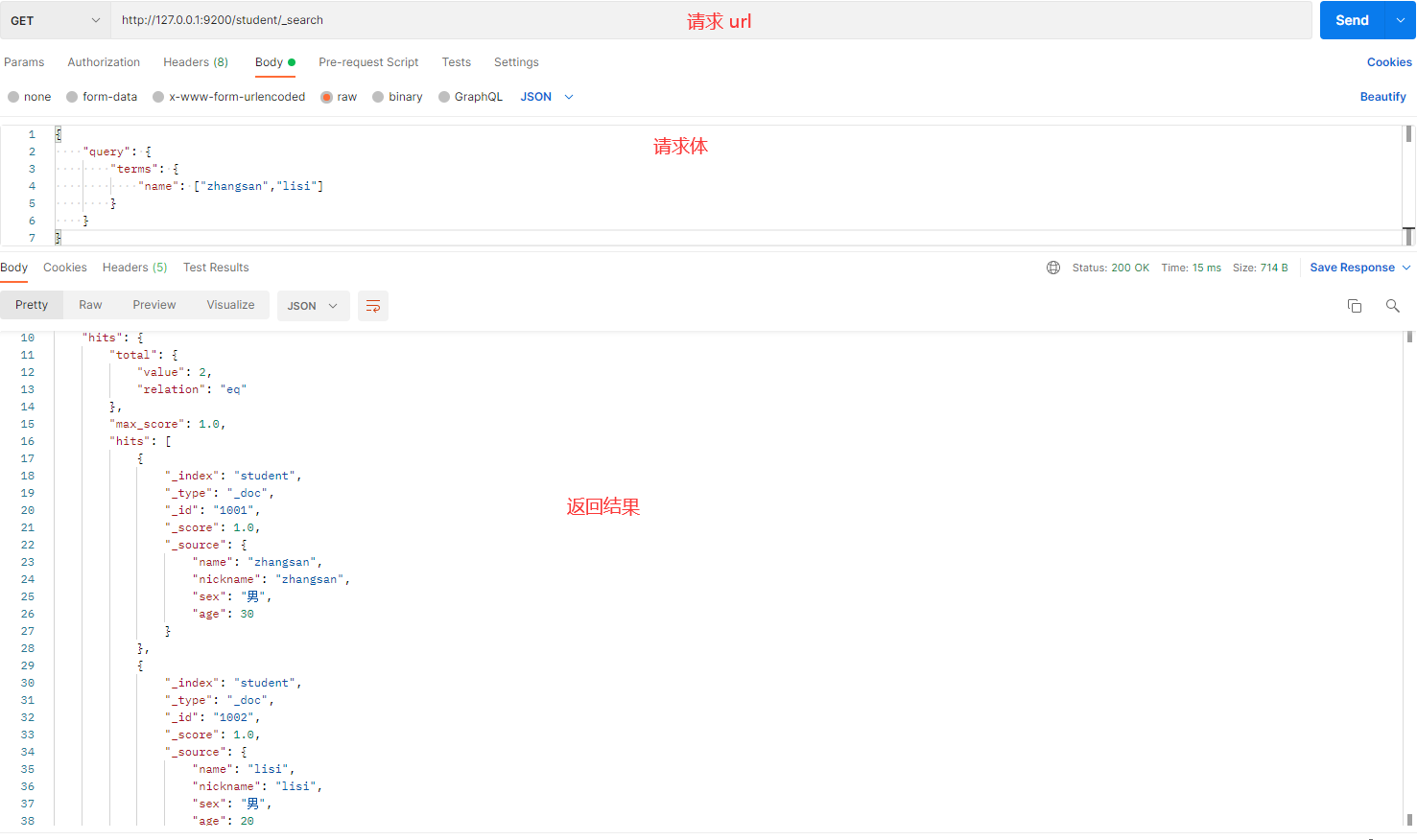
解释:
- terms:用于精确匹配多个值,类似于 SQL 中的
IN查询。 - name:表示要查询的字段。
- ["zhangsan", "lisi"]:表示要匹配的多个值。
Kibana 操作
在 Kibana 中执行多关键字精确查询的命令如下:
GET /student/_search
{
"query": {
"terms": {
"name": ["zhangsan", "lisi"]
}
}
}
2
3
4
5
6
7
8
- 语法说明:
terms查询用于匹配多个值中的任意一个,类似于 SQL 的IN条件。
# 6. 多关键字精确查询 (terms 查询)
terms 查询与 term 查询类似,但允许您指定多个值进行匹配。如果字段中包含任何一个指定值,那么这个文档就满足查询条件。可以类比为 MySQL 中的 IN 查询。
Postman 操作
操作目的:查询 name 字段值为 zhangsan 或 lisi 的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"terms": {
"name": ["zhangsan", "lisi"]
}
}
}
2
3
4
5
6
7
发送请求的截图如下:
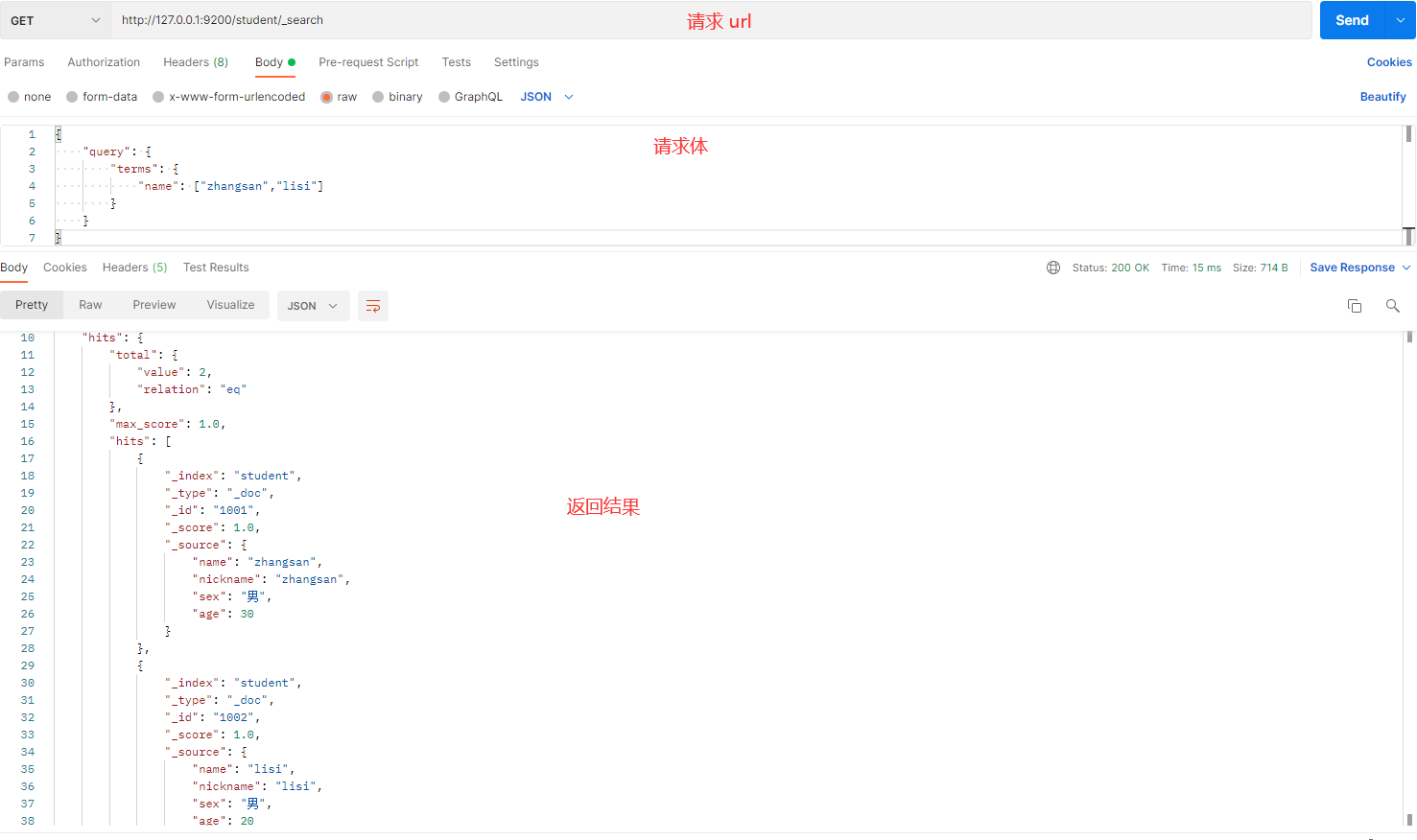
解释:
- terms:用于匹配多个值中的任意一个,类似于 SQL 的
IN查询。 - name:查询字段。
- ["zhangsan", "lisi"]:要匹配的多个值。
Kibana 操作
在 Kibana 中执行多关键字精确查询的命令如下:
GET /student/_search
{
"query": {
"terms": {
"name": ["zhangsan", "lisi"]
}
}
}
2
3
4
5
6
7
8
- 语法说明:
terms查询允许多个值匹配。如果字段包含任意一个指定值,则文档满足条件。
# 7. 指定字段查询
在默认情况下,Elasticsearch 会返回文档中存储的所有字段。如果我们只需要查询并返回特定的字段,可以通过 _source 参数来过滤结果。
Postman 操作
操作目的:只查询并返回 name 和 nickname 字段,匹配 nickname 为 zhangsan 的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"_source": ["name", "nickname"],
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
发送请求的截图如下:
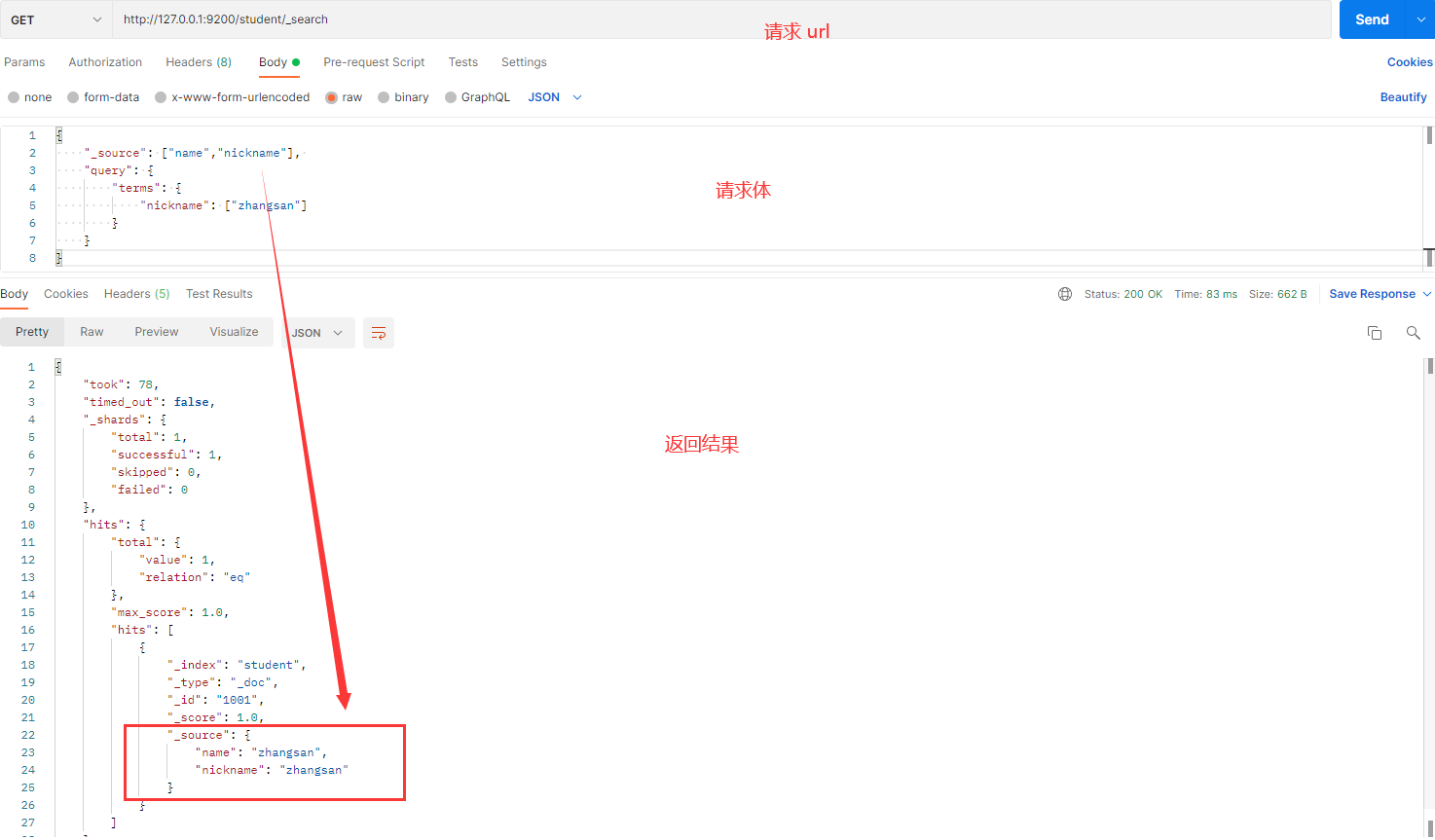
解释:
- _source:指定要返回的字段。在这个例子中,只返回
name和nickname字段。 - terms:查询
nickname为zhangsan的文档。
Kibana 操作
在 Kibana 中执行指定字段查询的命令如下:
GET /student/_search
{
"_source": ["name", "nickname"],
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
9
- 语法说明:通过
_source可以指定只返回的字段。这种查询非常适合需要优化网络传输量或结果集大小的场景。
# 8. 过滤字段
在某些场景下,您可能只想返回部分字段,而忽略其他字段。Elasticsearch 提供了两个参数 includes 和 excludes,用于指定需要显示的字段和不需要显示的字段。
Postman 操作
操作目的:使用 includes 和 excludes 过滤结果中包含或排除特定字段。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
使用 includes
请求体内容:
{
"_source": {
"includes": ["name", "nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
9
10
发送请求的截图如下:
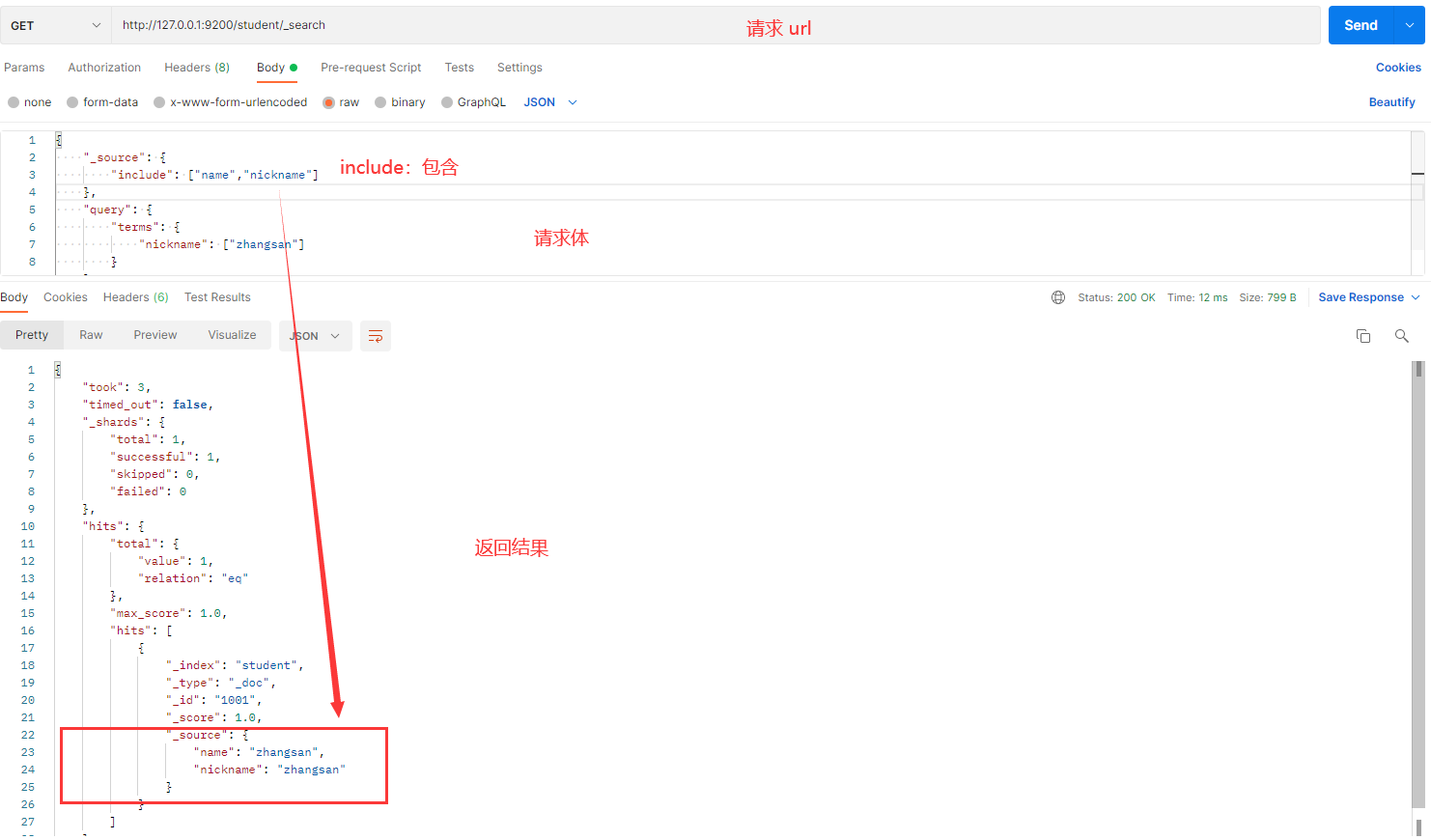
解释:
- includes:指定要返回的字段。在这个例子中,只返回
name和nickname。
使用 excludes
请求体内容:
{
"_source": {
"excludes": ["name", "nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
9
10
发送请求的截图如下:
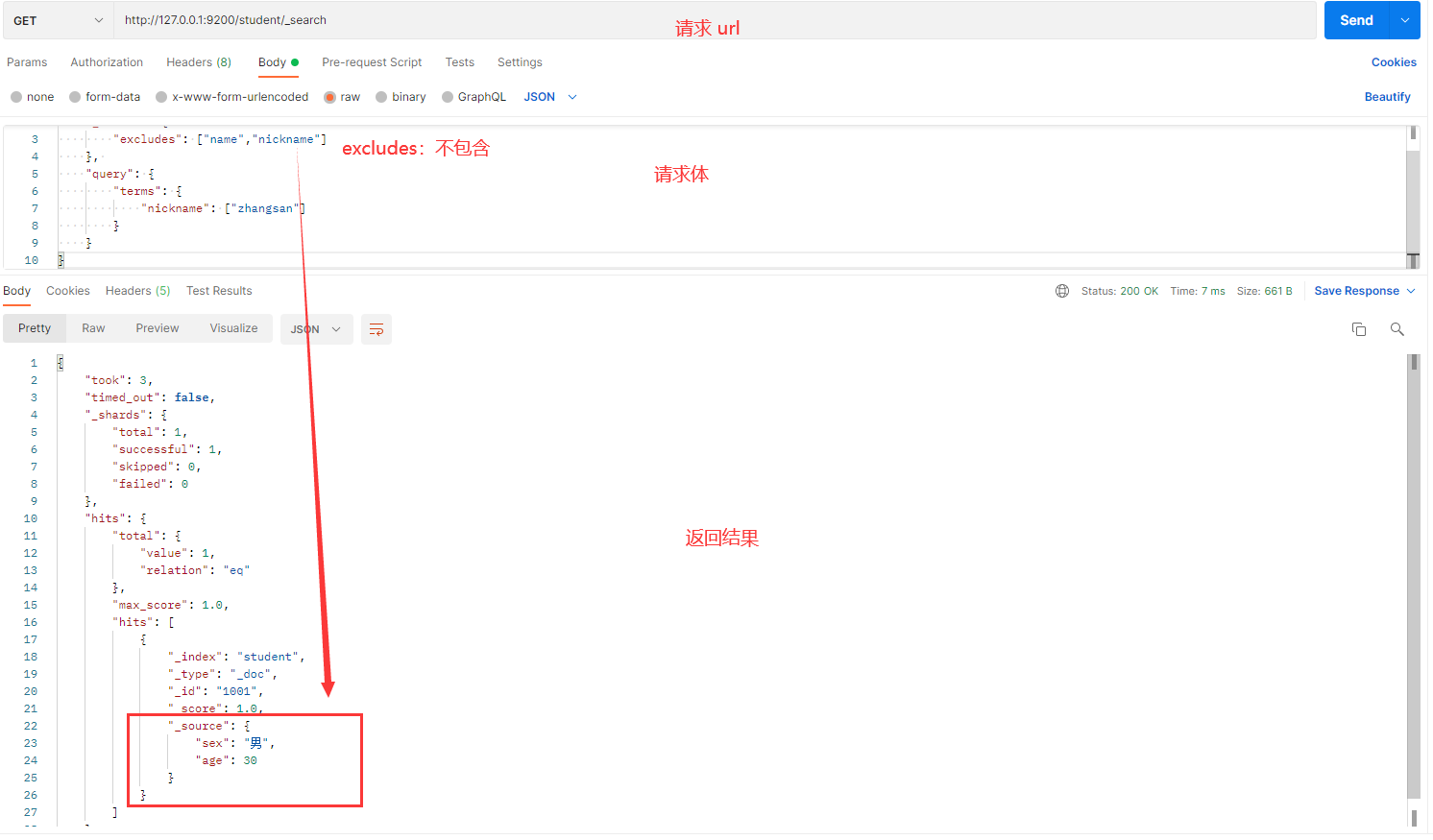
解释:
- excludes:指定不返回的字段。在这个例子中,
name和nickname字段将被排除。
Kibana 操作
使用 includes 和 excludes 过滤字段的命令如下:
GET /student/_search
{
"_source": {
"includes": ["name", "nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
9
10
11
GET /student/_search
{
"_source": {
"excludes": ["name", "nickname"]
},
"query": {
"terms": {
"nickname": ["zhangsan"]
}
}
}
2
3
4
5
6
7
8
9
10
11
- 语法说明:通过
includes和excludes参数,您可以更灵活地控制返回字段的范围,优化查询结果的大小。
# 9. 组合查询 (bool 查询)
Elasticsearch 的 bool查询允许通过 must、must_not 和 should 等子句将多个查询条件组合在一起。它类似于 SQL 中的 AND、OR 和 NOT 逻辑运算。
Postman 操作
操作目的:查询 name 必须为 zhangsan,age 不能为 40,sex 可以是 男。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [
{
"match": {
"age": "40"
}
}
],
"should": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
发送请求的截图如下:
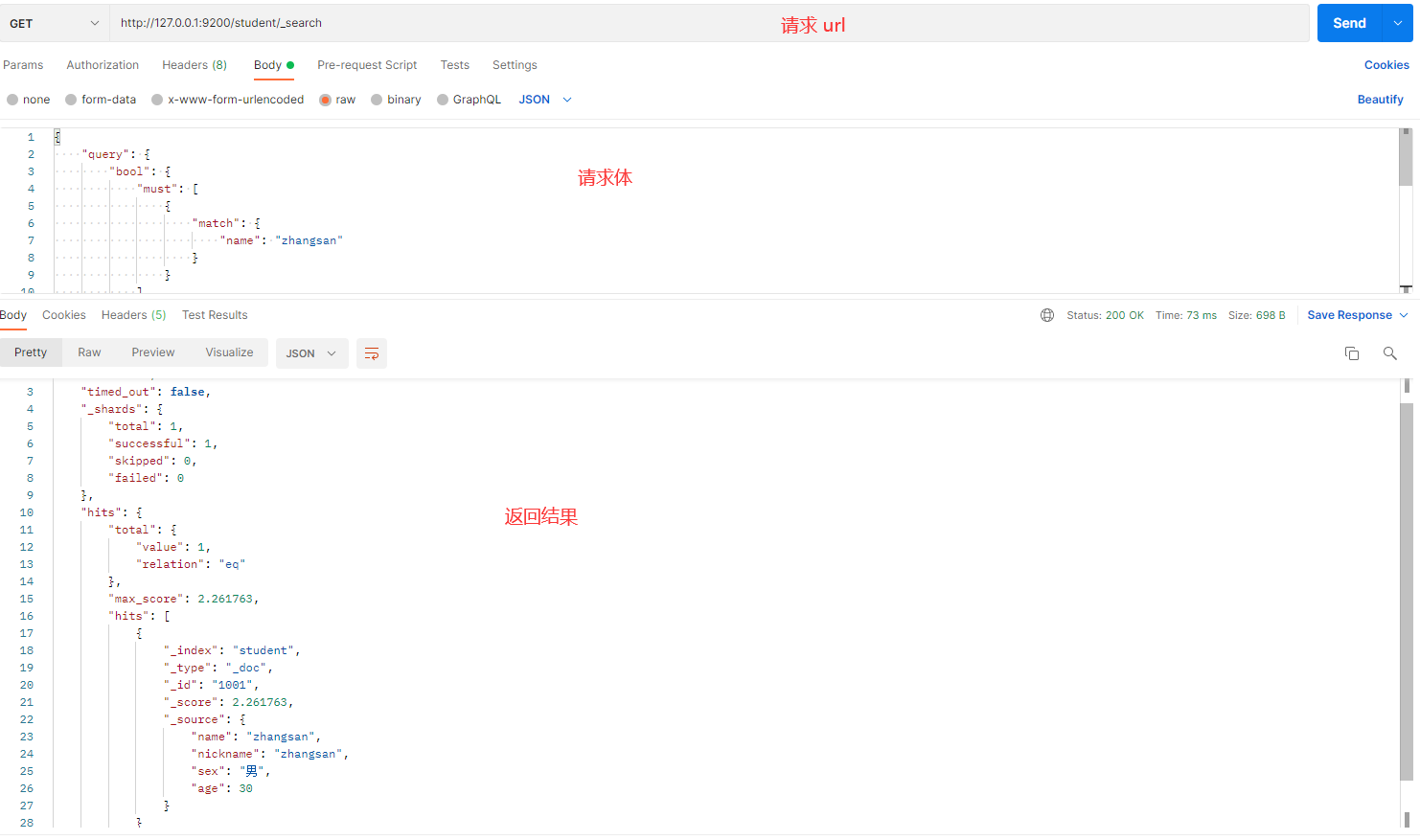
解释:
- bool:用于将多个查询条件组合在一起。
- must:该条件必须满足(类似 SQL 中的
AND)。这里要求name必须为zhangsan。 - must_not:该条件必须不满足(类似 SQL 中的
NOT)。这里要求age不能为 40。 - should:该条件可以满足但不强制(类似 SQL 中的
OR)。这里要求sex可以为男。
Kibana 操作
在 Kibana 中执行组合查询的命令如下:
GET /student/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "zhangsan"
}
}
],
"must_not": [
{
"match": {
"age": "40"
}
}
],
"should": [
{
"match": {
"sex": "男"
}
}
]
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
- 语法说明:
- must:要求匹配的条件。
- must_not:排除匹配的条件。
- should:可选的匹配条件。
# 10. 范围查询 (range 查询)
range 查询允许根据数值或时间的区间进行查询,类似于 SQL 中的比较运算符(如 >, <, >=, <=)。
| 操作符 | 说明 |
|---|---|
| gt | 大于 > |
| gte | 大于等于 >= |
| lt | 小于 < |
| lte | 小于等于 <= |
Postman
Postman 操作
操作目的:查询 age 在 30 到 35 之间的数据。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
2
3
4
5
6
7
8
9
10
发送请求的截图如下:
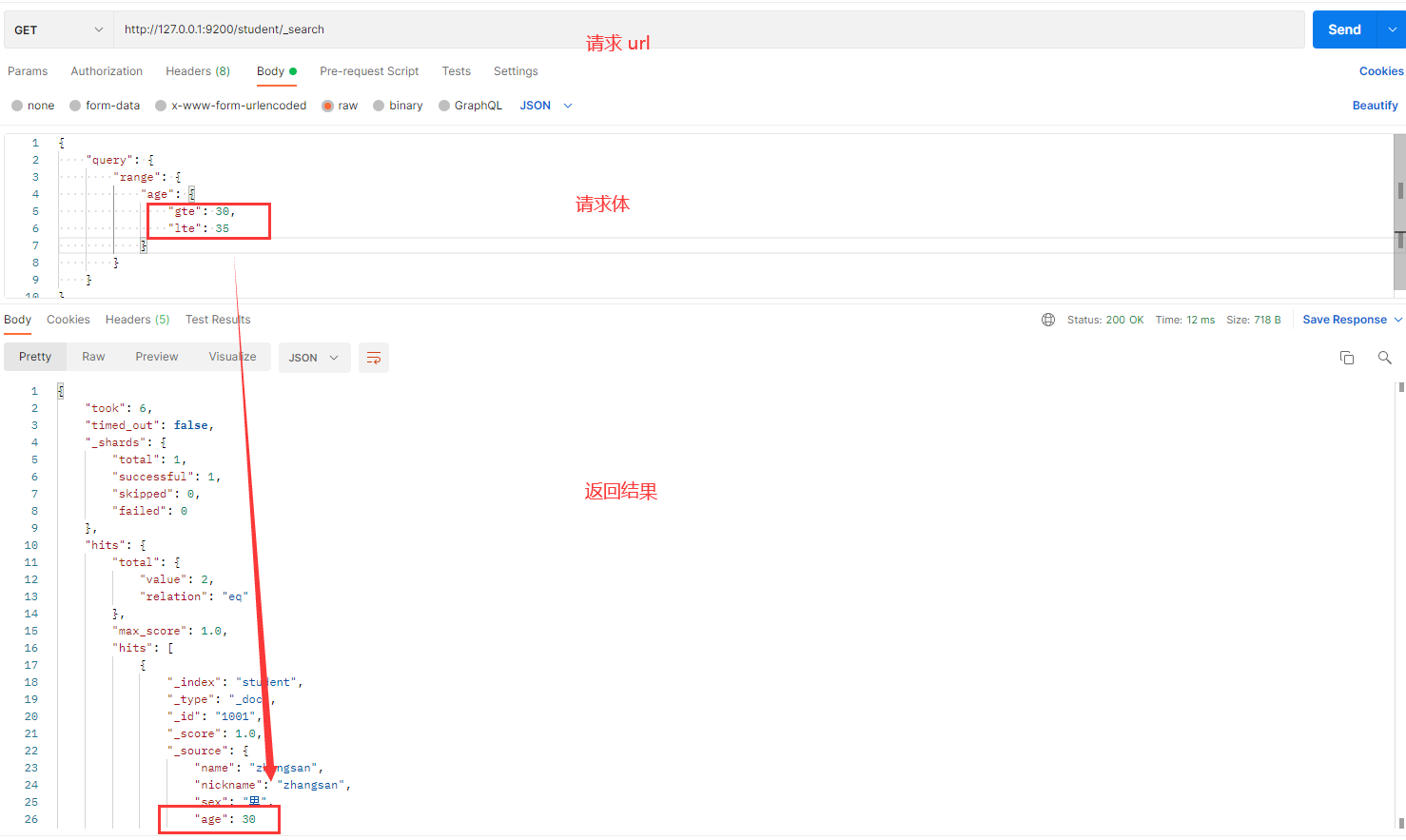
解释:
- range:定义一个范围查询。
- gte:大于等于 30。
- lte:小于等于 35。
Kibana 操作
在 Kibana 中执行范围查询的命令如下:
GET /student/_search
{
"query": {
"range": {
"age": {
"gte": 30,
"lte": 35
}
}
}
}
2
3
4
5
6
7
8
9
10
11
- 语法说明:
- gte:大于等于。
- lte:小于等于。
# 11. 模糊查询 (fuzzy 查询)
模糊查询允许搜索与输入字词相似的文档,类似于 SQL 中的 LIKE。通过 fuzziness 可以调整匹配的编辑距离。
Postman 操作
操作目的:模糊查询 name 字段与 zhangsan 相似的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
示例 1
请求体内容:
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
发送请求的截图如下:
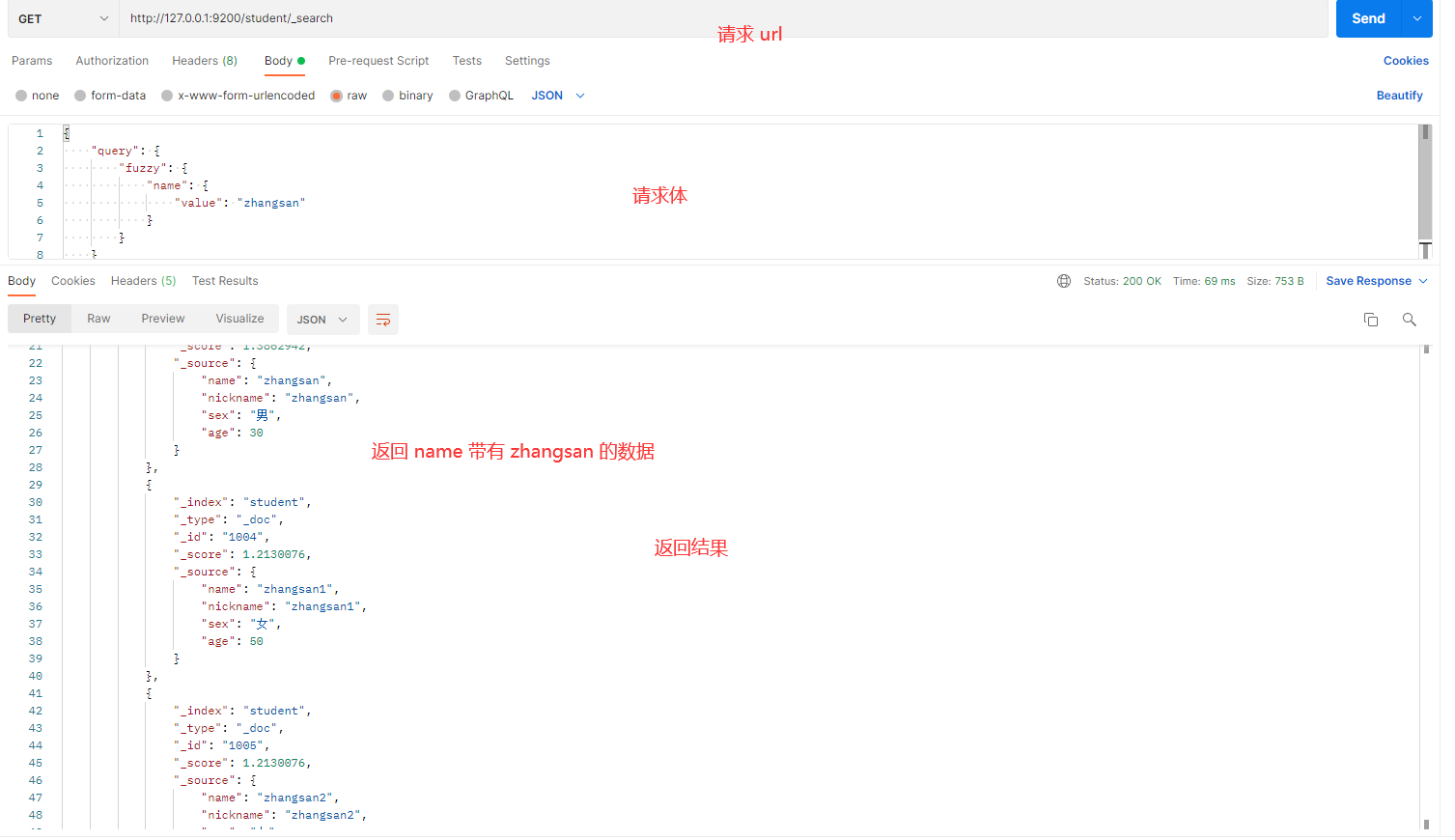
示例 2
请求体内容:
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan",
"fuzziness": 2
}
}
}
}
2
3
4
5
6
7
8
9
10
发送请求的截图如下:
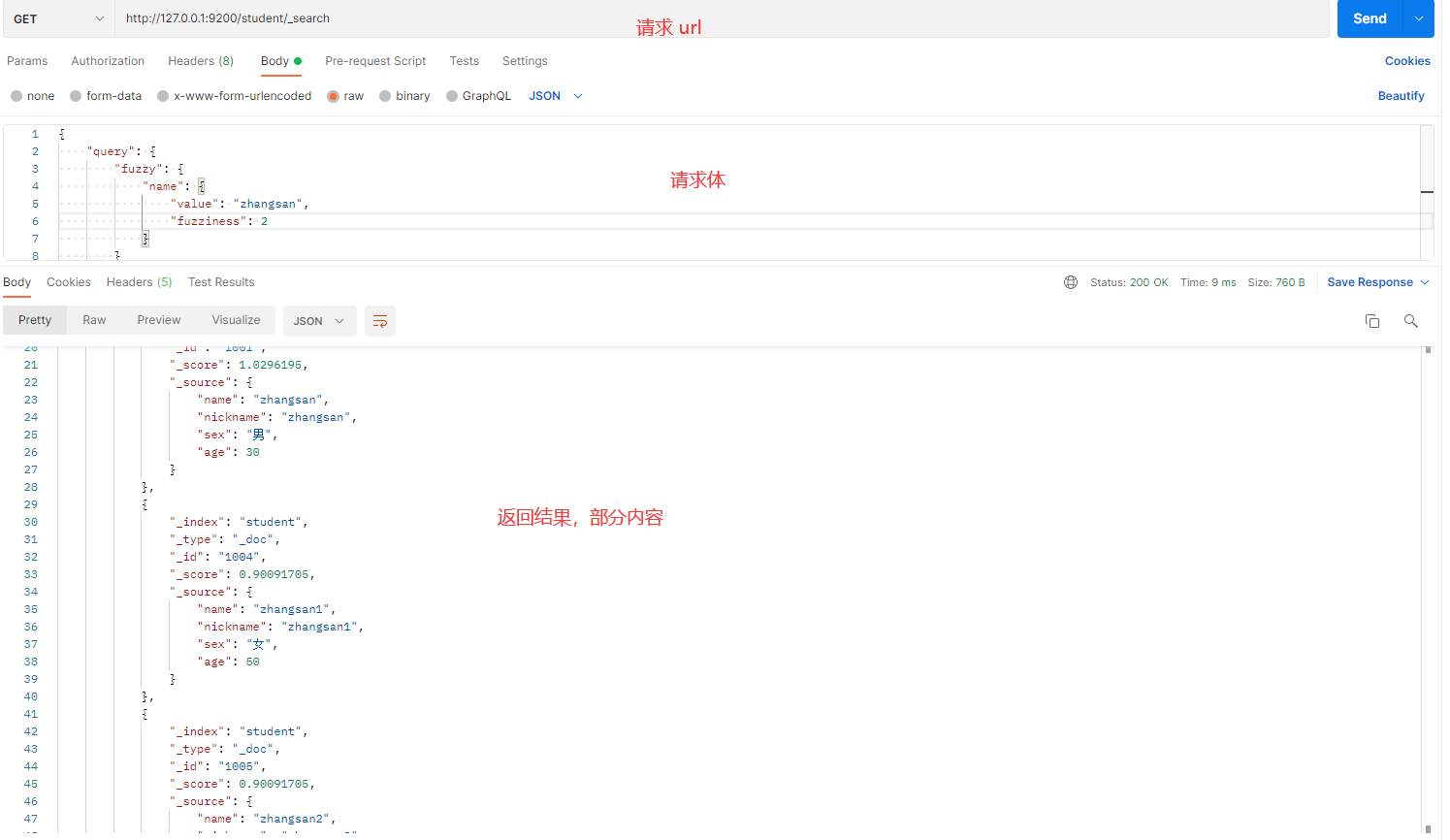
解释:
- fuzzy:用于模糊查询。
- value:要查询的值。
- fuzziness:设置编辑距离,控制允许的最大字符变化。值越大,容忍的错误越多。
Kibana 操作
在 Kibana 中执行模糊查询的命令如下:
GET /student/_search
{
"query": {
"fuzzy": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
10
# 12. 多 IDs 查询
多 IDs 查询用于根据文档 ID 列表查询文档,类似于 SQL 中的 IN 查询。
Postman 操作
操作目的:根据多个文档 ID 查询对应的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"ids": {
"values": ["1001", "1004", "1006"]
}
}
}
2
3
4
5
6
7
发送请求的截图如下:
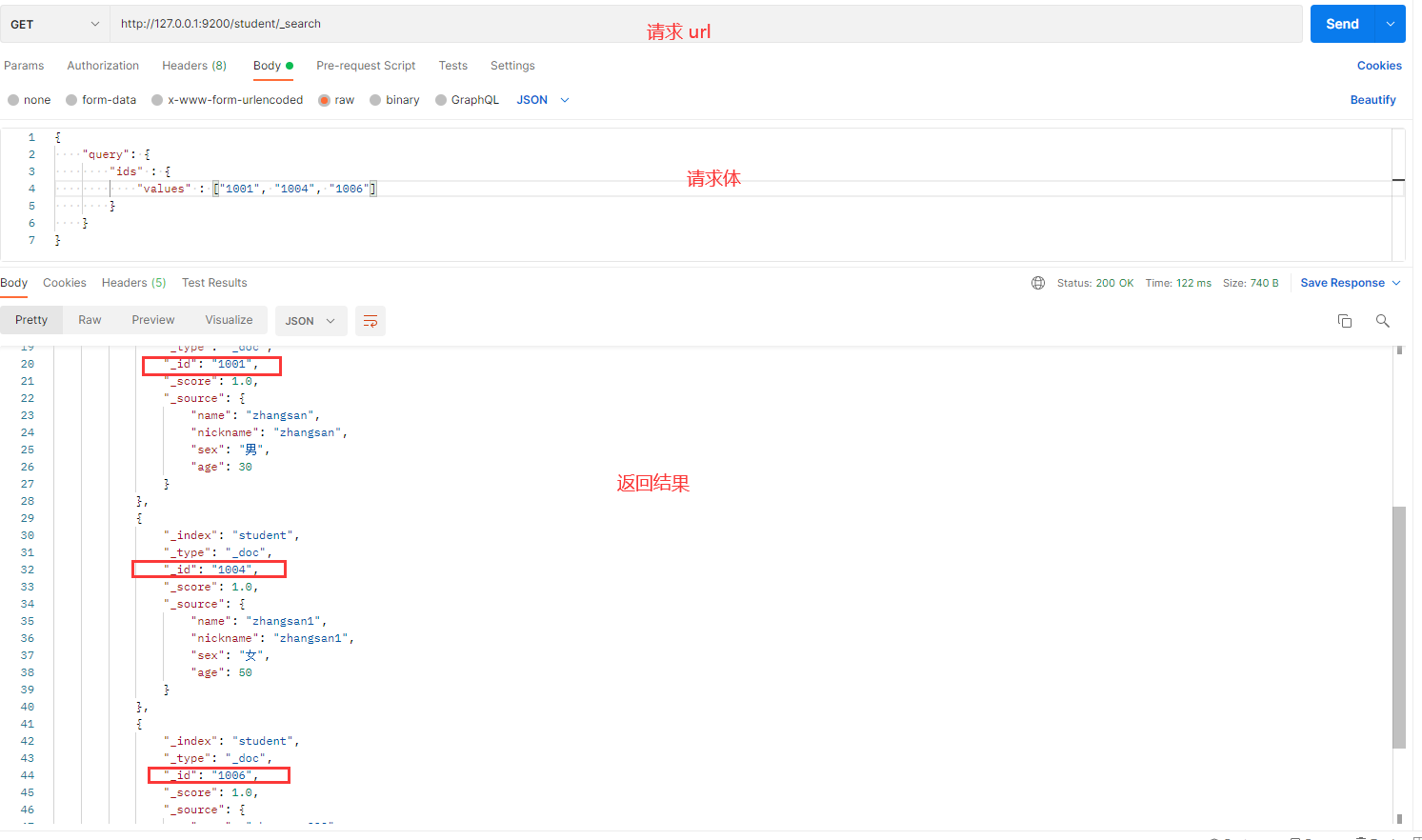
解释:
- ids:根据 ID 列表查询文档。
- values:指定要查询的多个 ID。
Kibana 操作
在 Kibana 中执行多 ID 查询的命令如下:
GET /student/_search
{
"query": {
"ids": {
"values": ["1001", "1004", "1006"]
}
}
}
2
3
4
5
6
7
8
# 13. 前缀查询 (prefix 查询)
prefix 查询用于查找字段值以某个前缀开头的文档,类似于 SQL 中的 LIKE 'prefix%'。
Postman 操作
操作目的:查询 name 字段以 zhangsan 开头的文档。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"prefix": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
发送请求的
截图如下:
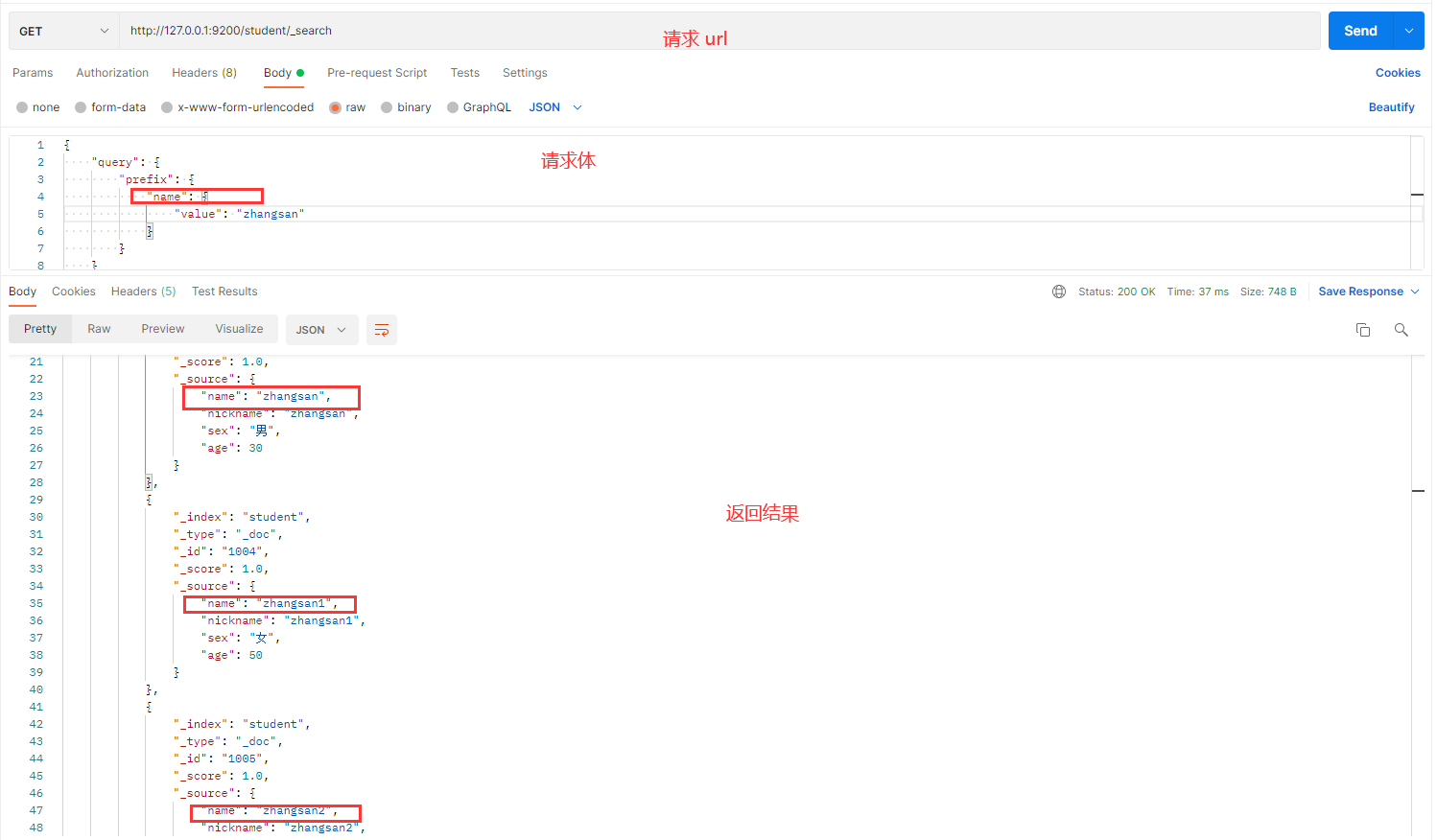
解释:
- prefix:查找字段值以指定前缀开头的文档。
- value:要匹配的前缀。
Kibana 操作
在 Kibana 中执行前缀查询的命令如下:
GET /student/_search
{
"query": {
"prefix": {
"name": {
"value": "zhangsan"
}
}
}
}
2
3
4
5
6
7
8
9
10
# 14. 单字段排序
通过 sort 字段,我们可以按照指定的字段对结果进行排序,并且可以通过 order 指定排序的顺序,支持 desc(降序)和 asc(升序)。
Postman 操作
操作目的:查询 name 包含 zhangsan 的数据,并按 age 字段进行降序排序。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match": {
"name": "zhangsan"
}
},
"sort": [{
"age": {
"order": "desc"
}
}]
}
2
3
4
5
6
7
8
9
10
11
12
发送请求的截图如下:
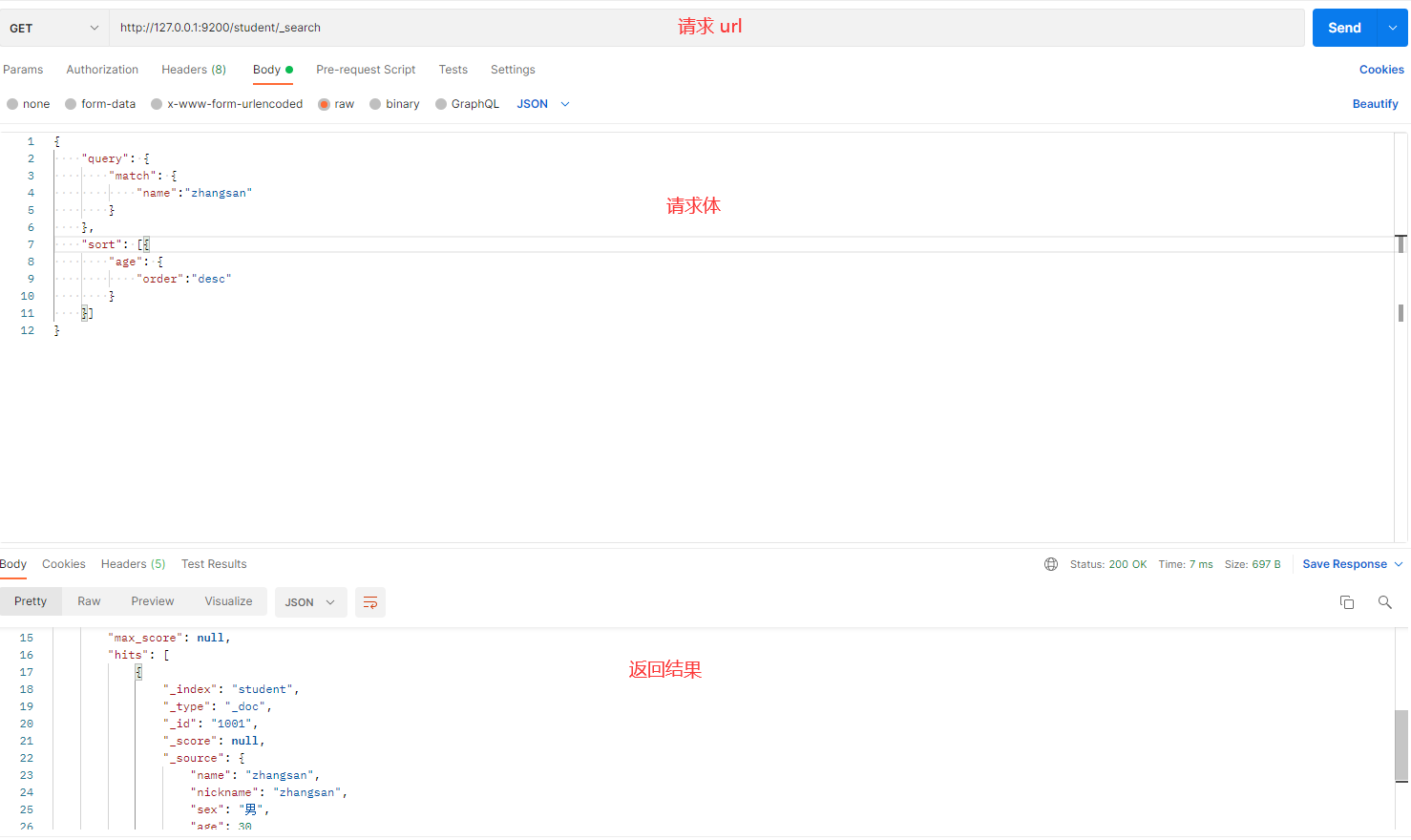
解释:
- query:用于定义查询条件。这里使用
match查询,匹配name包含zhangsan的数据。 - sort:用于指定排序字段和顺序。在这里,按照
age字段进行降序(desc)排序。
Kibana 操作
在 Kibana 中执行单字段排序的命令如下:
GET /student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"sort": [{
"age": {
"order": "desc"
}
}]
}
2
3
4
5
6
7
8
9
10
11
12
13
- 语法说明:
- order:可以是
asc(升序)或desc(降序),用于指定排序顺序。
- order:可以是
# 15. 多字段排序
在某些场景下,可能需要根据多个字段进行排序。Elasticsearch 允许在 sort 中添加多个字段,并按顺序应用排序条件。
Postman 操作
操作目的:查询所有 student 索引中的数据,首先按 age 降序排序,然后按相关性得分(_score)降序排序。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
发送请求的截图如下:
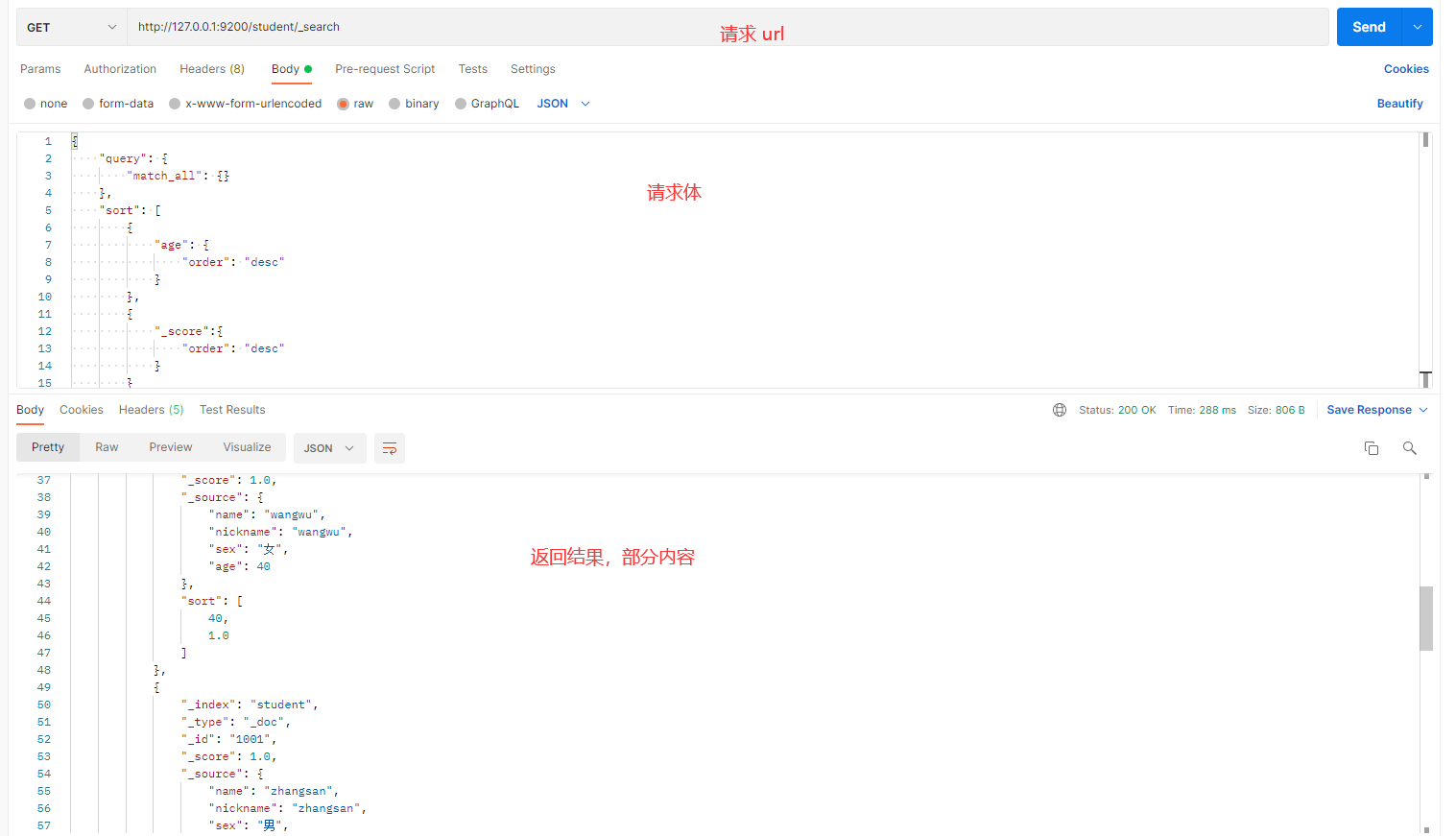
解释:
- match_all:查询所有文档。
- sort:首先按
age字段降序排序,接着按_score(相关性得分)降序排序。
Kibana 操作
在 Kibana 中执行多字段排序的命令如下:
GET /student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
},
{
"_score": {
"order": "desc"
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 语法说明:
- sort:允许多个字段排序,顺序由字段在
sort数组中的位置决定,先定义的字段优先排序。
- sort:允许多个字段排序,顺序由字段在
# 16. 高亮查询
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮。
如图:
Elasticsearch 可以对查询内容中的关键字部分,进行标签和样式(高亮)的设置。
高亮查询在返回搜索结果时,可以将查询匹配到的关键字以高亮的方式展示。通常使用 highlight 配置,支持设置前置标签(pre_tags)和后置标签(post_tags)来包裹高亮部分。
在使用 match 查询的同时,加上一个 highlight 属性:
- pre_tags:前置标签
- post_tags:后置标签
- fields:需要高亮的字段
- title:这里声明 title 字段需要高亮,后面可以为这个字段设置特有配置,也可以为空
Postman 操作
操作目的:查询 name 为 zhangsan 的数据,并将匹配的 zhangsan 关键字高亮显示为红色。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
发送请求的截图如下:
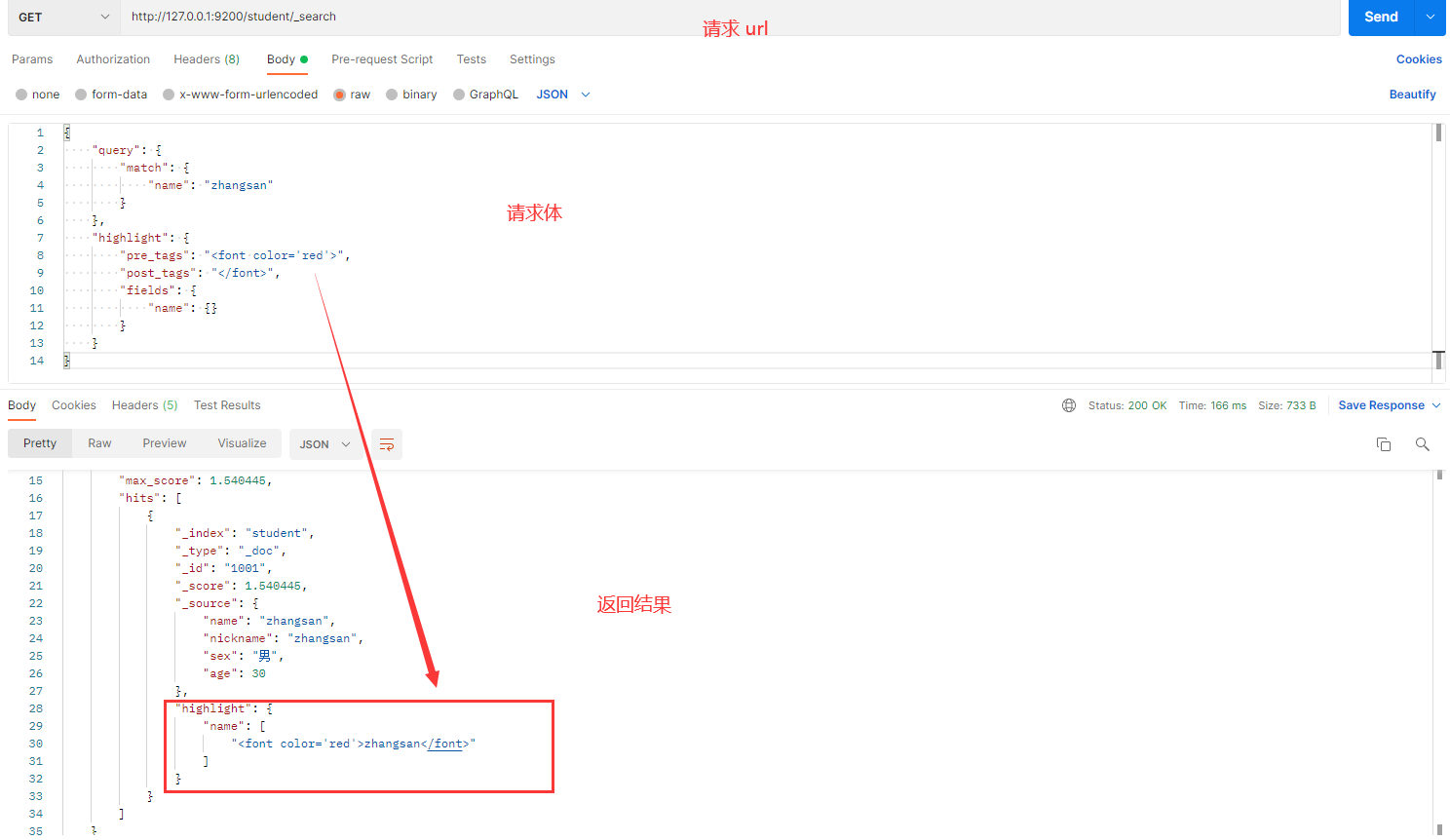
解释:
- highlight:用于指定高亮设置。
- pre_tags 和 post_tags:用于包裹高亮内容,类似 HTML 标签。在这里,关键字
zhangsan被包裹在<font color='red'>和</font>中。 - fields:指定要进行高亮的字段,这里是
name字段。
- pre_tags 和 post_tags:用于包裹高亮内容,类似 HTML 标签。在这里,关键字
Kibana 操作
在 Kibana 中执行高亮查询的命令如下:
GET /student/_search
{
"query": {
"match": {
"name": "zhangsan"
}
},
"highlight": {
"pre_tags": "<font color='red'>",
"post_tags": "</font>",
"fields": {
"name": {}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 语法说明:
- highlight:用于设置高亮字段和标签。
- fields:指定哪些字段进行高亮。
# 17. 分页查询
分页查询是为了限制一次返回的数据量,from 参数指定从哪条数据开始查询,而 size 参数指定每次返回多少条数据。
Postman 操作
操作目的:查询 student 索引中的数据,按照 age 降序排序,并返回从第 0 条开始的 2 条数据。
- 请求 URL:
http://127.0.0.1:9200/student/_search - 请求方法:
GET
操作步骤:
- 打开 Postman,选择
GET请求方法。 - 在 URL 栏中输入
http://127.0.0.1:9200/student/_search。 - 在请求体中输入如下 JSON 格式的数据,点击发送请求按钮。
请求体内容:
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
2
3
4
5
6
7
8
9
10
11
12
13
14
发送请求的截图如下:
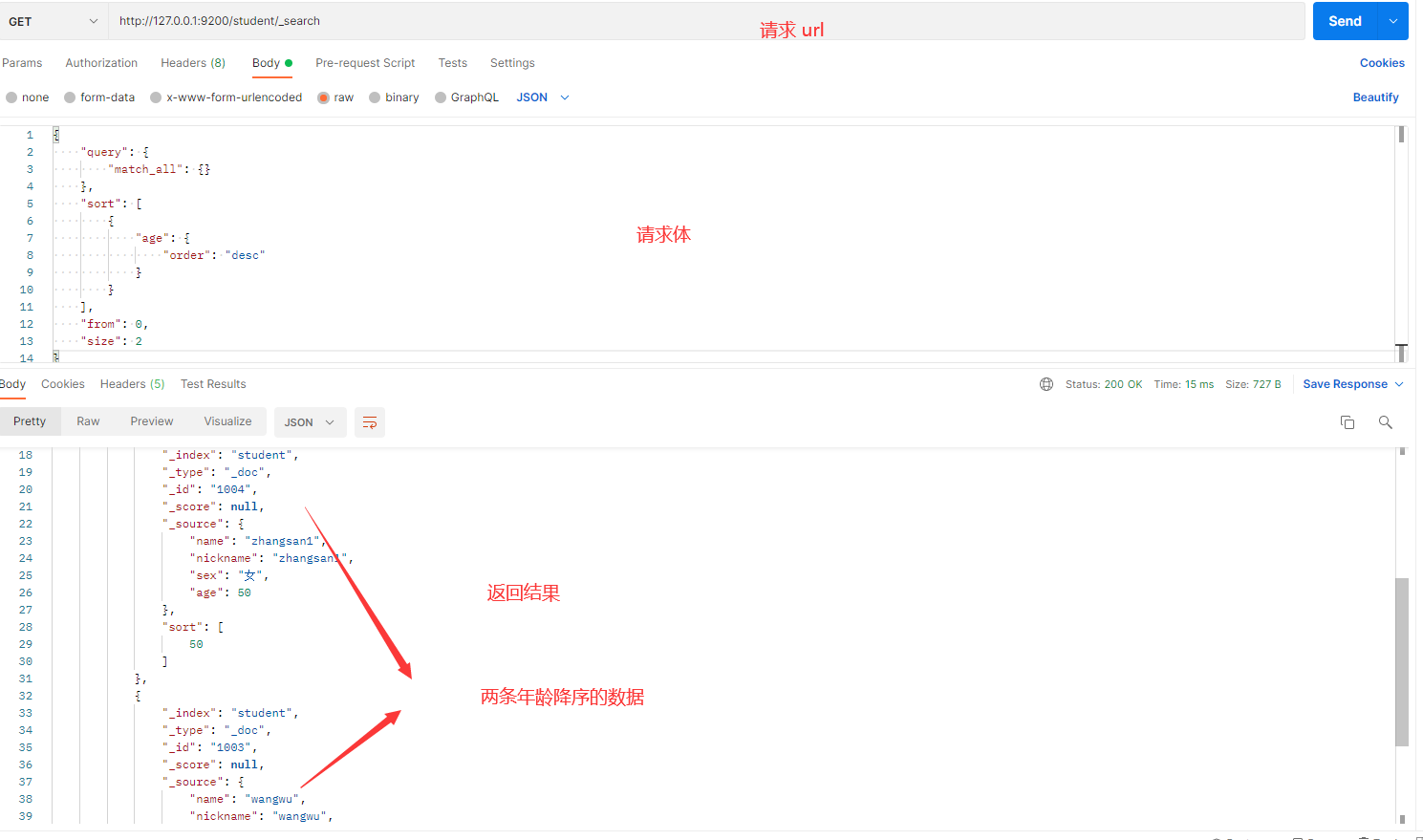
解释:
- from:指定从第几条数据开始查询,这里是从第 0 条开始。
- size:指定返回的文档条数,这里是返回 2 条。
- sort:按
age字段降序排序。
Kibana 操作
在 Kibana 中执行分页查询的命令如下:
GET /student/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 2
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 语法说明:
- from:用于指定起始数据位置,类似于 SQL 的
OFFSET。 - size:用于指定每页返回的数据条数,类似于 SQL 的
LIMIT。
- from:用于指定起始数据位置,类似于 SQL 的
# 聚合查询
聚合允许使用者对 es 文档进行统计分析,类似与关系型数据库中的 group by,当然还有很多其他的聚合,例如取最大值、平均值等等。
聚合查询 aggs 字段,该字段里的第一个字段是自定义名字,一个聚合/分组需要另一个聚合/分组需要用到自定义名字(嵌套查询)。第二个字段是聚合查询类型。查询结果不仅有聚合结果,也有设计到的详细数据。
结果长度 size 字段和 aggs 字段同级,代表只获取聚合结果,不获取涉及到的详细数据。
如图:(第一个是不用 size,第二个图用了 size)

不用 size 图
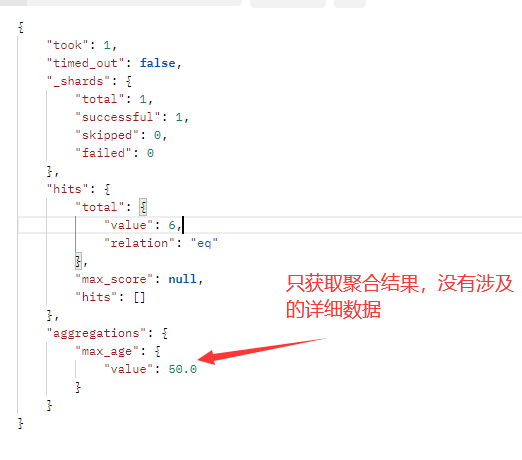
用了 size 图
# 1. 简单聚合
- 对某个字段取最大值 max
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
请求体内容:
{
"aggs":{
"max_age":{ // 自定义名字
"max":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"max_age":{ // 自定义名字
"max":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- 对某个字段取最小值 min
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
请求体内容:
{
"aggs":{
"min_age":{ // 自定义名字
"min":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"min_age":{ // 自定义名字
"min":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- 对某个字段求和 sum
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
请求体内容:
{
"aggs":{
"sum_age":{ // 自定义名字
"sum":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"sum_age":{ // 自定义名字
"sum":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- 对某个字段取平均值 avg
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
{
"aggs":{
"avg_age":{ // 自定义名字
"avg":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"avg_age":{ // 自定义名字
"avg":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- 对某个字段的值进行去重之后再取总数
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
{
"aggs":{
"distinct_age":{ // 自定义名字
"cardinality":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"distinct_age":{ // 自定义名字
"cardinality":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- State 聚合
stats 聚合,对某个字段一次性返回 count,max,min,avg 和 sum 五个指标
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs":{
"stats_age":{ // 自定义名字a
"stats":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"stats_age":{ #// 自定义名字
"stats":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
# 2. 桶聚合查询
桶聚和相当于 sql 中的 group by 语句
- terms 聚合,分组统计
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
对 age 进行分组,返回的结果部分:
"aggregations": {
"age_groupby": {
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 0,
"buckets": [
{
"key": 30,
"doc_count": 3
},
{
"key": 20,
"doc_count": 1
},
{
"key": 40,
"doc_count": 1
},
{
"key": 50,
"doc_count": 1
}
]
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
代表 age 为 30 的文档数据有 3 个,age 为 20、40、50 的文档数据各有 1 个。
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{"field":"age"}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
- 嵌套查询
在 Postman 中,向 ES 服务器发 GET 请求 :http://127.0.0.1:9200/student/_search
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{
"field": "age",
},
"aggs": {
"average_age": {
"avg": {
"field": "age"
}
}
}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{
"field": "age",
},
"aggs": {
"average_balance": {
"avg": {
"field": "age"
}
}
}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 在 terms 分组下再进行聚合和排序
在 Postman 中,向 ES 服务器发 GET 请求:http://127.0.0.1:9200/student/_search
这里就用到了自定义的名字,如下 average_age 名代表对 age 去平均值,age_groupby 里先对 age 进行分组,再取平均值并且排序,所以需要 average_age 名。
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{
"field": "age",
"order": {
"average_age": "desc"
}
},
"aggs": {
"average_age": {
"avg": {
"field": "age"
}
}
}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
在 Kibana 中,向 ES 服务器发 GET 请求:
GET /student/_search
{
"aggs":{
"age_groupby":{ // 自定义名字
"terms":{
"field": "age",
"order": {
"average_balance": "desc"
}
},
"aggs": {
"average_balance": {
"avg": {
"field": "age"
}
}
}
}
},
"size":0 // 只获取聚合结果,不获取每一个数据
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 批量操作
在 Elasticsearch 中,批量操作可以有效减少网络传输和服务器负载,优化查询和数据操作效率。通过批量查询 (mget) 和批量增删改 (bulk),可以一次性完成多个文档的操作。本文将详细总结这些批量操作,并结合 Postman 和 Kibana 进行说明。
# 1. 批量查询 (mget)
批量查询(mget)允许用户通过一次请求查询多个文档,而不需要为每个文档发送单独的查询请求。这样可以有效减少网络开销和服务器负载。
基本语法
GET /_mget
{
"docs": [
{
"_index": "your_index_name",
"_id": "document_id"
},
{
"_index": "your_index_name",
"_id": "another_document_id"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
语法说明:
- _mget:表示批量查询。
- docs:文档集合,包含要查询的多个文档,每个文档通过
_index和_id唯一标识。 - _index:指定文档所在的索引。
- _id:指定要查询的文档 ID。
Postman 操作
操作目的:批量查询 test_index 索引中的 ID 为 1 和 7 的文档。
- 请求 URL:
http://127.0.0.1:9200/_mget - 请求方法:
GET
请求体内容:
{
"docs": [
{
"_index": "test_index",
"_id": 1
},
{
"_index": "test_index",
"_id": 7
}
]
}
2
3
4
5
6
7
8
9
10
11
12
查询结果会返回 ID 为 1 和 7 的文档内容。
去掉 Type 查询(新版 Elasticsearch)
新版 Elasticsearch 不再使用 type,因此可以去掉 type 字段。
示例操作
GET /_mget
{
"docs": [
{
"_index": "test_index",
"_id": 2
},
{
"_index": "test_index",
"_id": 3
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
同一索引下批量查询
如果要查询同一索引下的多个文档,可以简化请求格式。
示例操作
GET /test_index/_mget
{
"docs": [
{
"_id": 2
},
{
"_id": 3
}
]
}
2
3
4
5
6
7
8
9
10
11
使用 search 语法进行批量查询
除了 mget,还可以使用 search 查询,通过 ids 进行批量查询。
示例操作
POST /test_index/_doc/_search
{
"query": {
"ids": {
"values": ["1", "7"]
}
}
}
2
3
4
5
6
7
8
解释:
- query:定义查询条件,这里使用
ids进行批量 ID 查询。 - values:指定要查询的文档 ID 列表。
# 2. 批量增删改 (bulk)
批量增删改(bulk)允许用户在一个请求中执行多种操作(如添加、删除、更新),有效减少网络传输次数和服务器负载。
基本语法
POST /_bulk
{"action": {"metadata"}}
{"data"}
2
3
每个操作都由两个 JSON 文档组成:
- 第一个 JSON 文档定义操作类型(如
delete、create、index、update)和相关元数据(如索引名、文档 ID)。 - 第二个 JSON 文档包含文档数据(对于
create和index操作)或更新内容(对于update操作)。
操作类型:
- delete:删除文档,只需要提供元数据,不需要文档数据。
- create:强制创建文档(类似于
PUT的_create操作),需要文档数据。 - index:普通的
PUT操作,既可以创建文档,也可以替换文档。 - update:部分更新文档,需要提供更新数据。
Postman 操作
操作目的:删除 ID 为 5 的文档,创建 ID 为 14 的文档,更新 ID 为 2 的文档。
- 请求 URL:
http://127.0.0.1:9200/_bulk - 请求方法:
POST
请求体内容:
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }
{ "update": { "_index": "test_index", "_id": "2" }}
{ "doc": { "test_field": "bulk test" }}
2
3
4
5
解释:
- delete:删除索引为
test_index且 ID 为 5 的文档。 - create:创建索引为
test_index且 ID 为 14 的文档,内容为{"test_field": "test14"}。 - update:更新索引为
test_index且 ID 为 2 的文档,更新字段为{"test_field": "bulk test"}。
Kibana 操作
在 Kibana 中执行批量增删改操作的命令如下:
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "5" }}
{ "create": { "_index": "test_index", "_id": "14" }}
{ "test_field": "test14" }
{ "update": { "_index": "test_index", "_id": "2" }}
{ "doc": { "test_field": "bulk test" }}
2
3
4
5
6
bulk 格式注意事项
- 每个操作的 JSON 文档必须在一行内完成,不能换行。
- 相邻的两个 JSON 文档之间必须换行,不能在同一行内。
- 每个操作相互独立,失败的操作不会影响其他操作。
- 执行
bulk请求时,不要让请求过大,以免性能下降。建议一次请求包含几千个操作,大小在几 MB 内。
# 3. 批量操作的实际应用
批量删除文档
POST /_bulk
{ "delete": { "_index": "test_index", "_id": "1" }}
{ "delete": { "_index": "test_index", "_id": "2" }}
2
3
- delete:删除索引为
test_index中的 ID 为 1 和 2 的文档。
批量创建文档
POST /_bulk
{ "index": { "_index": "test_index", "_id": "1" }}
{ "field1": "value1", "field2": "value2" }
{ "index": { "_index": "test_index", "_id": "2" }}
{ "field1": "value3", "field2": "value4" }
2
3
4
5
- index:创建索引为
test_index且 ID 为 1 和 2 的文档,分别包含不同的字段和内容。
批量更新文档
POST /_bulk
{ "update": { "_index": "test_index", "_id": "1" }}
{ "doc": { "field1": "new_value1" }}
{ "update": { "_index": "test_index", "_id": "2" }}
{ "doc": { "field1": "new_value2" }}
2
3
4
5
- update:部分更新索引为
test_index且 ID 为 1 和 2 的文档,分别更新字段field1的值。
总结
- 批量查询 (
mget):允许通过一次请求查询多个文档,减少网络开销。可以通过指定_index和_id实现跨索引或同一索引下的批量查询。 - 批量增删改 (
bulk):允许通过一次请求执行多种操作(如删除、创建、更新),提高操作效率。每个操作相互独立,失败的操作不会影响其他操作。 - 性能优化:批量操作请求不宜过大,建议每次请求包含几千个操作,大小控制在几 MB 内,避免服务器性能下降。