 ElasticSearch - 基础概念
ElasticSearch - 基础概念
# ElasticSearch - 基础概念
前言
ElasticSearch 是当前最流行的分布式搜索引擎之一,作为 Elastic Stack 技术栈的核心,它能够处理来自多个数据源的大规模数据,并提供强大的实时搜索和数据分析能力。
# 1. 什么是 ElasticSearch?
ElasticSearch,中文翻译为“弹性搜索”,是一个基于 Apache Lucene 构建的开源、分布式全文搜索引擎。ElasticSearch 可以处理从结构化数据到非结构化数据的搜索任务,支持实时数据的存储、检索和分析。
# Elastic Stack 简介
Elastic Stack(也称 ELK Stack)包括以下组件:
- ElasticSearch:核心搜索和分析引擎,用于存储、索引和查询数据。
- Kibana:数据可视化工具,通过它可以创建仪表盘和报表,展示 ElasticSearch 中的数据。
- Logstash:数据处理管道工具,负责从多个源头收集、处理和发送数据到 ElasticSearch。
- Beats:轻量级数据采集工具,通常用于日志和指标数据的采集。
Elastic Stack 使得 ElasticSearch 可以无缝处理来自任何来源、任何格式的数据,并且通过强大的可视化工具,如 Kibana,帮助用户探索数据并创建自定义的可视化报表。
# ElasticSearch 核心特点
- 分布式架构:ElasticSearch 可以在多个节点上横向扩展,支持海量数据处理。
- 近实时搜索:ElasticSearch 通过其高效的索引机制,实现了近乎实时的数据存储和查询能力。
- 全文检索能力:ElasticSearch 基于 Lucene 构建,具备强大的全文搜索功能。
- 多语言支持:ElasticSearch 提供了多种编程语言的客户端支持,包括 Java、Python、C# 等。
# 2. 全文搜索引擎概述
ElasticSearch 是一个专注于全文搜索的引擎,能够处理大量非结构化数据,如文本、日志等。相较于传统的关系型数据库,ElasticSearch 能够更加高效地对大规模数据进行全文检索。
# 什么是全文搜索?
全文搜索引擎基于 倒排索引 构建,它能够快速找到与关键词匹配的文档。搜索引擎(如 Google、百度)就是基于全文搜索引擎技术,索引网页中的每个关键字,查询时通过关键字匹配返回相关结果。
# 为什么传统数据库无法处理全文搜索?
传统的关系型数据库如 MySQL 在处理全文搜索时,存在以下局限:
- 性能差:传统数据库在处理大规模文本数据时,查询效率低下,尤其是在没有索引的情况下,搜索过程非常耗时。
- 维护困难:即使在数据库上建立索引,随着插入和更新操作的进行,索引维护成本会显著增加。
# 全文搜索引擎的优势
- 高效检索:通过倒排索引,ElasticSearch 能够迅速定位关键词所在的文档。
- 丰富的查询方式:支持模糊查询、布尔查询、短语搜索等高级功能。
- 灵活的扩展性:ElasticSearch 支持分布式架构,可以轻松扩展以处理大规模数据。
# 3. Lucene 和 ElasticSearch 的关系
ElasticSearch 是基于 Apache Lucene 构建的,而 Lucene 是一个开源的全文检索库,提供了底层的索引和搜索功能。虽然 Lucene 功能强大,但直接使用它相对复杂,ElasticSearch 封装了 Lucene 的复杂性,提供了一个 RESTful API,简化了全文检索的操作。
Lucene 简介
Lucene 是由 Apache 基金会开发的一个开源项目,用于处理全文搜索。Lucene 本质上是一个库,它通过为每个文档中的词汇创建倒排索引,快速检索包含特定词汇的文档。
ElasticSearch 的任务就是在 Lucene 之上提供一个分布式搜索引擎,隐藏 Lucene 的复杂性,使得开发者能够通过简单的 RESTful API 进行复杂的查询操作。
# 4. ElasticSearch 与 Solr 的对比
在开源搜索引擎市场上,ElasticSearch 和 Solr 是两大主流选择。它们都基于 Lucene 构建,但在架构、易用性和功能上有所不同。
Solr 简介
Apache Solr 是另一个基于 Lucene 的开源搜索引擎。它同样能够提供强大的搜索和数据分析功能,适合用于处理复杂查询和大量结构化数据。
| 比较项 | ElasticSearch | Solr |
|---|---|---|
| 易用性 | 安装简单,基于 JSON 配置 | 安装相对复杂,基于 XML 配置 |
| 扩展性 | 支持原生分布式架构,扩展方便 | 通过 SolrCloud 实现分布式架构 |
| 社区支持 | 活跃社区,越来越多的贡献者 | 拥有更成熟的社区,丰富的文档和示例 |
| 配置难度 | 使用 JSON 进行配置,配置文件较为简洁 | XML 配置,配置文件较为复杂,适合需要精细控制的场景 |
| 应用场景 | 适合实时搜索、日志分析、系统监控 | 适合复杂查询和对搜索引擎功能进行自定义控制的场景 |
选择 ElasticSearch 还是 Solr?
- 如果需要处理 实时数据分析,并且需要分布式环境的良好伸缩性,ElasticSearch 是更好的选择。
- 如果需要对搜索结果的排序和查询功能进行深度定制,或者需要更复杂的配置,Solr 可能是更好的选择。
ElasticSearch 由于其简单的安装和使用,受到越来越多开发者的青睐。特别是在实时日志分析和监控领域,ElasticSearch 具有显著优势。
# 5. ElasticSearch 的基础概念
ElasticSearch 提供强大的分布式搜索和分析引擎,它使用结构化和半结构化的数据进行高效的存储、查询与索引。为了更直观地理解 ElasticSearch 的概念,我们将其与关系型数据库中的概念进行对比。
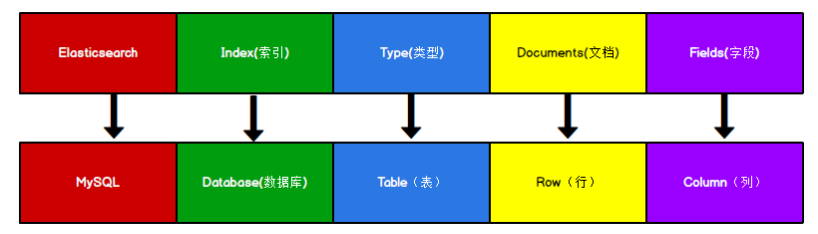
ElasticSearch 没有传统关系型数据库中的“表”这一概念。相反,ElasticSearch 使用 索引(Index) 来组织数据,每个索引包含多个 文档(Document),每个文档又由多个 字段(Field) 组成。
在关系型数据库中,数据是按照 数据库(Database) -> 表(Table) -> 行(Row) -> 列(Column) 的层级结构组织的。而在 ElasticSearch 中,数据结构如下:
- 索引(Index):相当于关系型数据库中的 数据库(Database)。
- 文档(Document):相当于 行(Row)。
- 字段(Field):相当于 列(Column)。
需要特别注意的是,早期版本的 ElasticSearch 引入了 类型(Type) 的概念,一个索引可以包含多个类型,每个类型下有各自的文档,类似于数据库中的表。但从 ElasticSearch 6.x 开始,官方逐步废弃了类型的概念,7.x 版本中已经完全移除了类型。这意味着在当前的 ElasticSearch 版本中,一个索引只能包含一种类型的文档,不再有类似“表”的层级。
因此,在最新版本的 ElasticSearch 中,没有“表”的概念,数据是直接存储在索引中的文档里,通过字段来组织和查询数据。
# 1. 集群(Cluster)
集群 是一个或多个 ElasticSearch 节点的集合,负责协调和处理数据存储、索引和查询操作。每个集群都有一个唯一的名称,默认名称为 elasticsearch。集群内的所有节点共享数据和负载,能够通过水平扩展提供高可用性和分布式处理能力。
- 集群名称 是区分多个 ElasticSearch 集群的标识。在生产环境中,不同的集群应该使用不同的名称,以免节点误加入错误的集群。
# 2. 节点(Node)
节点 是 ElasticSearch 集群中的一个实例,负责处理数据存储和查询任务。一个节点可以存储数据并且负责执行索引和查询等操作。
- 节点角色:每个节点可以承担不同的角色,如主节点、数据节点、协调节点等,这些角色决定了节点在集群中的任务分配。
- 主节点:负责管理集群状态和分片分配。
- 数据节点:负责存储数据和处理搜索请求。
- 协调节点:仅用于转发请求,不存储数据。
# 3. 索引(Index)
索引 是 ElasticSearch 中存储数据的逻辑单位,类似于关系型数据库中的数据库。每个索引包含多个文档,并且支持对不同类型的数据进行搜索和查询操作。
- 索引的特点:一个索引可以理解为类似于关系数据库中的“数据库”概念,但 ElasticSearch 的索引更侧重于高效的全文检索和快速查询。
- 索引生命周期管理:通过设置索引的生命周期策略,ElasticSearch 可以自动管理索引的创建、归档、删除等操作。
# 4. 文档(Document)
文档 是 ElasticSearch 中的最小数据单元,类似于关系数据库中的表中的一行数据。每个文档都是一个 JSON 对象,包含多个字段(Field),这些字段用于存储实际的数据。
- 文档结构:每个文档可以包含多个字段,字段的数据类型可以是字符串、数字、布尔值等。
文档示例:
{
"user": "john_doe",
"post_date": "2024-08-21",
"message": "Hello, ElasticSearch!"
}
2
3
4
5
# 5. 分片(Shard)
分片 是 ElasticSearch 将索引中的数据分割为多个部分来存储的基本单位。分片使得 ElasticSearch 可以水平扩展,将数据分布到多个节点上,实现负载均衡和高可用性。
- 主分片:每个索引默认分为若干个主分片,负责存储原始数据。
- 副本分片:主分片的副本,用于提高系统的容错能力。副本分片可以在主分片不可用时代替其工作,确保数据的高可用性。
分片示例:
- 假设一个索引有 5 个主分片和 1 个副本分片,那么总共有 10 个分片:5 个主分片和 5 个副本分片。
# 6. 近实时性(NRT)
ElasticSearch 是一个近实时(Near Real-Time)的搜索引擎。数据在被索引后,并不会立即可以查询,而是有一个短暂的延迟,通常几秒钟以内。虽然 ElasticSearch 的索引速度非常快,但它并不是一个严格意义上的实时系统。
# 7. 映射(Mapping)
映射(Mapping) 是定义 ElasticSearch 中文档结构的过程,类似于关系型数据库中的表结构定义。它规定了文档中每个字段的名称和数据类型。
- 自动映射:ElasticSearch 可以在首次索引文档时自动推断字段的数据类型。
- 手动映射:为了精确控制字段的索引方式和数据类型,可以提前定义文档的映射。
常见数据类型:
- 文本类型:
text(用于全文检索)、keyword(用于精确匹配) - 数字类型:
integer、float、double、long - 日期类型:
date - 布尔类型:
boolean - 对象类型:
object(嵌套文档)
映射示例:
{
"mappings": {
"properties": {
"user": {
"type": "keyword"
},
"post_date": {
"type": "date"
},
"message": {
"type": "text"
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
在这个示例中,user 字段是 keyword 类型,用于精确搜索;post_date 是 date 类型,用于日期查询;message 是 text 类型,用于全文检索。
# 8. 索引与关系型数据库的对比
| ElasticSearch 概念 | 关系型数据库对比 |
|---|---|
| 集群(Cluster) | 数据库实例 |
| 索引(Index) | 数据库 |
| 文档(Document) | 数据库中的行 |
| 字段(Field) | 表中的列 |
| 映射(Mapping) | 表结构定义 |
| 分片(Shard) | 数据库分区 |
# 6. ElasticSearch 的应用案例
ElasticSearch 被广泛应用于各个行业的实际业务场景中。以下是一些知名企业如何使用 ElasticSearch 进行数据处理和搜索的案例:
GitHub
GitHub 在 2013 年弃用了 Solr,转而使用 ElasticSearch 进行代码搜索。GitHub 的 ElasticSearch 实例每天处理超过 20TB 的数据,包括 13 亿个文件和 1300 亿行代码。
维基百科
维基百科使用 ElasticSearch 作为其核心搜索引擎,为全球用户提供快速、精准的内容检索。
百度
百度广泛使用 ElasticSearch 进行 日志分析 和 文本数据处理,通过 ElasticSearch 收集和分析服务器上的各类指标数据及用户自定义数据。其集群最大规模可达 100 台机器,200 个 ES 节点,每天处理超过 30TB 的数据。
阿里巴巴
阿里巴巴使用 ElasticSearch 构建其日志采集和分析体系,支持大规模日志的实时采集、处理和分析。
总结
ElasticSearch 是一个强大的分布式搜索和分析引擎,凭借其灵活性、扩展性和易用性,被广泛应用于多个行业和领域。无论是日志分析、系统监控还是全文搜索,ElasticSearch 都能提供高效的解决方案。
通过掌握 ElasticSearch 的核心概念和其工作原理,开发者可以在实际项目中充分发挥 ElasticSearch 的优势,处理复杂的数据搜索与分析任务。