 ElasticSearch - 安装
ElasticSearch - 安装
官网教程
- 官方网站(opens new window) (opens new window)
- 官方2.x中文教程中安装教程(opens new window) (opens new window)
- 官方ElasticSearch下载地址(opens new window) (opens new window)
- 官方Kibana下载地址 (opens new window)
# 1. 安装 ES- Windows 版本
# 1. 下载并安装 ElasticSearch
首先,前往 ElasticSearch 官方下载页面 (opens new window) 下载适用于 Windows 的版本。
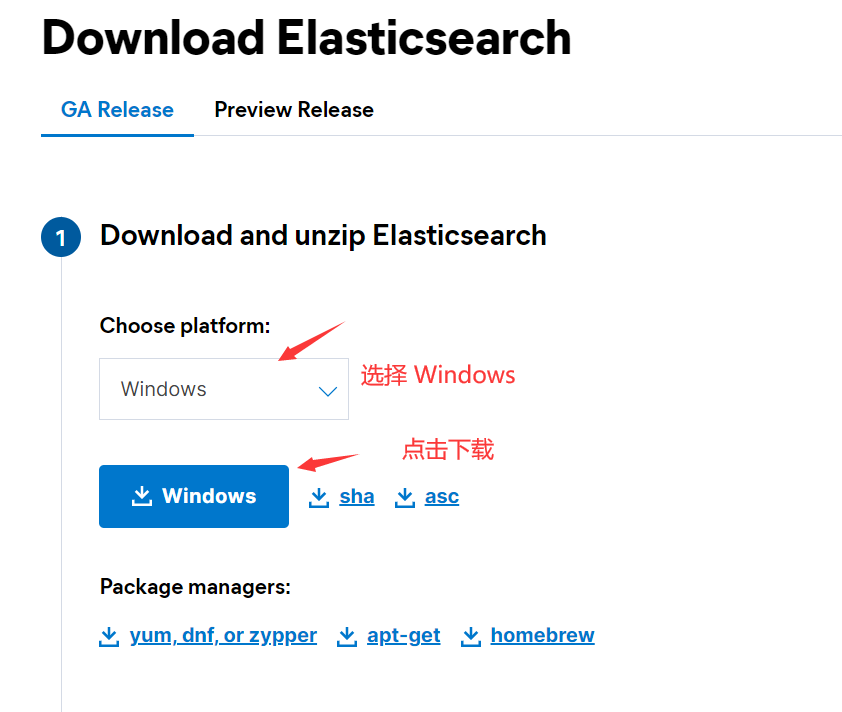
下载的文件为一个压缩包。下载完成后,将其解压缩到你希望安装的目录。
# 2. 目录结构说明
解压后的 ElasticSearch 目录包含多个子文件夹。每个文件夹的作用如下:
根目录
|—— bin:可执行脚本目录
|—— config:配置目录
|—— log4j2.properties:日志配置文件
|—— jvm.options:Java 虚拟机的配置
|—— elasticsearch.yml:ElasticSearch 的主配置文件
|—— data:索引数据目录
|—— lib:相关类库 Jar 包目录
|—— logs:日志目录
|—— modules:功能模块目录
|—— plugins:插件目录
2
3
4
5
6
7
8
9
10
11
- bin:此目录包含启动和管理 ElasticSearch 的可执行文件。
- config:包含 ElasticSearch 的配置文件,最重要的文件包括
elasticsearch.yml(主要配置文件)和jvm.options(JVM 参数配置)。 - data:存储 ElasticSearch 的数据索引。
- lib:ElasticSearch 运行所需的库文件。
- logs:保存运行时的日志文件。
- modules:ElasticSearch 的内置模块。
- plugins:用于存放安装的插件。
# 3. 启动 ElasticSearch
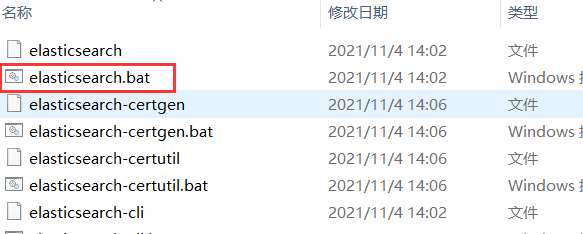
接下来,我们进入 bin 目录,找到用于启动 ElasticSearch 的脚本。
在 bin 目录中,你会看到如下文件结构:
bin/
|—— elasticsearch.bat:用于在 Windows 上启动 ElasticSearch
|—— elasticsearch-plugin.bat:用于管理插件的工具
2
3
我们重点关注的是 elasticsearch.bat 文件,这是用于启动 ElasticSearch 的文件。通过双击该文件或在命令行窗口中执行 elasticsearch.bat,你可以启动 ElasticSearch。
# 4. 验证 ElasticSearch 是否成功启动
启动后,你可以通过浏览器访问 ElasticSearch 的 HTTP 服务,默认端口为 9200。
在浏览器中输入 http://localhost:9200,如果一切正常,你会看到类似于以下内容的返回信息:
{
"name" : "node-1",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "Z5nHgFWoQkqx5OWEK2J6zw",
"version" : {
"number" : "7.8.0",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "c65a6211ae4169d53f31239aeb1f3f99f5f3d0f2",
"build_date" : "2020-06-14T19:35:50.234439Z",
"build_snapshot" : false,
"lucene_version" : "8.5.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
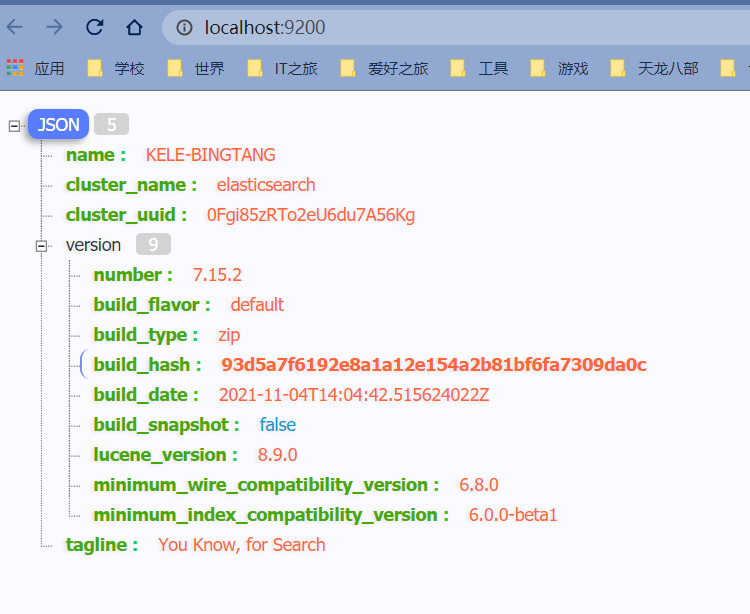
如果你能看到这样的页面,说明 ElasticSearch 已经在你的 Windows 系统上成功运行。
# 5. 常见问题及解决方案
1. 启动窗口闪退
在某些情况下,你双击 elasticsearch.bat 启动 ElasticSearch 时,窗口会迅速闪退。这通常是由于内存配置或环境变量问题导致的。
问题排查步骤:
- 打开命令行窗口,通过命令行进入
bin目录,执行elasticsearch.bat,查看具体的报错信息。 - 如果报错信息显示为 “空间不足”,可以通过修改
config/jvm.options文件来调整 JVM 内存分配。
修改内存配置
找到 config/jvm.options 文件,修改其中的内存设置:
# 设置 JVM 初始内存为 1G。此值可以设置与-Xmx 相同,以避免每次垃圾回收完成后 JVM 重新分配内存
-Xms1g
# 设置 JVM 最大可用内存为 1G
-Xmx1g
2
3
4
根据你的计算机内存大小,可以适当调整这两个参数。推荐将初始内存和最大内存设为相同的值,以避免 JVM 在垃圾回收后频繁调整内存。
2. JAVA 环境问题
ElasticSearch 是基于 Java 开发的,它需要 JDK 1.8 以上版本。7.8 版本之后的 ElasticSearch 默认捆绑了 JDK,但你也可以使用系统中配置的 JDK。
- 如果你的系统已经配置了
JAVA_HOME环境变量,ElasticSearch 会优先使用系统中的 JDK。 - 如果没有配置
JAVA_HOME,ElasticSearch 会使用自带的 JDK。
你可以通过命令行执行 java -version 检查当前系统中 JDK 的版本,确保其符合 ElasticSearch 的最低要求(JDK 1.8 以上)。
# 2. 安装 ES- Linux 版本
ElasticSearch 是一个强大的分布式搜索引擎,本教程将详细介绍如何在 Linux 系统上安装 ElasticSearch,并进行必要的配置以确保其稳定运行。我们将涵盖从下载、用户权限配置到启动的各个步骤,确保您顺利完成安装并成功启动 ElasticSearch。
# 1. 下载并安装 ElasticSearch
在开始之前,请确保你的 Linux 系统已经安装了 JDK 1.8 或更高版本,ElasticSearch 7.8 及以上版本要求最低 JDK 版本为 1.8。
1. 下载 ElasticSearch
前往 ElasticSearch 官方下载页面 (opens new window) 下载适用于 Linux 的版本。
准备一台服务器或有 Linux 系统的虚拟机。
2. 创建安装目录
进入 /usr/local/ 目录,并创建一个新的目录 elastic-stack 来存放 ElasticSearch 及其相关组件:
cd /usr/local/
mkdir elastic-stack
2
- 传输安装包
将下载的 ElasticSearch Linux 版本安装包通过工具(如 Xftp)传输到 Linux 系统中刚刚创建的 elastic-stack 目录下。

4. 解压安装包
在 Linux 系统中,进入 elastic-stack 目录,并解压下载好的安装包:
cd /usr/local/elastic-stack
tar -zxvf elasticsearch-7.15.2-linux-x86_64.tar.gz
2
解压完成后,目录中会生成一个名为 elasticsearch-7.15.2 的文件夹。你可以选择将其重命名为更短的名字,或者移动到其他位置。
# 将文件夹重命名为 es
mv elasticsearch-7.15.2 es
2
# 2. 创建 ElasticSearch 用户
ElasticSearch 出于安全考虑,强制要求不能以 root 用户运行。我们需要在Linux服务器创建一个非 root 的用户 elasticsearch 来运行 ElasticSearch。
1. 增加 elasticsearch 用户
useradd elasticsearch
passwd elasticsearch
2
按照提示为新用户设置密码。
2. 修改目录权限
为了确保 elasticsearch 用户拥有 ElasticSearch 目录的权限,我们需要修改其目录的所有权:
chown -R elasticsearch /usr/local/elastic-stack/es
# 3. 配置 ElasticSearch
在启动 ElasticSearch 之前,我们需要对其进行一些必要的配置。
1. 修改 elasticsearch.yml 文件
elasticsearch.yml 是 ElasticSearch 的核心配置文件,位于 config 目录下。我们需要修改数据存储路径和日志路径,并进行一些基本配置。
编辑 elasticsearch.yml 文件:
vi /usr/local/elastic-stack/es/config/elasticsearch.yml
在文件中找到以下配置项并进行修改:
# 集群名称
cluster.name: elasticsearch
# 节点名称
node.name: node-1
# 允许外界访问的 IP
network.host: 0.0.0.0
# HTTP 访问端口
http.port: 9200
# 指定集群中的主节点
cluster.initial_master_nodes: ["node-1"]
2
3
4
5
6
7
8
9
10
同时修改数据存储和日志路径:
# 数据存储路径
path.data: /data/es
# 日志存储路径
path.logs: /var/log/es
2
3
4
2. 修改系统限制
ElasticSearch 需要较高的文件数限制和线程数。我们需要修改 Linux 系统中允许的最大文件数和线程数,以确保 ElasticSearch 能正常运行。
修改文件数限制
编辑 /etc/security/limits.conf 文件,添加以下内容:
# 每个进程可以打开的文件数的限制
elasticsearch soft nofile 65536
elasticsearch hard nofile 65536
2
3
修改线程数限制
编辑 /etc/security/limits.d/20-nproc.conf 文件,在文件末尾添加以下内容:
# 限制每个用户最多可以开启的线程数
elasticsearch soft nproc 4096
elasticsearch hard nproc 4096
2
3
修改虚拟内存设置
编辑 /etc/sysctl.conf 文件,增加以下配置项:
# 一个进程可以拥有的 VMA (虚拟内存区域)数量,默认值为 65536
vm.max_map_count=655360
2
完成后,执行以下命令以重新加载配置:
sysctl -p
# 4. 启动 ElasticSearch
配置完成后,我们可以切换到新创建的 elasticsearch 用户并启动 ElasticSearch。
1. 切换用户并启动
首先,切换到 elasticsearch 用户:
su elasticsearch
然后进入 ElasticSearch 的安装目录,并使用 elasticsearch 命令启动 ElasticSearch:
cd /usr/local/elastic-stack/es
./bin/elasticsearch -d
2
-d 参数表示以后台模式启动 ElasticSearch。
2. 处理启动错误
在启动过程中,ElasticSearch 会动态生成一些文件。如果这些文件的所属用户与当前运行的用户不匹配,可能会导致启动失败。此时,你需要重新调整文件的权限:
chown -R elasticsearch /usr/local/elastic-stack/es
# 5. 验证安装成功
启动成功后,我们可以通过检查端口状态或直接访问 HTTP 接口来确认 ElasticSearch 是否正常运行。
1. 检查端口状态
通过以下命令检查 ElasticSearch 是否在监听 9200 端口:
netstat -ntlp | grep 9200
你应该能看到如下输出,表示 ElasticSearch 正在运行并监听 9200 端口:
tcp6 0 0 127.0.0.1:9200 :::* LISTEN 11601/java
2. 测试 HTTP 接口
通过 curl 命令访问 ElasticSearch 的 HTTP 接口,确认安装成功:
curl 127.0.0.1:9200
你应该能看到如下 JSON 响应:
{
"name": "node-1",
"cluster_name": "elasticsearch",
"cluster_uuid": "0Fgi85zRTo2eU6du7A56Kg",
"version": {
"number": "7.15.2",
"build_flavor": "default",
"build_type": "zip",
"build_hash": "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c",
"build_date": "2021-11-04T14:04:42.515624022Z",
"build_snapshot": false,
"lucene_version": "8.9.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 3. Docker 安装 ES
通过 Docker 安装 ElasticSearch 也不需要进行手动的权限或用户配置。ElasticSearch 的 Docker 镜像已经为你预先配置好了所需的环境、权限和用户。因此,当你使用 Docker 来安装和运行 ElasticSearch 时,你只需要关注网络配置和数据挂载等问题,而无需手动创建用户或修改文件权限。
# 1. 准备工作
1. 安装 Docker
在开始安装 ElasticSearch 之前,请确保系统中已经安装了 Docker。如果尚未安装 Docker,可以通过以下步骤安装:
1.1. 安装 Docker(以 Ubuntu 为例)
sudo apt-get update
sudo apt-get install docker.io
2
1.2. 验证 Docker 是否成功安装
docker --version
你应该能看到类似于 Docker version 20.10.x, build xxxx 的输出,表示 Docker 已成功安装。
# 2. 通过 Docker 安装 ElasticSearch
1. 拉取 ElasticSearch Docker 镜像
ElasticSearch 提供了官方的 Docker 镜像,我们可以通过 docker pull 命令直接拉取最新的 ElasticSearch 镜像。
docker pull docker.elastic.co/elasticsearch/elasticsearch:7.15.2
该命令会下载 ElasticSearch 7.15.2 版本的官方镜像。你可以根据需要选择不同的版本。
2. 启动 ElasticSearch 容器
使用以下命令在 Docker 中启动一个 ElasticSearch 容器:
docker run -d --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
docker.elastic.co/elasticsearch/elasticsearch:7.15.2
2
3
参数解释:
-d:以守护进程方式运行容器。--name elasticsearch:为容器指定一个名称elasticsearch。-p 9200:9200:将主机的 9200 端口映射到容器的 9200 端口,用于 HTTP 访问。-p 9300:9300:将主机的 9300 端口映射到容器的 9300 端口,用于集群节点之间的通信。-e "discovery.type=single-node":设置 ElasticSearch 运行在单节点模式,适用于开发和测试环境。
# 3. 配置与调整
在 Docker 中运行 ElasticSearch 时,我们可以通过以下配置对其进行优化,包括数据持久化、内存分配的调整以及轻量化配置。以下内容将统一为挂载到主机目录,以确保容器数据持久化。
1. 创建挂载目录
首先,我们需要为 ElasticSearch 在主机上创建数据和配置文件的挂载目录。使用以下命令创建:
# 创建数据目录
mkdir -p /home/elasticsearch/data/
# 创建配置文件目录
mkdir -p /home/elasticsearch/config/
2
3
4
5
2. 编写配置文件
ElasticSearch 的配置文件需要放置在 /home/elasticsearch/config/elasticsearch.yml 中。我们可以通过以下命令向配置文件中写入跨域配置和绑定主机地址:
echo 'http.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
' >> /home/elasticsearch/config/elasticsearch.yml
2
3
4
3. 修改文件夹权限
为了确保 ElasticSearch 容器能够正确访问我们创建的目录和文件,需要为 /home/elasticsearch 目录及其子目录设置合适的权限。我们可以使用以下命令为这些目录赋予读写权限:
# 修改权限,确保 ElasticSearch 可以访问这些目录
chmod -R 777 /home/elasticsearch/
# 检查文件和目录的权限
ls -l /home/elasticsearch/
2
3
4
5
4. 运行 ElasticSearch 容器
接下来,运行 ElasticSearch Docker 容器,并将我们创建的挂载目录与容器内的 ElasticSearch 目录进行映射:
docker run --name elasticsearch -p 9200:9200 \
-p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx128m" \
-v /home/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /home/elasticsearch/data:/usr/share/elasticsearch/data \
-v /home/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.15.2
2
3
4
5
6
7
8
-Xms64m: 设置 JVM 的初始堆内存为 64MB,适合轻量级应用。-Xmx128m: 设置 JVM 的最大堆内存为 128MB,确保 ElasticSearch 的内存使用不会超过该值。-v /home/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml:将主机上/home/elasticsearch/config/elasticsearch.yml文件挂载到容器内 ElasticSearch 的配置文件目录/usr/share/elasticsearch/config/elasticsearch.yml,用于自定义 ElasticSearch 的配置。-v /home/elasticsearch/data:/usr/share/elasticsearch/data:将主机上的/home/elasticsearch/data目录挂载到容器的/usr/share/elasticsearch/data目录,用于持久化存储 ElasticSearch 索引数据。-v /home/elasticsearch/plugins:/usr/share/elasticsearch/plugins:将主机上的/home/elasticsearch/plugins目录挂载到容器的/usr/share/elasticsearch/plugins,用于存储 ElasticSearch 插件。
注意事项
- ElasticSearch 默认会使用 2GB 的内存。如果你的系统内存有限,或者你在开发环境中使用,可以通过调整
ES_JAVA_OPTS来减少内存占用。 - 在某些开发或测试环境中,可能希望 ElasticSearch 占用尽量少的内存。这时可以将内存设置为较低值,比如初始内存为 64MB,最大内存为 128MB。
# 4. 查看 ElasticSearch 状态
启动容器后,可以通过访问 http://localhost:9200 来确认 ElasticSearch 是否正常运行。
curl http://localhost:9200
你应该能看到类似如下的 JSON 响应,表示 ElasticSearch 已成功启动:
{
"name" : "node-1",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "tXJYtI_HSm6xDfrNVZ32gQ",
"version" : {
"number" : "7.15.2",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "93d5a7f6192e8a1a12e154a2b81bf6fa7309da0c",
"build_date" : "2021-11-04T14:04:42.515624022Z",
"build_snapshot" : false,
"lucene_version" : "8.9.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 5. 管理 ElasticSearch 容器
1. 停止 ElasticSearch 容器
如果需要停止运行中的 ElasticSearch 容器,可以使用以下命令:
docker stop elasticsearch
2. 启动已停止的容器
使用以下命令重新启动已经停止的 ElasticSearch 容器:
docker start elasticsearch
3. 查看 ElasticSearch 日志
通过 docker logs 命令可以查看 ElasticSearch 容器的日志,帮助诊断和解决问题:
docker logs elasticsearch
4. 删除 ElasticSearch 容器
如果不再需要 ElasticSearch 容器,可以使用以下命令将其删除:
docker rm -f elasticsearch
-f 选项表示强制删除运行中的容器。
# 6. ElasticSearch Docker Compose 部署
为了更加方便管理 ElasticSearch 及其相关组件,我们可以使用 Docker Compose 来定义和启动服务。以下是一个简单的 docker-compose.yml 配置文件:
version: '3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.15.2
container_name: elasticsearch
environment:
- discovery.type=single-node
- ES_JAVA_OPTS=-Xms1g -Xmx1g
ports:
- "9200:9200"
- "9300:9300"
volumes:
- /path/to/your/data:/usr/share/elasticsearch/data
2
3
4
5
6
7
8
9
10
11
12
13
1. 使用 Docker Compose 启动
确保已经安装 Docker Compose,然后在配置文件所在目录执行以下命令启动 ElasticSearch:
docker-compose up -d
2. 管理 Docker Compose 服务
- 启动服务:
docker-compose up -d - 停止服务:
docker-compose down - 查看服务状态:
docker-compose ps
# 4. 安装 Kibana - Windows 版本
Kibana 是 Elastic Stack 中用于可视化 ElasticSearch 数据的开源用户界面。通过 Kibana,你可以快速创建仪表盘、分析数据,并且进行系统的监控。
Kibana 的内存需求
- 默认情况下,Kibana 会占用 2GB 左右的内存。如果服务器的内存较少,可能会导致性能下降或者服务崩溃。
- 你可以通过修改 Kibana 的 JVM 内存配置来调整其内存使用,如在
kibana.yml中通过ELASTICSEARCH_MEMORY变量调整内存分配。
注意事项
Kibana 会占用较多的内存,尤其是在与大型数据集和复杂可视化处理相关的情况下,建议安装在本地。
# 1. 下载并安装 Kibana
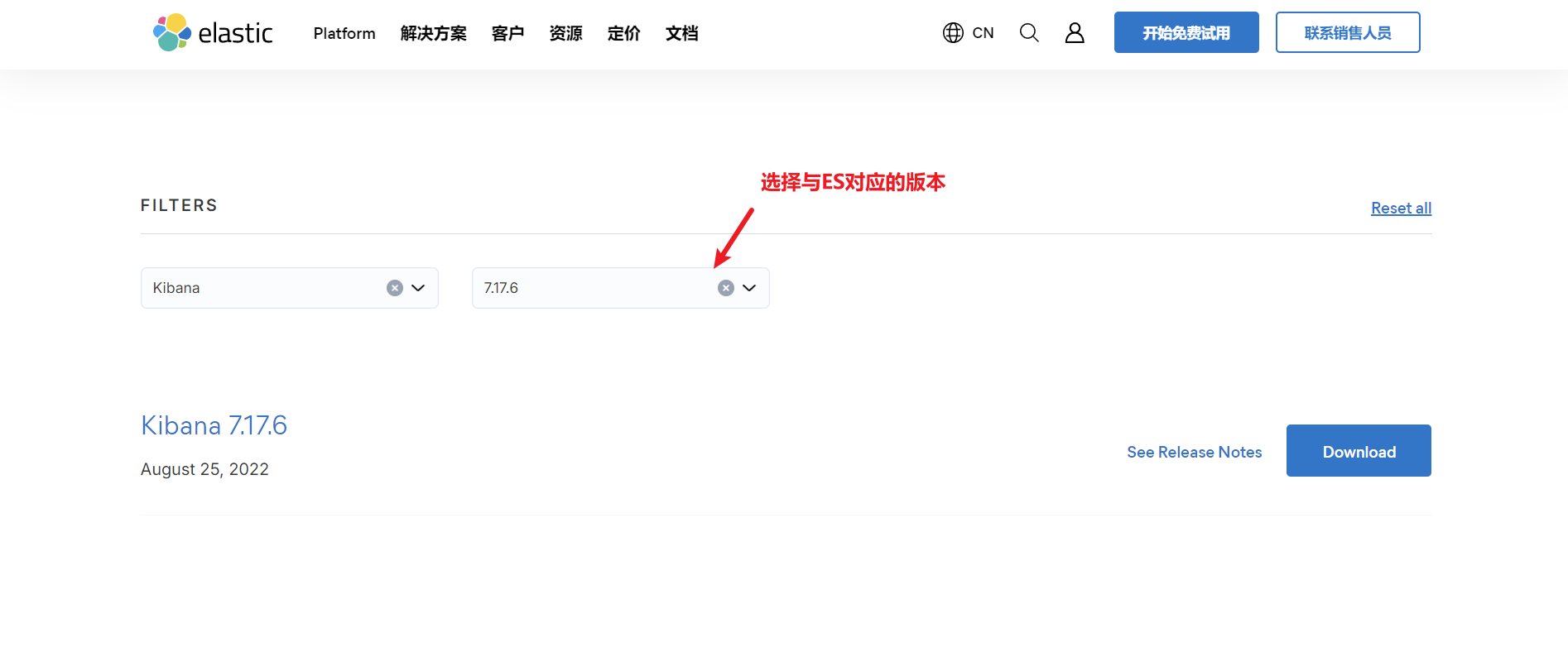
1. 下载 Kibana
首先,前往 Kibana 官方下载页面 (opens new window),下载与 ElasticSearch 版本匹配的 Windows 版本。
2. 解压安装包
下载完成后,解压 Kibana 的压缩包。解压后的目录结构如下:
此目录包含以下重要文件和文件夹:
- bin:包含启动 Kibana 的可执行文件。
- config:Kibana 的配置文件目录,包含
kibana.yml文件。 - data:用于存储 Kibana 数据。
- logs:Kibana 的日志文件存储目录。
# 2. 启动 Kibana
1. 启动 ElasticSearch
在启动 Kibana 之前,确保 ElasticSearch 已经运行,因为 Kibana 会通过 HTTP 与 ElasticSearch 进行通信。
2. 启动 Kibana
进入 bin 目录,双击 kibana.bat 文件启动 Kibana 服务:
cd /path/to/kibana/bin
kibana.bat
2
Kibana 将启动并在终端中显示日志。默认情况下,Kibana 会监听 5601 端口。
笔记
Kibana 启动之前,ElasticSearch 必须已经成功启动,并且运行在 9200 端口。
# 3. 访问 Kibana
Kibana 启动后,你可以通过浏览器访问 Kibana 的用户界面,默认地址为:
http://localhost:5601
当你访问此地址时,Kibana 会自动连接到运行在 9200 端口的 ElasticSearch 实例。此时,你可以开始对 ElasticSearch 数据进行分析和可视化。
# 4. 修改 Kibana 的语言设置
1. 修改为中文界面
默认情况下,Kibana 的用户界面是英文的。你可以通过修改配置文件将界面语言更改为中文。
2. 编辑配置文件
进入 Kibana 的 config 目录,找到并打开 kibana.yml 文件:
cd /path/to/kibana/config
vi kibana.yml
2
3. 添加语言配置
在 kibana.yml 文件底部添加以下内容:
# 默认 Kibana 服务器端口
server.port: 5601
# ElasticSearch 的地址
elasticsearch.hosts: ["http://localhost:9200"]
# Kibana 使用的索引名称
kibana.index: ".kibana"
# 设置语言为中文
i18n.locale: "zh-CN"
2
3
4
5
6
7
8
保存并关闭文件后,重启 Kibana。
4. 启动 Kibana
再次进入 bin 目录,双击 kibana.bat 或通过命令行启动 Kibana:
cd /path/to/kibana/bin
kibana.bat
2
此时,Kibana 的界面将会显示为中文。

# 5. 配置Kibana本地连接远程
Kibana 可以在本地连接远程服务器上的 ElasticSearch 实例进行操作。你只需要在 Kibana 的配置文件中正确配置远程 ElasticSearch 服务器的地址即可。
找到 Kibana 的配置文件: Kibana 的配置文件
kibana.yml位于安装目录的config文件夹中。编辑配置文件: 打开
kibana.yml文件,找到或添加以下配置项,并将localhost:9200修改为远程 ElasticSearch 服务器的地址。例如:# 远程 ElasticSearch 的地址 elasticsearch.hosts: ["http://your-remote-es-server-ip:9200"]1
2其中,
your-remote-es-server-ip应该替换为远程服务器的 IP 地址。配置 ElasticSearch 的权限(可选): 如果远程的 ElasticSearch 设置了访问控制(例如设置了认证机制或跨域访问),你需要在
kibana.yml中添加认证信息:# 远程 ElasticSearch 服务器的用户名和密码(如果有设置认证) elasticsearch.username: "your-username" elasticsearch.password: "your-password"1
2
3保存配置并重启 Kibana: 配置完成后,保存
kibana.yml文件并重启 Kibana。cd /path/to/kibana/bin kibana.bat # Windows ./kibana # Linux 或 macOS1
2
3
注意事项:
- 确保本地机器可以通过网络访问远程服务器的 9200 端口。如果有防火墙或者安全组规则,确保端口已开放。
- 如果远程 ElasticSearch 服务器启用了 TLS/SSL,你可能需要在
kibana.yml中配置相关的 SSL 证书信息。
通过这些配置,Kibana 将可以连接到远程的 ElasticSearch 实例,并对其进行数据可视化和管理。
# 5. 安装 Kibana - Linux 版本
Kibana 是 Elastic Stack 的可视化工具,它能与 ElasticSearch 连接,帮助用户分析数据、生成可视化报表和仪表盘。
# 1. 准备工作
在安装 Kibana 之前,请确保你已经在系统中安装了 JDK 1.8 或更高版本,并且已经有一个运行中的 ElasticSearch 实例。
# 2. 下载并安装 Kibana
1. 下载 Kibana
前往 Kibana 官方下载页面 (opens new window),下载适用于 Linux 的 Kibana 版本。选择与 ElasticSearch 版本相匹配的 Kibana 版本。
2. 传输安装包
下载完成后,通过工具(如 Xftp)将 Kibana 安装包传输到 Linux 系统中。你可以将安装包传输到任意目录,这里我们选择 /usr/local/elastic-stack 目录。

3. 解压 Kibana 安装包
在 Linux 系统中进入 Kibana 的安装目录,解压安装包:
cd /usr/local/elastic-stack
tar -zxvf kibana-7.15.2-linux-x86_64.tar.gz
2
4. 重命名目录
为了方便操作,你可以将解压后的 Kibana 目录重命名为更简短的名字:
mv kibana-7.15.2-linux-x86_64 kibana
# 3. 修改权限
在 Linux 上,由于 Kibana 默认不能以 root 用户运行,建议你使用一个非 root 用户(如 elasticsearch 用户)来启动 Kibana。我们需要将 Kibana 目录的权限设置为该用户。
1. 创建用户(如果尚未创建)
如果你尚未创建 elasticsearch 用户,可以使用以下命令创建:
useradd elasticsearch
passwd elasticsearch
2
2. 修改 Kibana 目录权限
切换到 root 用户,修改 Kibana 目录的所有者为 elasticsearch 用户:
chown -R elasticsearch /usr/local/elastic-stack/kibana
# 4. 配置 Kibana
在启动 Kibana 之前,我们需要对其进行一些基本的配置,如设置连接的 ElasticSearch 实例和界面语言。
1. 修改 Kibana 配置文件
Kibana 的主配置文件是 kibana.yml,位于 config 目录中。我们需要修改该文件以连接到本地的 ElasticSearch 实例,并将界面语言设置为中文。
编辑 kibana.yml 文件:
vim /usr/local/elastic-stack/kibana/config/kibana.yml
在文件底部添加以下内容:
# Kibana 服务器监听的端口,默认为 5601
server.port: 5601
# ElasticSearch 服务器的地址
elasticsearch.hosts: ["http://localhost:9200"]
# Kibana 的索引名称
kibana.index: ".kibana"
# 将界面语言设置为中文
i18n.locale: "zh-CN"
2
3
4
5
6
7
8
保存并退出编辑器。
# 5. 启动 Kibana
1. 切换到 elasticsearch 用户
为了启动 Kibana,我们需要切换到之前创建的 elasticsearch 用户:
su elasticsearch
2. 启动 Kibana
进入 Kibana 的安装目录,并启动 Kibana:
cd /usr/local/elastic-stack/kibana
./bin/kibana
2
Kibana 将启动,并在终端中显示启动日志。
3. 后台启动 Kibana(可选)
如果你希望 Kibana 在后台运行,可以使用 nohup 命令:
nohup ./bin/kibana &
这样 Kibana 将在后台继续运行,即使关闭终端也不会停止。
# 6. 访问 Kibana
当 Kibana 成功启动后,你可以通过浏览器访问 Kibana 的用户界面。默认情况下,Kibana 监听 5601 端口,因此你可以通过以下地址访问:
http://your-server-ip:5601
在浏览器中访问后,你将看到 Kibana 的界面,如果配置了中文,界面语言将显示为中文。
# 7. 开放防火墙端口(可选)
如果你的服务器有防火墙保护,并且希望从外部访问 Kibana,需要开放 5601 端口。你可以使用以下命令开放此端口(以 firewalld 为例):
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --reload
2
# 6. 安装 ES Head 插件 - Windows版本
ElasticSearch Head 是一款用于管理和可视化 ElasticSearch 集群的插件,提供了便捷的图形化界面,帮助用户浏览索引、文档,并管理 ElasticSearch 集群。
# 1. 准备工作
1. 安装 Node.js
ElasticSearch Head 依赖于 Node.js 环境。因此,在安装 ElasticSearch Head 之前,请确保已经安装了 Node.js。
如果还没有安装 Node.js,可以按照以下命令进行安装(以 Ubuntu 为例):
sudo apt update
sudo apt install nodejs
sudo apt install npm
2
3
检查 Node.js 和 npm 是否安装成功:
node -v
npm -v
2
# 2. 下载 ElasticSearch Head
1. 下载地址
你可以从 GitHub 上下载 ElasticSearch Head 源代码:
ElasticSearch Head GitHub 仓库 (opens new window)
- 使用 Git 下载
打开终端或者 Git Bash,执行以下命令下载 ElasticSearch Head 源码:
git clone https://github.com/mobz/elasticsearch-head.git
下载完成后,进入 elasticsearch-head 目录:
cd elasticsearch-head
# 3. 安装依赖
在 ElasticSearch Head 源码目录中,我们需要使用 npm 或 yarn 来安装依赖包。
1. 使用 Yarn 安装依赖
yarn install
2. 使用 NPM 安装依赖
如果没有 Yarn,你也可以使用 npm 安装:
npm install
# 4. 配置 ElasticSearch 允许跨域
由于 ElasticSearch 和 ElasticSearch Head 运行在不同的端口上,存在跨域问题,因此我们需要在 ElasticSearch 的配置文件中启用跨域请求。
1. 修改 ElasticSearch 配置文件
进入 ElasticSearch 的安装目录,找到并编辑配置文件 elasticsearch.yml:
vi /path/to/elasticsearch/config/elasticsearch.yml
在文件末尾添加以下配置项,启用跨域访问:
# 允许跨域请求
http.cors.enabled: true
# 允许所有来源的请求(可根据需求指定域名)
http.cors.allow-origin: "*"
2
3
4
保存配置文件后,重启 ElasticSearch 服务以应用新的配置。
# 5. 启动 ElasticSearch Head
安装完依赖并配置好跨域后,我们可以启动 ElasticSearch Head。
1. 使用 Yarn 启动
yarn run start
2. 使用 NPM 启动
npm run start
ElasticSearch Head 会默认运行在 9100 端口。启动成功后,可以通过浏览器访问以下地址来查看 ElasticSearch 的可视化界面:
http://localhost:9100/
# 6. 配置 ElasticSearch 安全访问(可选)
如果你的 ElasticSearch 实例运行在公网环境中,建议启用安全功能,并设置密码保护访问。
1. 启用 ElasticSearch 安全功能
停止 Kibana 和 ElasticSearch 服务。
编辑 ElasticSearch 配置文件
elasticsearch.yml,添加以下内容以启用安全功能:xpack.security.enabled: true1重启 ElasticSearch:
./bin/elasticsearch -d1
2. 设置 ElasticSearch 组件密码
运行以下命令设置 ElasticSearch 各个组件的访问密码:
./bin/elasticsearch-setup-passwords interactive
系统将提示你为不同的用户(如 elastic 用户)设置密码。
3. 配置 Kibana 连接
在 Kibana 的配置文件 kibana.yml 中,添加 elastic 用户的用户名和密码:
elasticsearch.username: "elastic"
4. 创建并配置 Kibana 密钥库
创建 Kibana 密钥库:
./bin/kibana-keystore create1在 Kibana 密钥库中添加 ElasticSearch 用户的密码:
./bin/kibana-keystore add elasticsearch.password1
5. 重启 Kibana 服务
nohup ./bin/kibana &
这样,Kibana 就会通过设置的用户名和密码连接到启用了安全功能的 ElasticSearch 实例。