 JVM - 垃圾回收相关算法
JVM - 垃圾回收相关算法
# 1. 垃圾回收阶段概述:标记与清除
Java 堆是 JVM 中存储对象实例的主要场所。随着程序的运行,对象不断被创建,当某些对象不再被使用时,它们就变成了“垃圾”,占据着宝贵的内存资源。垃圾回收 (GC) 机制的核心任务就是识别并清除这些垃圾,以便为新对象腾出空间。这个过程大致可以分为两个主要阶段:标记阶段和清除阶段。
# 标记阶段 (Marking Phase)
在执行垃圾回收之前,GC 首先需要准确地区分出哪些对象是存活的 (Live Objects),哪些是已经死亡的 (Dead Objects)。只有被识别为死亡的对象,才应该被回收。这个识别过程就是垃圾标记阶段。
核心问题:JVM 如何判断一个对象是否“死亡”? 基本原则是:当一个对象不再被任何存活的对象或根引用 (GC Roots) 所指向时,它就符合被回收的条件。
目前主流的垃圾标记算法有两种:引用计数算法和可达性分析算法。
# 2. 标记阶段算法一:引用计数算法 (Reference Counting)
# 2.1 算法原理
引用计数算法是一种相对简单的标记策略。它为每个对象维护一个整型的引用计数器 (Reference Counter) 属性。
- 计数增加: 当有一个引用指向该对象时,其引用计数器加 1。
- 计数减少: 当指向该对象的引用失效(例如,引用变量被赋值为
null或超出了作用域)时,其引用计数器减 1。 - 垃圾判断: 当一个对象的引用计数器值为 0 时,就认为该对象不再被使用,可以被回收。
# 2.2 优点
- 实现简单: 算法逻辑直观易懂。
- 判定效率高: 判断对象是否为垃圾非常快,只需检查计数器是否为 0。
- 回收无延迟: 一旦对象计数器变为 0,理论上可以立即回收(但实际回收时机仍由 GC 决定)。
# 2.3 缺点
尽管有优点,但引用计数算法并未被现代 Java 虚拟机(如 HotSpot)采用,主要因为它存在以下致命缺陷:
- 空间开销: 需要为每个对象额外存储一个引用计数器,增加了内存空间的消耗。
- 时间开销: 每次引用的创建和销毁都需要更新计数器,涉及加减法操作,增加了运行时间开销。
- 无法处理循环引用 (Circular References): 这是最严重的问题。如果两个或多个对象相互引用,即使它们已经没有任何外部引用(即从 GC Roots 不可达),它们的引用计数器也永远不会变为 0,导致这些对象永远无法被回收,造成内存泄漏。
循环引用图示:
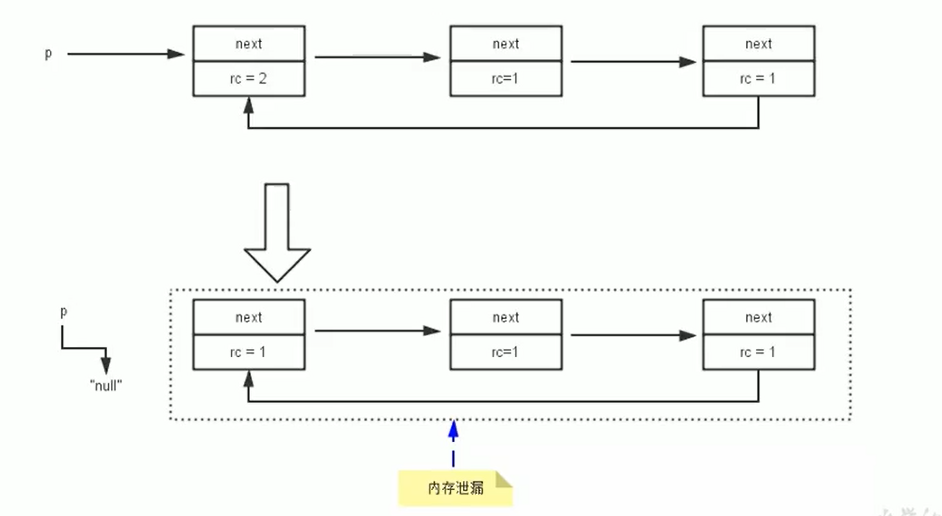 (图中,即使外部引用
(图中,即使外部引用 p 断开,对象 A 和 B 仍然相互引用,计数器不为 0,无法回收)
# 2.4 实验验证:Java 是否使用引用计数?
可以通过一个简单的实验来验证 Java 是否采用引用计数。
// 文件名: RefCountGC.java
/**
* 测试 Java 是否使用引用计数算法进行垃圾标记。
* 该算法的主要缺陷是无法处理循环引用。
*/
public class RefCountGC {
// 实例变量:占用 5MB 内存,便于观察 GC 效果
private byte[] bigSize = new byte[5 * 1024 * 1024]; // 5MB
// 实例变量:用于持有另一个对象的引用
Object reference = null;
public static void main(String[] args) {
// 创建两个 RefCountGC 对象实例
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
// 让 obj1 和 obj2 相互引用,形成循环引用
obj1.reference = obj2;
obj2.reference = obj1;
// 断开外部引用:将 obj1 和 obj2 变量置为 null
// 如果是引用计数,此时 obj1 和 obj2 对象的计数器仍然是 1(因为内部互相引用),不应被回收
obj1 = null;
obj2 = null;
// 手动建议 JVM 执行垃圾收集
// 观察 obj1 和 obj2 指向的对象是否被回收
System.gc();
// 可以添加断点或休眠来观察内存变化或等待 GC 日志
try {
Thread.sleep(1000); // 短暂休眠,给 GC 一点时间
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("GC 执行完毕(可能)");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
运行并观察 GC 日志 (需要添加 -XX:+PrintGCDetails 参数):
[GC (System.gc()) [PSYoungGen: 15490K->808K(76288K)] 15490K->816K(251392K), 0.0061980 secs] [Times: user=0.00 sys=0.00, real=0.36 secs]
[Full GC (System.gc()) [PSYoungGen: 808K->0K(76288K)] [ParOldGen: 8K->672K(175104K)] 816K->672K(251392K), [Metaspace: 3479K->3479K(1056768K)], 0.0045983 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
Heap
PSYoungGen total 76288K, used 655K ...
eden space 65536K, 1% used ...
from space 10752K, 0% used ...
to space 10752K, 0% used ...
ParOldGen total 175104K, used 672K ...
object space 175104K, 0% used ...
Metaspace used 3486K, capacity 4496K ...
class space used 385K, capacity 388K ...
GC 执行完毕(可能)
2
3
4
5
6
7
8
9
10
11
12
结果分析:
从 GC 日志中 PSYoungGen: 15490K->808K 和后续 Full GC 中 PSYoungGen: 808K->0K 可以看到,新生代中的内存(大约 10MB+,对应两个 bigSize 数组)被成功回收了。这表明即使 obj1 和 obj2 存在循环引用,它们最终还是被判定为垃圾并回收了。
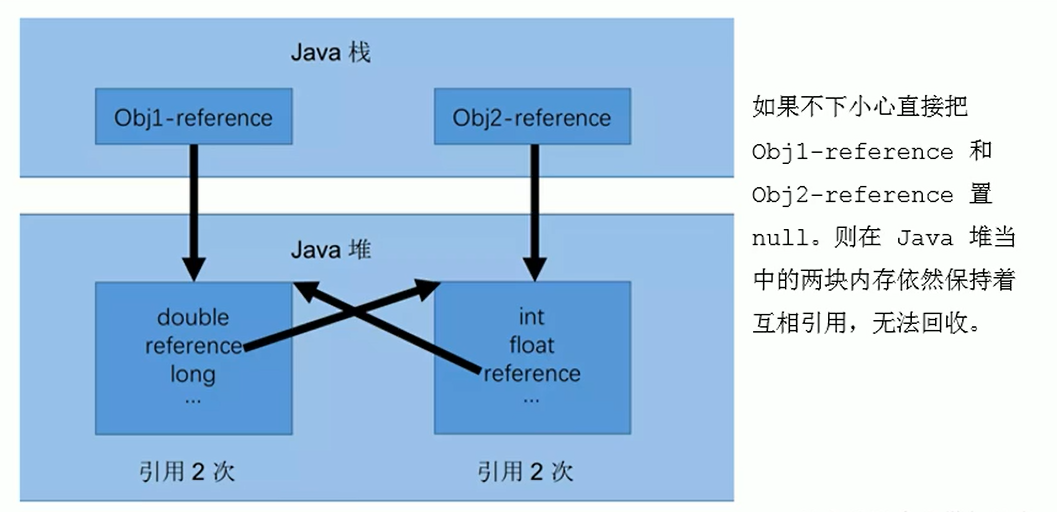
结论: 实验证明,Java 没有采用引用计数算法。否则,循环引用的 obj1 和 obj2 对象将无法被回收。
# 2.5 其他语言与引用计数
- Python: 同时使用了引用计数(作为主要机制)和垃圾收集(用于检测和回收循环引用的垃圾)。Python 解决循环引用的方法包括:
- 手动解除引用: 开发者在代码中显式断开循环。
- 弱引用 (weakref): 使用标准库
weakref创建弱引用,弱引用不增加对象的引用计数,从而可以打破循环。
- 其他: Objective-C/Swift (早期依赖手动管理和 ARC - 自动引用计数), PHP (早期也用引用计数)。
引用计数在特定场景下有其优势(如实时性),但循环引用是其普遍难题。
# 3. 标记阶段算法二:可达性分析算法 (Reachability Analysis)
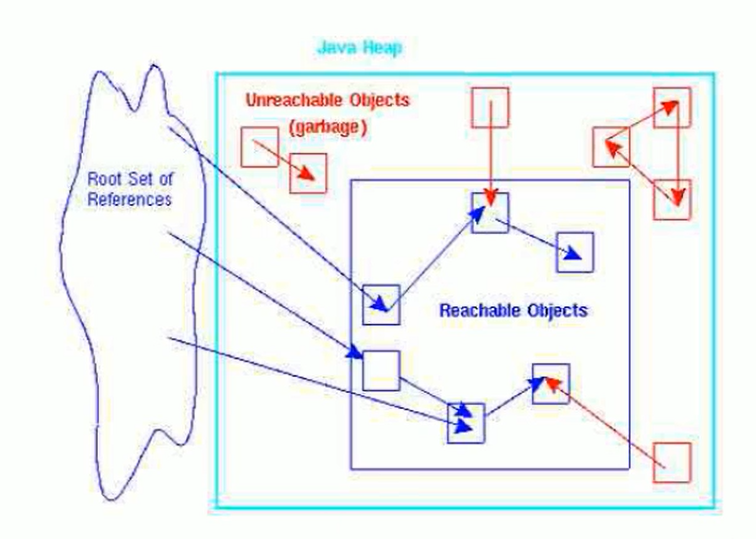
可达性分析算法是目前 Java、C# 等主流语言采用的垃圾标记算法,也称为根搜索算法 (GC Roots Tracing) 或追踪性垃圾收集 (Tracing Garbage Collection)。
# 3.1 核心思想
- 定义 GC Roots: 首先确定一系列必须存活的根对象 (GC Roots) 集合。这些对象是程序运行的基础,不能被回收。
- 构建引用链: 从 GC Roots 出发,沿着对象之间的引用关系向下搜索,遍历所有可以直接或间接通过引用链访问到的对象。这个搜索路径称为引用链 (Reference Chain)。
- 标记存活对象: 所有能够通过引用链从 GC Roots 到达的对象,都被标记为存活对象 (Reachable Objects)。
- 识别垃圾对象: 在搜索完成后,所有未被标记(即从 GC Roots 出发不可达)的对象,都被判定为垃圾对象 (Unreachable Objects),可以被回收。
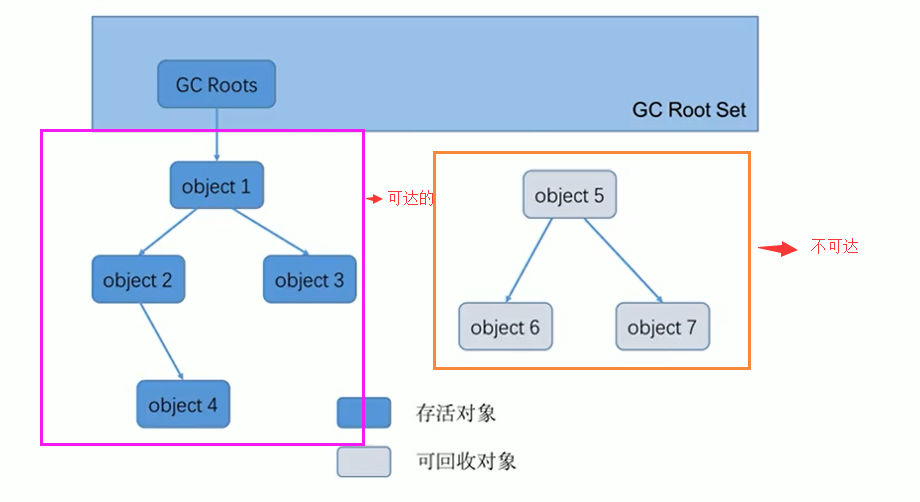 (图中 Object 6, 7, 8 因为无法从 GC Roots 到达,被视为垃圾)
(图中 Object 6, 7, 8 因为无法从 GC Roots 到达,被视为垃圾)
类比理解: 想象一个关系网(对象引用关系),GC Roots 就是网络中的核心人物。所有能通过关系链(引用链)联系到核心人物的人(对象)都是“活跃”的(存活的),而那些与核心人物失去联系(不可达)的人(对象)则被视为“脱离关系网”(垃圾)。
# 3.2 优点
- 实现相对简单,执行高效。
- 有效解决循环引用问题: 即使对象之间存在循环引用,只要它们整体从 GC Roots 不可达,就会被判定为垃圾。
# 3.3 哪些对象可以作为 GC Roots?
GC Roots 是可达性分析的起点,它们本身必须是存活的。常见的 GC Roots 包括:
- 虚拟机栈 (Stack) 中引用的对象:
- 当前所有活动线程的栈帧中的局部变量表所引用的对象。例如,方法参数、方法内定义的局部变量。
- 本地方法栈 (Native Stack) 中 JNI 引用的对象:
- 通过 Java Native Interface (JNI) 调用本地方法 (Native Method) 时,本地代码(如 C/C++)持有的 Java 对象引用。
- 方法区 (Method Area) 中类静态属性引用的对象:
- Java 类的静态成员变量 (static fields) 所引用的对象。
- 方法区 (Method Area) 中常量引用的对象:
- 字符串常量池 (String Table) 中缓存的字符串对象引用。
- (理论上可能包括其他常量引用,但字符串常量池最典型)。
- 所有被同步锁 (
synchronized关键字) 持有的对象:- 为了保证锁的正确性,作为锁对象本身不能被回收。
- Java 虚拟机内部的引用:
- 如基本数据类型对应的
Class对象(例如int.class)。 - 一些常驻的异常对象实例(例如
NullPointerException,OutOfMemoryError的单例)。 - 系统类加载器 (System ClassLoader)。
- 如基本数据类型对应的
- 反映 JVM 内部情况的对象:
- 如 JMXBean、JVMTI 中注册的回调、本地代码缓存等。
总结 GC Roots 来源: 主要来自堆外(栈、方法区、本地方法栈等)指向堆内对象的引用。
临时性 GC Roots: 在进行分代收集 (Generational GC) 或局部回收 (Partial GC)(例如只回收新生代)时,除了上述固定的 GC Roots,还需要临时地将其他区域指向被回收区域的引用也加入 GC Roots 集合。例如,在回收新生代时,需要考虑老年代中是否有对象引用了新生代的对象,这些老年代对象(或者更精确地说,是它们指向新生代对象的引用)也需要被当作临时的 GC Roots,以保证可达性分析的准确性。
识别小技巧: 如果一个指针/引用,它自身不存储在堆内存中,但它指向了堆内存中的一个对象,那么这个指针/引用很可能就是一个 GC Root。
# 3.4 "Stop-The-World" (STW) 的必要性
为了保证可达性分析结果的准确性,分析过程必须在一个一致性的快照 (Consistent Snapshot) 中进行。如果在分析过程中,应用程序的线程还在并发地运行,不断改变对象间的引用关系,那么分析结果就可能不准确(例如,刚标记为存活的对象可能下一刻就断开了引用,或者刚标记为垃圾的对象又被重新引用)。
因此,在执行可达性分析(主要是枚举根节点这个阶段)时,必须暂停所有用户线程,即发生 "Stop-The-World" (STW)。这是导致 GC 停顿的一个主要原因。即使是像 CMS、G1 这样以并发处理见长的收集器,在初始标记 (Initial Mark) 等阶段也需要短暂的 STW 来确保根节点枚举的准确性。
# 4. 对象的 finalization 机制
Java 提供了一种特殊的机制,允许对象在被垃圾回收之前执行一些自定义的清理操作,这就是 finalization 机制,通过重写 Object 类的 finalize() 方法实现。
# 4.1 finalize() 方法
- 目的: 允许开发人员定义对象在被 GC 回收前的最后清理逻辑,通常用于释放非内存资源(如关闭文件句柄、数据库连接、网络套接字等)。
- 触发时机: 当 GC 确定一个对象从 GC Roots 不可达(第一次标记)后,如果该对象重写了
finalize()方法且尚未被执行过,GC 不会立即回收它,而是将其放入一个特殊的队列 (F-Queue),由一个低优先级的 Finalizer 线程 负责去调用该对象的finalize()方法。 - 生命周期:
finalize()方法的执行是对象逃脱死亡的最后机会。
# 4.2 注意事项与陷阱
强烈不推荐依赖 finalize() 方法进行资源清理,原因如下:
- 执行时机不确定:
finalize()的执行完全由低优先级的 Finalizer 线程和 GC 时机决定,没有任何时间保证。极端情况下,如果 GC 不发生或 Finalizer 线程繁忙,finalize()可能永远不会被调用。 - 可能导致对象“复活”: 在
finalize()方法内部,可以将this对象重新赋值给某个 GC Root 可达的引用(例如静态变量),使得该对象在第二次标记时变得可达,从而“复活”,避免了本次回收。 finalize()只会被调用一次: 即使对象复活了,当它再次变得不可达时,其finalize()方法不会被再次调用。- 影响 GC 性能:
finalize()的执行过程(入队、线程调用)本身有开销。如果finalize()方法执行缓慢或发生阻塞,会严重拖慢 Finalizer 线程,可能导致 F-Queue 堆积,影响整个 GC 系统的效率,甚至引发 OOM。 - 非必要性: Java 7 引入了
try-with-resources语句,Java 9 引入了CleanerAPI,它们提供了更可靠、更及时、更高效的资源管理方式,完全可以替代finalize()的功能。
结论: 永远不要主动调用 任何对象的 finalize() 方法,并且尽量避免重写 finalize() 方法来进行资源管理。优先使用 try-with-resources 或 Cleaner。
# 4.3 对象的三种状态
由于 finalize() 机制的存在,一个对象在 JVM 中可能处于以下三种状态:
- 可触及的 (Reachable): 从 GC Roots 出发,存在有效的引用链可以到达该对象。这是对象的正常存活状态。
- 可复活的 (Finalizable): 对象的所有直接引用都已断开(从 GC Roots 不可达),但该对象重写了
finalize()方法且尚未被执行。此时对象处于“缓刑”状态,等待 Finalizer 线程调用其finalize()方法。在finalize()方法中有机会“复活”(重新建立与 GC Roots 的连接)。 - 不可触及的 (Unreachable):
- 对象从 GC Roots 不可达,且没有重写
finalize()方法。 - 对象从 GC Roots 不可达,重写了
finalize()方法,但该方法已经被调用过一次。 - 对象在
finalize()方法执行后,未能成功复活。 处于不可触及状态的对象,将在后续的 GC 清除阶段被回收。一旦进入不可触及状态,对象不可能再复活。
- 对象从 GC Roots 不可达,且没有重写
# 4.4 对象的标记与复活过程
判断一个对象是否可回收,至少需要经历两次标记过程:
- 第一次标记: 执行可达性分析,找出所有从 GC Roots 不可达的对象,进行第一次标记。
- 筛选与
finalize()处理:- 对第一次标记的对象进行筛选,判断是否有必要执行
finalize()方法。 - 没必要执行的情况:
- 对象没有重写
finalize()。 - 对象的
finalize()已经被 JVM 调用过。 这些对象直接被判定为不可触及。
- 对象没有重写
- 有必要执行的情况:
- 对象重写了
finalize()且尚未执行。 这些对象会被放入 F-Queue 队列。
- 对象重写了
- 对第一次标记的对象进行筛选,判断是否有必要执行
finalize()调用与第二次标记:- 低优先级的 Finalizer 线程会从 F-Queue 中取出对象并调用其
finalize()方法。注意:JVM 只保证调用,不保证方法执行完毕。 - 在
finalize()方法执行期间或之后,GC 会对 F-Queue 中的对象(或说刚执行完finalize的对象)进行第二次标记。 - 复活: 如果在
finalize()中,对象成功地将自己重新连接到任何一个 GC Roots 引用链上(例如GC_Roots.someStaticField = this;),那么在第二次标记时它会被识别为可达对象,从而被移出“即将回收”的集合,成功复活。 - 未复活: 如果
finalize()执行完毕后,对象仍然不可达,那么它将被最终判定为不可触及,等待被回收。
- 低优先级的 Finalizer 线程会从 F-Queue 中取出对象并调用其
 (图中展示了 Finalizer 线程)
(图中展示了 Finalizer 线程)
# 4.5 代码演示 finalize() 复活与一次性
// 文件名: CanReliveObj.java
/**
* 测试对象的 finalization 机制,特别是 finalize() 方法的复活效果及其一次性。
*/
public class CanReliveObj {
// 类变量,作为 GC Root,用于在 finalize 中重新建立引用
public static CanReliveObj obj;
// 重写 finalize 方法,尝试在被回收前“自救”
@Override
protected void finalize() throws Throwable {
super.finalize(); // 调用父类 finalize (好习惯)
System.out.println("调用当前类重写的 finalize() 方法");
// 在 finalize 中,将当前即将被回收的对象重新赋值给静态变量 obj
// 这样就重新建立了与 GC Root 的连接
obj = this;
System.out.println("finalize() 中: obj is assigned to this");
}
public static void main(String[] args) {
try {
// 1. 创建对象
obj = new CanReliveObj();
System.out.println("初始创建: obj = " + obj);
// 2. 第一次尝试回收:断开引用,建议 GC
obj = null; // 断开静态变量 obj 对对象的引用
System.gc(); // 建议 JVM 进行垃圾回收
System.out.println("第1次 gc 建议发出");
// 因为 Finalizer 线程优先级低,需要等待一段时间让它有机会执行 finalize()
Thread.sleep(2000); // 等待 2 秒
// 检查对象是否复活
if (obj == null) {
System.out.println("第1次 gc 后: obj is dead");
} else {
System.out.println("第1次 gc 后: obj is still alive. obj = " + obj); // 应该能复活
}
System.out.println("---");
// 3. 第二次尝试回收:再次断开引用,建议 GC
obj = null; // 再次断开引用
System.gc(); // 再次建议 GC
System.out.println("第2次 gc 建议发出");
// 再次等待 Finalizer 线程(但 finalize 不会再被调用)
Thread.sleep(2000);
// 检查对象是否最终被回收
if (obj == null) {
System.out.println("第2次 gc 后: obj is dead"); // finalize 只调用一次,这次应该死亡
} else {
// 如果还能执行到这里,说明 finalize 被调用了多次,这不符合规范
System.out.println("第2次 gc 后: obj is still alive. obj = " + obj);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
运行结果 (取消 finalize() 注释):
初始创建: obj = CanReliveObj@... // 对象地址
第1次 gc 建议发出
调用当前类重写的 finalize() 方法
finalize() 中: obj is assigned to this
第1次 gc 后: obj is still alive. obj = CanReliveObj@... // 对象成功复活
---
第2次 gc 建议发出
第2次 gc 后: obj is dead // finalize 不会再次调用,对象被回收
2
3
4
5
6
7
8
如果注释掉 finalize() 方法,运行结果:
初始创建: obj = CanReliveObj@...
第1次 gc 建议发出
第1次 gc 后: obj is dead // 没有 finalize,直接被回收
---
第2次 gc 建议发出
第2次 gc 后: obj is dead // 已经是 null 了
2
3
4
5
6
实验清晰地展示了 finalize() 方法可以使对象“复活”一次,但仅有一次机会。
# 5. 使用 MAT 与 JProfiler 进行 GC Roots 溯源
理解了 GC Roots 的概念后,可以使用内存分析工具来实际查看哪些对象是 GC Roots,以及某个对象为何没有被回收(即查找其到 GC Roots 的引用链)。
# 5.1 MAT (Memory Analyzer Tool)
- 简介: Eclipse 出品的免费、强大的 Java 堆内存分析器,用于查找内存泄漏、分析内存消耗。
- 下载: http://www.eclipse.org/mat/ (opens new window)
# 5.2 获取 Heap Dump 文件
Heap Dump 是某个时间点 Java 堆内存的快照。获取方式有多种:
jmap 命令: JDK 自带命令行工具。
jmap -dump:format=b,file=<filename.hprof> <pid>1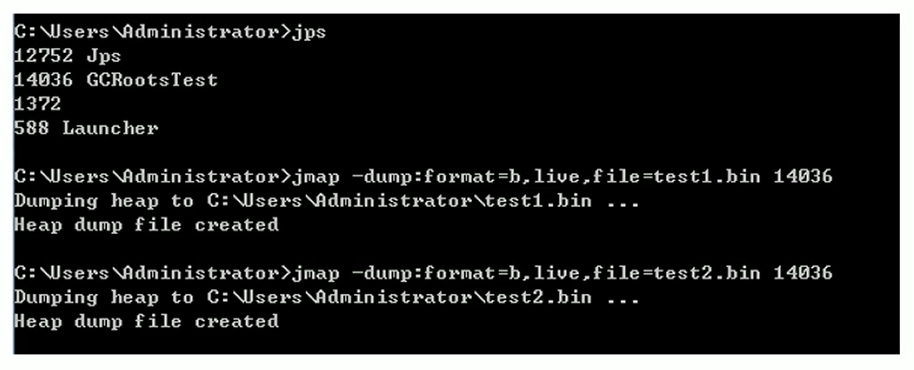
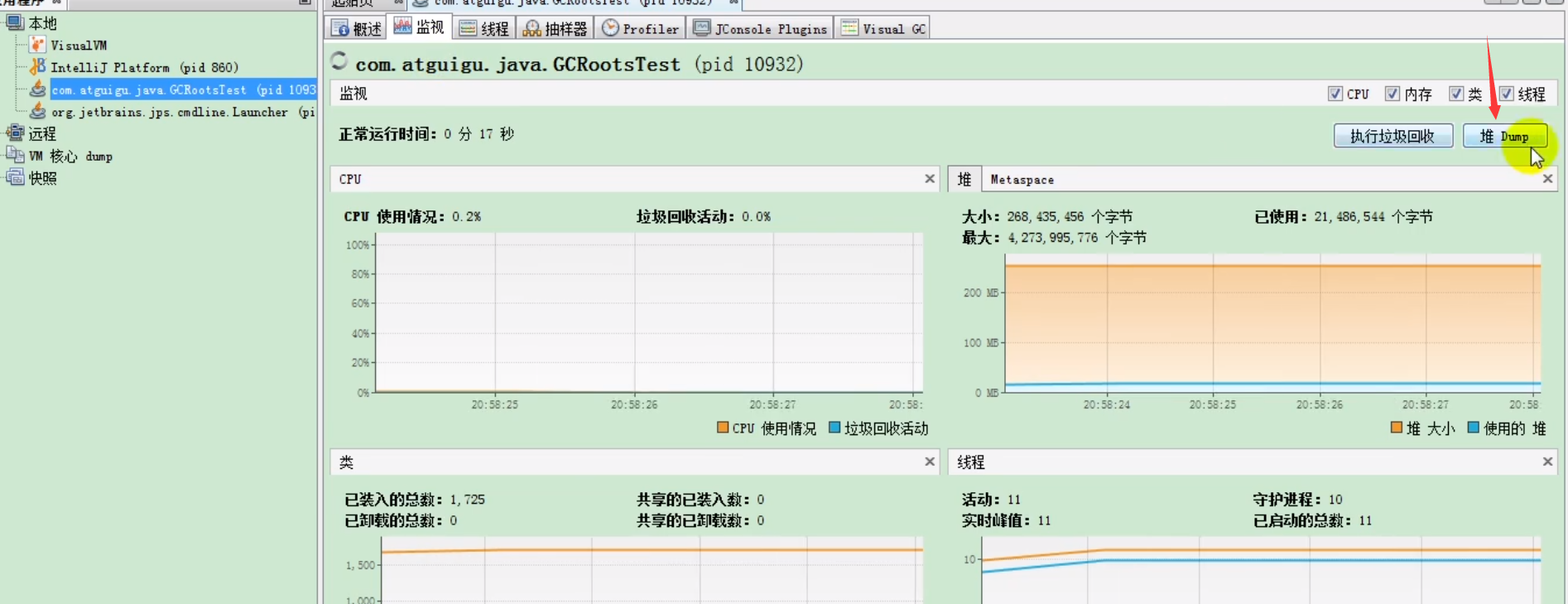
JVisualVM: JDK 自带 GUI 监控工具。
- 连接到目标 Java 进程。
- 在“监视 (Monitor)”标签页点击“堆 Dump (Heap Dump)”按钮。
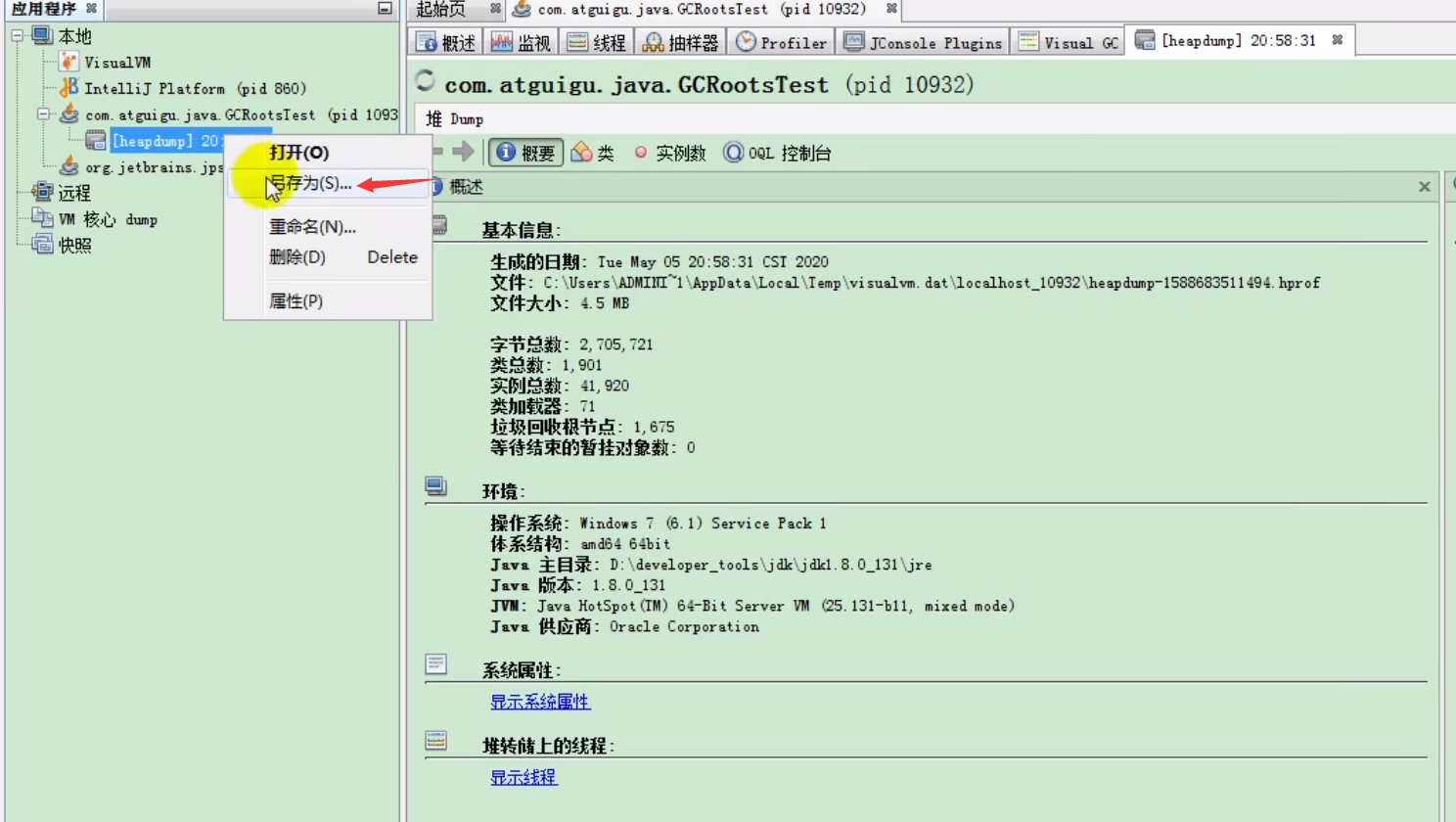
- 或者在左侧应用程序列表右击进程 -> “堆 Dump”。
- 生成的 Dump 文件会在 JVisualVM 中打开一个新标签页,可以右击选择“另存为”保存到本地。
JVM 参数:
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=<path>,在发生 OOM 时自动生成 Dump 文件。
# 5.3 使用 MAT 分析 GC Roots
示例代码 (GCRootsTest.java):
// 文件名: GCRootsTest.java
import java.util.ArrayList;
import java.util.Date;
import java.util.List;
import java.util.Scanner;
/**
* 演示 GC Roots 的变化
*/
public class GCRootsTest {
public static void main(String[] args) {
// 创建列表和日期对象,由 main 线程栈帧中的局部变量引用
List<Object> numList = new ArrayList<>();
Date birth = new Date();
// 向列表中添加一些对象(字符串)
for (int i = 0; i < 100; i++) {
numList.add(String.valueOf(i));
try {
Thread.sleep(10); // 短暂休眠
} catch (InterruptedException e) {
e.printStackTrace();
}
}
System.out.println("数据添加完毕,请操作(此时 numList 和 birth 是 GC Roots)...");
// 暂停,等待用户操作(例如生成第一个 Heap Dump)
new Scanner(System.in).next();
// 将局部变量置为 null,断开引用
numList = null;
birth = null;
System.out.println("numList、birth 已置空,请操作(此时它们不再是 GC Roots 了)...");
// 再次暂停,等待用户操作(例如生成第二个 Heap Dump)
new Scanner(System.in).next();
System.out.println("结束");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
操作步骤:
- 运行
GCRootsTest.java。 - 当看到 "数据添加完毕,请操作..." 时,使用 JVisualVM 生成第一个 Heap Dump 文件 (
dump1.hprof) 并保存。 - 在程序控制台输入任意字符并回车,程序继续执行。
- 当看到 "numList、birth 已置空,请操作..." 时,生成第二个 Heap Dump 文件 (
dump2.hprof) 并保存。 - 打开 MAT 工具。
- 分析 dump1.hprof:
File->Open Heap Dump...选择dump1.hprof。- 在 Overview 页面,选择
Java Basics->GC Roots。 - 可以看到 GC Roots 列表中包含了线程
main的栈帧中引用的ArrayList(numList) 和Date(birth) 对象。总条目数例如是 21。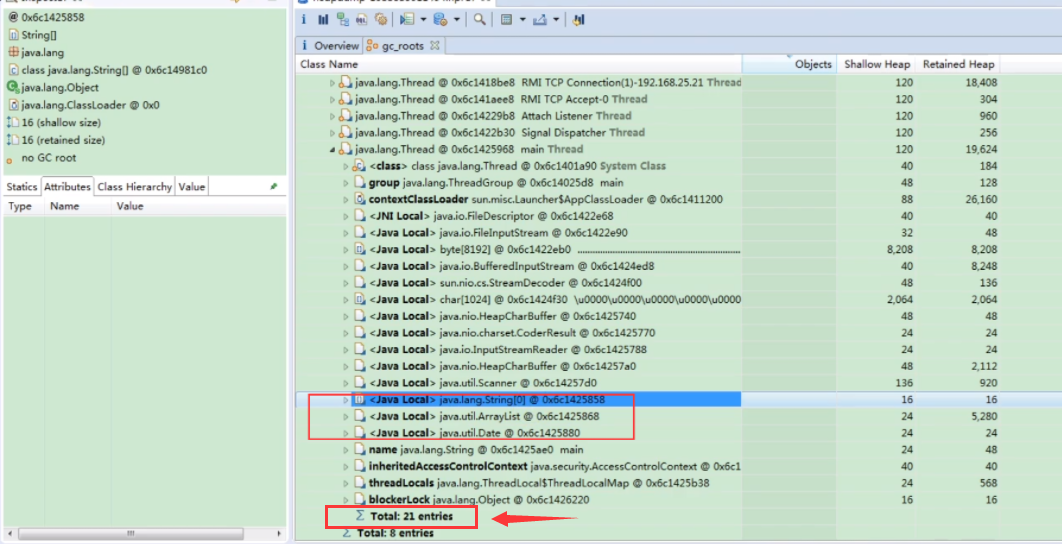
- 分析 dump2.hprof:
- 打开
dump2.hprof。 - 同样进入
GC Roots视图。 - 此时,列表中应该不再包含
ArrayList和Date对象(因为局部变量引用已断开)。总条目数会减少,例如变成 19。
- 打开
# 5.4 JProfiler 进行 GC Roots 溯源
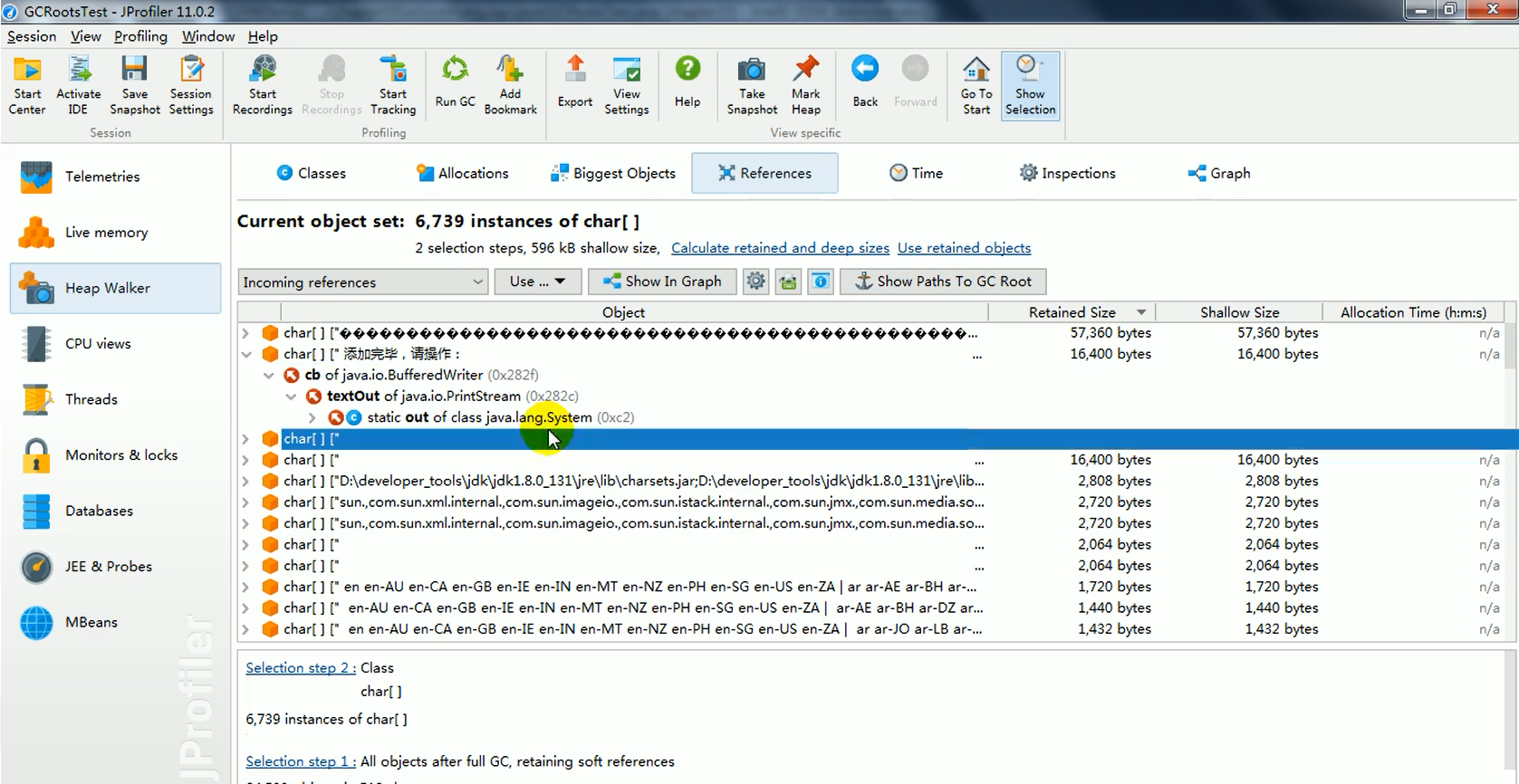
JProfiler 是另一款强大的商业性能分析工具。它提供了更直观的方式来查看某个特定对象到 GC Roots 的引用路径(即为什么这个对象没有被回收)。
- 在 JProfiler 的内存视图中,可以选中某个对象。
- 右键选择
Show Paths to GC Root或类似选项。 - JProfiler 会展示一个清晰的引用链图,从选定对象一直追溯到某个 GC Root。这对于定位内存泄漏非常有用。
# 5.5 使用 MAT 排查 OOM
当程序发生 OOM 并生成了 Heap Dump 文件后,MAT 是排查问题的利器。
示例代码 (HeapOOM.java):
// 文件名: HeapOOM.java
import java.util.ArrayList;
/**
* 模拟堆内存溢出,并生成 Heap Dump 文件
* VM Options: -Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError
*/
public class HeapOOM {
// 每个实例持有 1MB 的 byte 数组
byte[] buffer = new byte[1 * 1024 * 1024];
public static void main(String[] args) {
ArrayList<HeapOOM> list = new ArrayList<>();
int count = 0;
try {
while (true) {
// 不断创建 HeapOOM 对象并加入列表
list.add(new HeapOOM());
count++;
}
} catch (OutOfMemoryError e) { // 捕获 OOM
System.out.println("******** OOM after adding " + count + " objects ********");
// e.printStackTrace(); // OOM 时打印堆栈意义不大,看 dump 文件更重要
} finally {
System.out.println("Final count:" + count);
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
运行与分析:
- 使用 VM 参数
-Xms8m -Xmx8m -XX:+HeapDumpOnOutOfMemoryError运行HeapOOM.java。 - 程序会很快抛出 OOM,并在项目目录下生成一个
.hprof文件(如java_pidxxxx.hprof)。 - 用 MAT 打开这个
.hprof文件。 - 查找主要内存消耗者:
- MAT 可能会自动提示运行 "Leak Suspects Report"(泄漏嫌疑报告),可以运行它。
- 或者手动查看 "Dominator Tree"(支配树视图),按 retained size(持有内存大小)排序,通常能找到占用内存最多的对象。
- 也可以查看 "Top Consumers"(最大消费者报告)。
- 在这个例子中,会发现
ArrayList对象本身及其内部持有的HeapOOM对象(特别是byte[]数组)占用了绝大部分内存。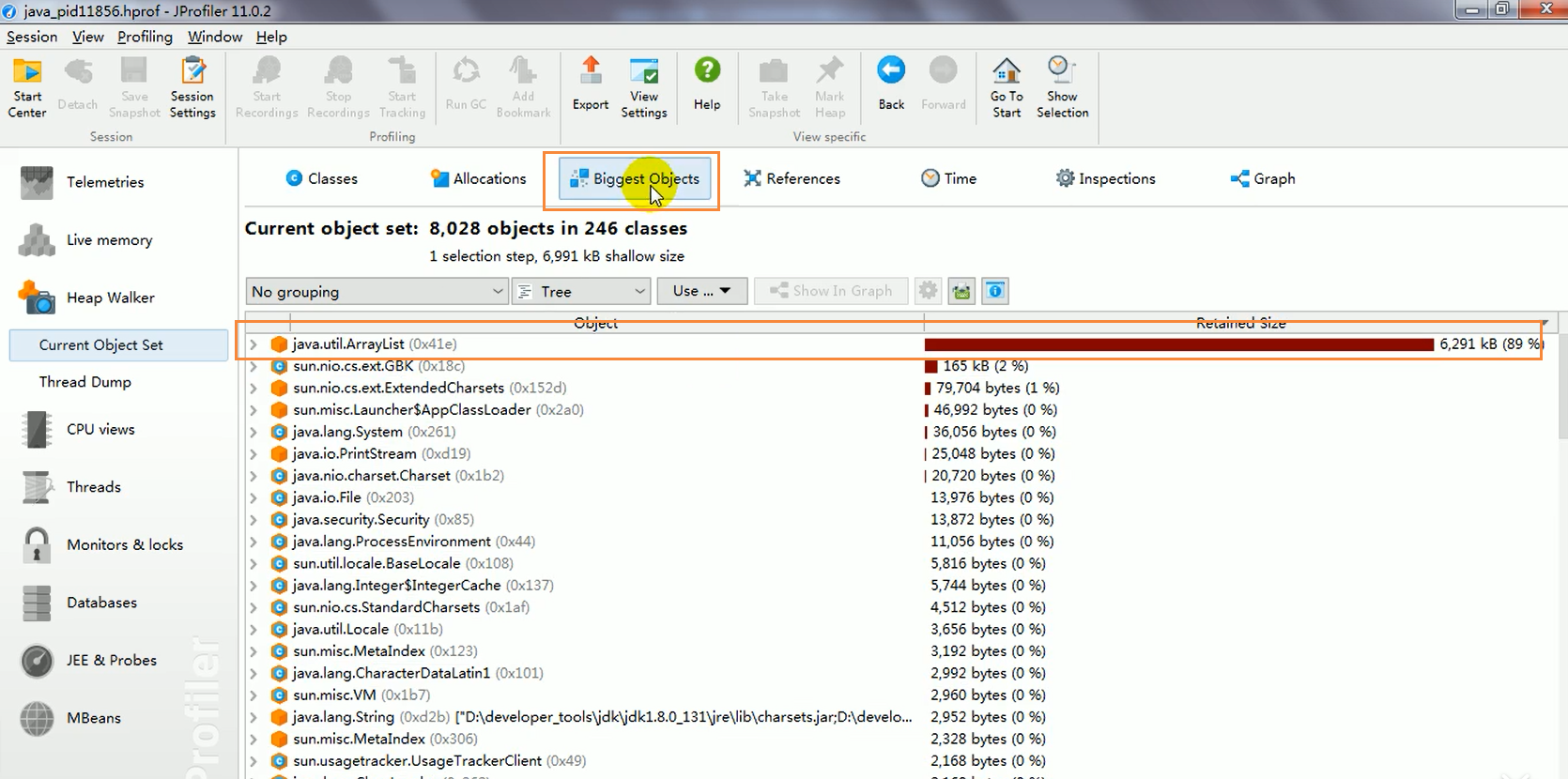
- 定位 OOM 发生线程:
- 在 MAT 中可以查看 "Thread Overview"(线程概览)。
- 通常可以找到抛出 OOM 的那个线程(例如
main线程),并查看其调用栈,找到 OOM 发生的具体代码位置(即list.add(new HeapOOM());这一行)。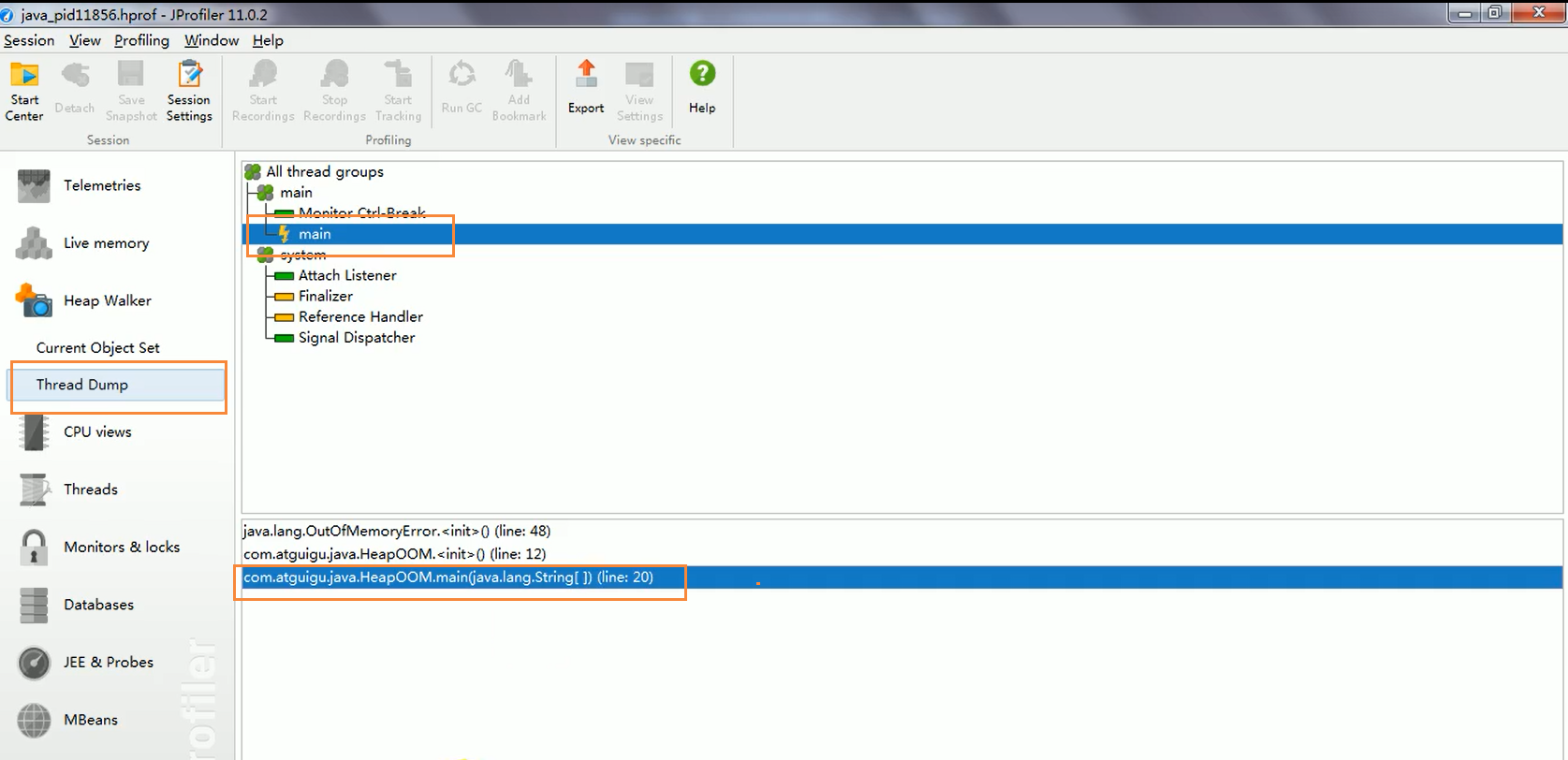
通过这些分析,可以确定是 ArrayList 无限制增长导致持有了过多的 HeapOOM 对象,最终耗尽了堆内存。
# 6. 清除阶段算法概述 (Clearing Phase Algorithms)
在标记阶段(通过可达性分析)区分出存活对象和垃圾对象之后,GC 就进入了清除阶段,需要将垃圾对象所占用的内存空间释放出来,以便后续分配。
目前 JVM 中比较常见的三种垃圾清除算法(通常与标记阶段结合)是:
- 标记-清除算法 (Mark-Sweep)
- 复制算法 (Copying)
- 标记-压缩算法 (Mark-Compact) (也叫标记-整理)
# 7. 清除阶段算法一:标记-清除 (Mark-Sweep)
这是最基础的垃圾收集算法,由 J. McCarthy 等人在 1960 年为 Lisp 语言提出。
# 7.1 执行过程
该算法分为两个阶段:
- 标记 (Mark): 与可达性分析过程一致。从 GC Roots 出发,遍历所有可达对象,并在对象的某个标记位(通常在对象头 Mark Word 中)记录下存活状态。注意:标记的是存活对象,不是垃圾对象。
- 清除 (Sweep): 在标记阶段完成后,GC 遍历整个堆内存区域。对于没有被标记为存活的对象(即垃圾对象),将其占用的内存空间回收。
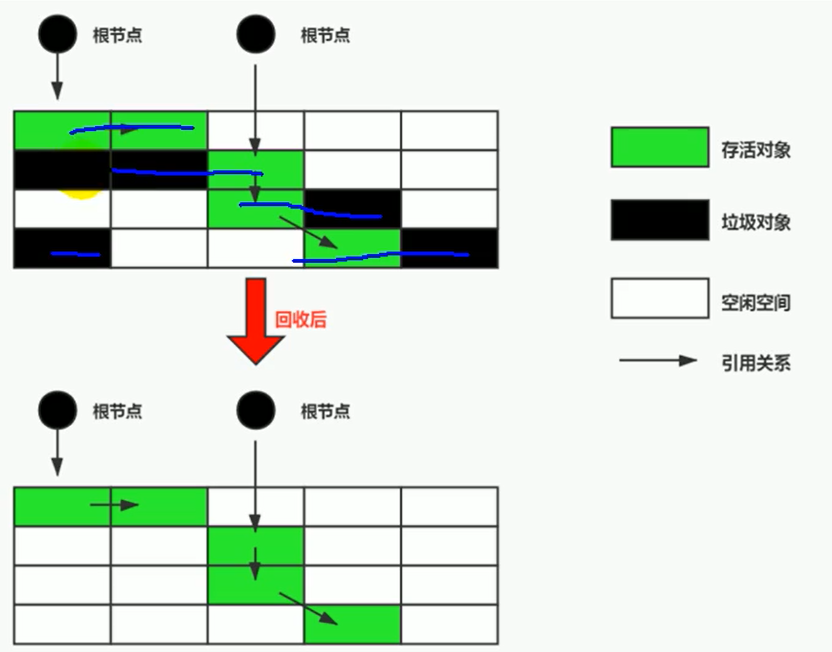 (图示:先标记存活对象,然后清除未标记的对象)
(图示:先标记存活对象,然后清除未标记的对象)
# 7.2 “清除”的含义
这里的“清除”并不是真的将内存区域内容清零,而是将这些可回收的内存块记录到一个空闲列表 (Free List) 中。当后续需要为新对象分配内存时,JVM 会查找这个空闲列表,找到一个大小合适的内存块进行分配。原有的垃圾对象内容,在下次被分配覆盖之前,可能还残留在内存中。
这与前面提到的内存分配方式中的空闲列表分配相对应。
# 7.3 缺点
- 效率问题: 需要执行两次扫描(标记阶段扫描一次,清除阶段扫描一次),效率相对不高。
- STW (Stop-The-World): 在标记和清除两个阶段,通常都需要暂停用户应用程序 (STW),如果堆内存很大,暂停时间可能较长,影响用户体验。
- 内存碎片 (Memory Fragmentation): 这是标记-清除算法最主要的问题。清除后,剩余的空闲内存块往往是不连续的,形成大量内存碎片。这会导致后续需要分配较大连续内存空间(如大数组、大对象)时,即使总空闲内存足够,也可能因为找不到足够大的连续块而分配失败,进而可能提前触发下一次 GC(甚至 Full GC)。
# 8. 清除阶段算法二:复制 (Copying)
复制算法是为了解决标记-清除算法的效率和碎片问题而被提出的。
# 8.1 背景
由 M.L. Minsky 于 1963 年提出,最初应用于 Lisp。
# 8.2 核心思想
- 划分空间: 将可用的堆内存空间按容量划分为大小相等的两块(例如称为 From 空间和 To 空间)。
- 使用一块: 每次只使用其中的一块(例如 From 空间)进行对象分配。To 空间保持空闲。
- GC 发生时: 当 From 空间被占满,触发 GC 时:
- 执行可达性分析,找出 From 空间中的所有存活对象。
- 将这些存活对象****按顺序复制到另一块(To 空间) 上。
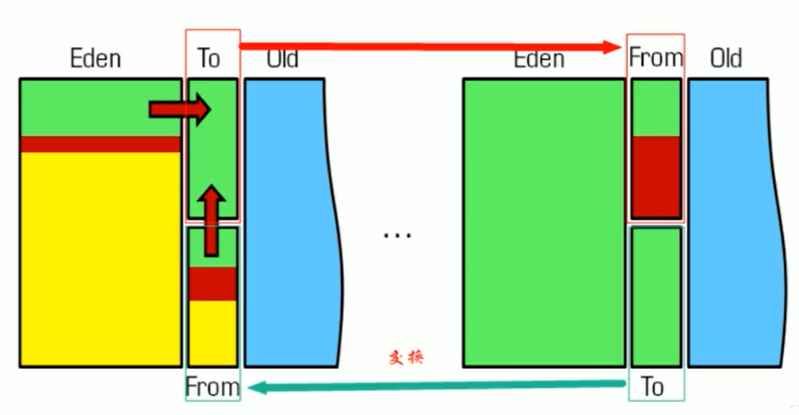
- 复制完成后,一次性清空整个 From 空间。
- 角色交换: 将原来的 To 空间作为下一次分配使用的 From 空间,原来的 From 空间则变成空闲的 To 空间。
- 循环: 重复以上过程。
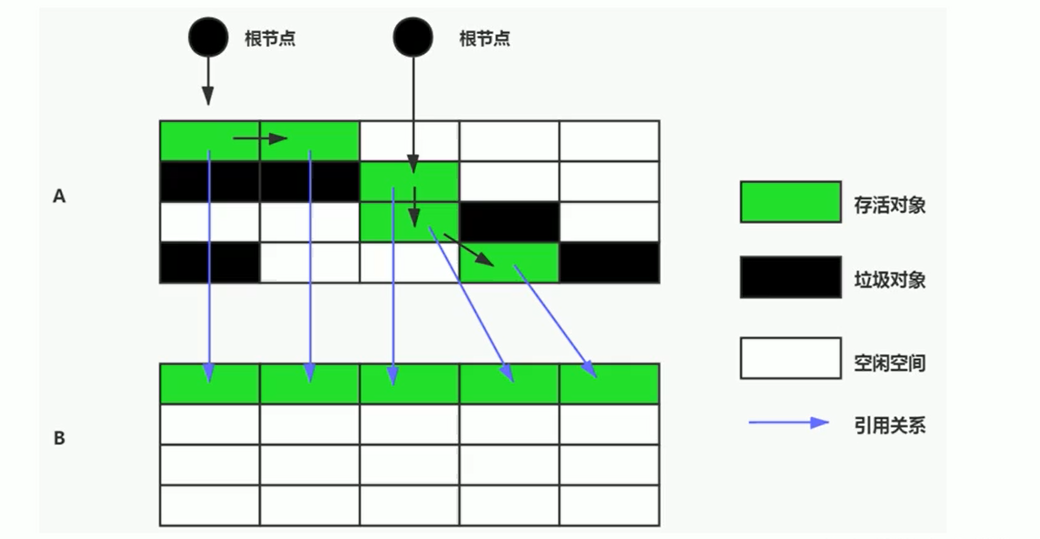 (图示:将 From 区存活对象复制到 To 区)
(图示:将 From 区存活对象复制到 To 区)
 (图示:清空原 From 区,交换 From 和 To 的角色)
(图示:清空原 From 区,交换 From 和 To 的角色)
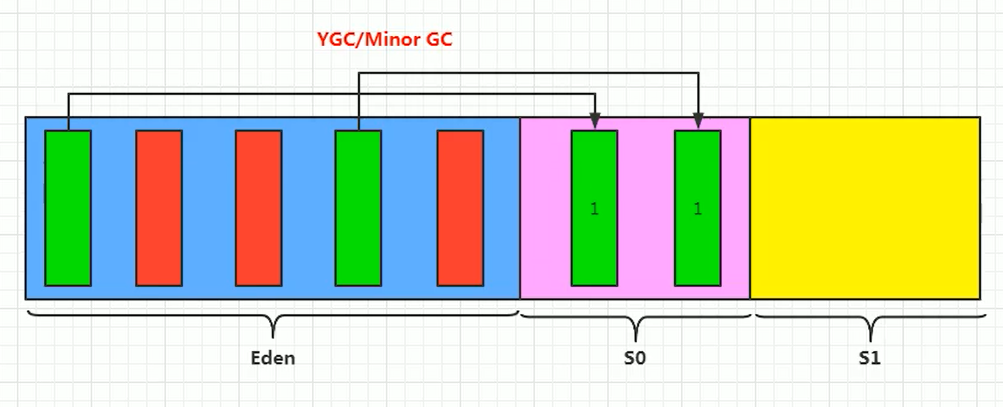
与新生代的关系: Java HotSpot VM 的新生代 (Young Generation) 回收就采用了复制算法的思想。Eden 区 + 两个 Survivor 区 (From/To) 的设计就是对标准复制算法的优化(不需要浪费一半内存,只需要浪费一个 Survivor 区的空间)。
# 8.3 优点
- 效率高: 只需遍历一次标记存活对象并进行复制,没有单独的清除阶段。复制过程通常比遍历整个堆清除垃圾更快,特别是当存活对象很少时。
- 无内存碎片: 每次回收后,存活对象都被集中复制到新的空间,内存是连续规整的,便于后续分配。分配内存时可以使用指针碰撞法,效率很高。
# 8.4 缺点
- 空间浪费: 需要牺牲一部分内存作为复制目标的备用空间。标准的复制算法需要将可用内存减半,代价很高。HotSpot 的 Eden+Survivor 优化了这一点,但仍需一个 Survivor 区的额外空间。
- 不适合存活率高的场景: 如果大部分对象都是存活的(例如在老年代),复制算法需要复制大量对象,效率会急剧下降,甚至低于标记-清除。
- 对象移动开销: 复制对象涉及到内存拷贝和可能的引用更新(如果 G1 等分区收集器需要在 Region 间复制),带来一定开销。
# 8.5 适用场景
复制算法特别适用于对象生命周期短、存活率低的内存区域,例如 Java 新生代。一次 Minor GC 通常能回收 70%-99% 的对象,只需复制少量存活对象,效率极高。
# 9. 清除阶段算法三:标记-整理 (Mark-Compact)
标记-整理算法(也叫标记-压缩算法)旨在结合标记-清除和复制算法的优点,克服它们的缺点,特别适用于老年代的回收。
# 9.1 背景
- 复制算法不适用老年代: 老年代对象存活率高,使用复制算法效率低且空间浪费严重。
- 标记-清除算法有碎片: 虽然标记-清除可以用在老年代,但会产生内存碎片,影响后续大对象分配。
因此,需要一种既能处理高存活率,又能消除碎片的算法。
# 9.2 执行过程
标记-整理算法也分为两个主要阶段(有时看作三个):
- 标记 (Mark): 与标记-清除算法的标记阶段完全相同。从 GC Roots 出发,标记所有存活对象。
- 整理 (Compact): 在标记完成后,移动所有存活的对象,将它们向内存空间的一端紧凑地排列,然后直接清理掉边界以外的所有内存区域。
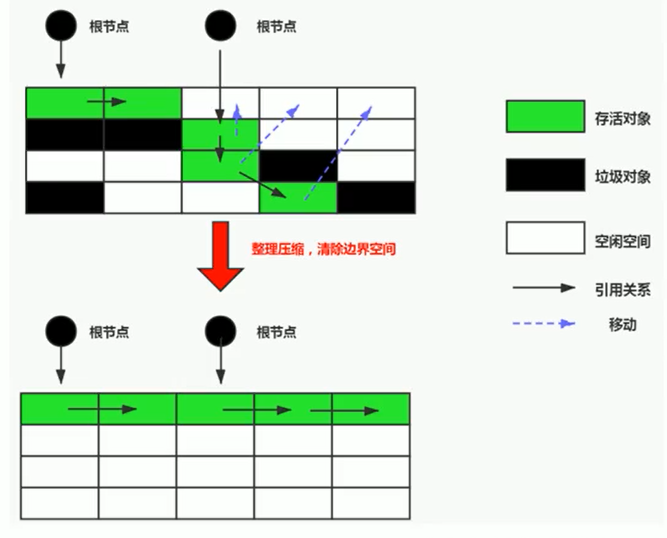 (图示:先标记存活对象,然后将存活对象移动到一端,最后清理边界外的内存)
(图示:先标记存活对象,然后将存活对象移动到一端,最后清理边界外的内存)
# 9.3 与标记-清除的区别
- 本质差异: 标记-清除是非移动式 (Non-moving) 的回收算法(只清理垃圾,不移动存活对象),而标记-整理是移动式 (Moving) 的回收算法(需要移动存活对象)。
- 内存规整性: 标记-整理后,内存是连续规整的,没有碎片;标记-清除后内存不连续,有碎片。
- 后续分配: 标记-整理后可以使用指针碰撞分配内存;标记-清除需要维护空闲列表。
是否移动对象是一个重要的决策:移动对象可以消除碎片,但需要更新所有指向被移动对象的引用,带来额外开销和更长的 STW 时间。
# 9.4 优点
- 消除内存碎片: 回收后内存空间是连续的,避免了标记-清除算法的碎片问题。
- 空间利用率高: 不像复制算法那样需要牺牲一半(或一部分)内存空间。
# 9.5 缺点
- 效率相对较低: 比复制算法慢(多了整理阶段),通常也比标记-清除算法慢(因为多了移动对象的开销)。
- 移动对象开销大: 移动对象本身耗时,并且需要更新所有指向这些对象的引用,这是一个复杂且耗时的过程。
- STW 时间可能较长: 标记和整理阶段都需要暂停用户程序 (STW)。移动大量对象会显著增加 STW 时间。
# 10. 清除阶段算法小结
三种基本清除算法各有优劣,适用于不同的场景:
| 算法 | 速度 | 空间开销 (Overhead) | 内存碎片 | 是否移动对象 | 适用场景 |
|---|---|---|---|---|---|
| 标记-清除 | 中等 | 低 (只需少量标记位) | 有 | 否 | (很少单独用) |
| 复制 | 最快 | 高 (通常牺牲一半或部分空间) | 无 | 是 | 新生代 |
| 标记-整理 | 最慢 | 低 (只需少量标记位) | 无 | 是 | 老年代 |
结论: 没有“最好”的算法,只有“最合适”的算法。需要根据内存区域的特点(如对象存活率)来选择。
# 11. 分代收集算法 (Generational Collection)
鉴于没有任何一种单一算法能够完美适应所有场景,现代 JVM 普遍采用分代收集算法。
核心思想: 基于对大量应用的对象生命周期统计分析得出的分代假说:
- 弱分代假说: 绝大多数对象是“朝生夕灭”的。
- 强分代假说: 熬过越多次 GC 的对象就越难以消亡。
- 跨代引用假说: 跨代引用(如老年代引用新生代)相对同代引用是少数。
基于这些假说,将 Java 堆划分为不同的代 (Generation),并对不同代采用不同的、最适合其特点的垃圾回收算法,以提高整体 GC 效率。
HotSpot VM 的分代实现:
- 年轻代 (Young Generation):
- 特点: 区域相对较小,对象生命周期短,存活率低,回收频繁。
- 适用算法: 复制 (Copying) 算法。因为存活对象少,复制成本低,效率高,且能消除碎片。通过 Eden + 两个 Survivor 区的设计优化了空间利用率。
- 老年代 (Tenured/Old Generation):
- 特点: 区域较大,对象生命周期长,存活率高,回收频率较低。
- 适用算法: 标记-清除 (Mark-Sweep) 或 标记-整理 (Mark-Compact) 算法(或它们的混合/改进版)。因为存活对象多,复制算法代价太高。标记-清除效率相对较高但有碎片;标记-整理无碎片但移动对象开销大。
- 标记 (Mark) 开销: 与存活对象数量成正比。
- 清除 (Sweep) 开销: 与管理区域大小成正比。
- 整理 (Compact) 开销: 与存活对象数量及大小成正比。
示例:CMS 与 Serial Old 的配合 HotSpot 中的 CMS (Concurrent Mark Sweep) 收集器主要用于老年代,它基于标记-清除算法实现,以并发处理标记和清除阶段来降低 STW 时间。但它会产生内存碎片。为了解决碎片问题,CMS 使用标记-整理算法的 Serial Old 收集器作为后备:当并发回收失败(如碎片过多导致无法分配)或需要进行 Full GC 时,会切换到 Serial Old 来对老年代进行整理。
结论: 分代收集思想是现代 JVM GC 的基石,几乎所有主流垃圾收集器都采用了分代设计。
# 12. 增量收集算法 (Incremental Collection)
背景: 传统的 GC 算法(如上面讨论的)在执行时通常需要完全暂停用户应用程序 (STW)。如果堆很大,或者存活对象很多,一次 GC 的 STW 时间可能很长,严重影响应用的响应性,尤其对于交互式应用或实时系统。
核心思想: 为了缩短单次 GC 的停顿时间,增量收集算法将一次完整的 GC 过程(特别是标记或清除/复制/整理阶段)分割成多个小的步骤或阶段,让垃圾收集线程和应用程序线程交替执行。每次 GC 线程只处理一小部分内存区域或任务,然后切换回应用程序线程,如此反复,直到整个 GC 过程完成。
实现基础: 增量收集通常还是基于传统的标记-清除、复制或标记-整理算法,但通过精巧的线程间同步和冲突处理机制来实现分阶段执行。
优点:
- 显著减少了单次 GC 的最大停顿时间,提高了应用的响应性。
缺点:
- 由于频繁的线程切换和上下文转换,以及维护中间状态所需的额外工作,会增加 GC 的总 CPU 时间消耗,降低系统的整体吞吐量。
增量收集是早期为了改善 STW 问题的一种尝试,现代更先进的并发收集器(如 CMS, G1, ZGC, Shenandoah)采用了更复杂的并发处理技术,旨在更大程度上减少 STW。
# 13. 分区算法 / Region 算法
背景: 随着可用内存越来越大,传统的基于整个新生代或整个老年代进行回收的方式,即使采用分代,一次 GC(尤其是 Full GC 或老年代 GC)需要处理的内存范围仍然可能很大,导致 STW 时间随堆增大而线性增长。
核心思想: 不再将堆视为连续的、整体的新生代和老年代,而是将整个 Java 堆划分为多个大小相等、独立的小区域 (Region)。每个 Region 可以独立地扮演 Eden、Survivor 或 Old Generation 的角色。
回收方式: 垃圾收集器不再以整个“代”为单位进行回收,而是以 Region 为基本单位。JVM 会跟踪每个 Region 中的垃圾堆积情况和回收价值(预期收益)。每次 GC 时,根据预设的最大停顿时间目标 (Pause Time Goal),优先选择回收价值最高的若干个 Region 进行回收(这也是 G1 - Garbage-First 名字的由来)。
优点:
- 可预测的停顿时间: 通过控制每次回收的 Region 数量,可以将 GC 停顿时间控制在目标范围内,避免了传统 GC 可能出现的长时间 STW。GC 停顿不再与整个堆大小直接相关,而是与选择回收的 Region 数量相关。
- 适用于大堆内存: 在具有非常大堆内存的服务器上,分区算法能够提供更好的性能和可控的停顿。
代表收集器: G1, ZGC, Shenandoah 都采用了分区/Region 的思想(具体实现细节各有不同)。
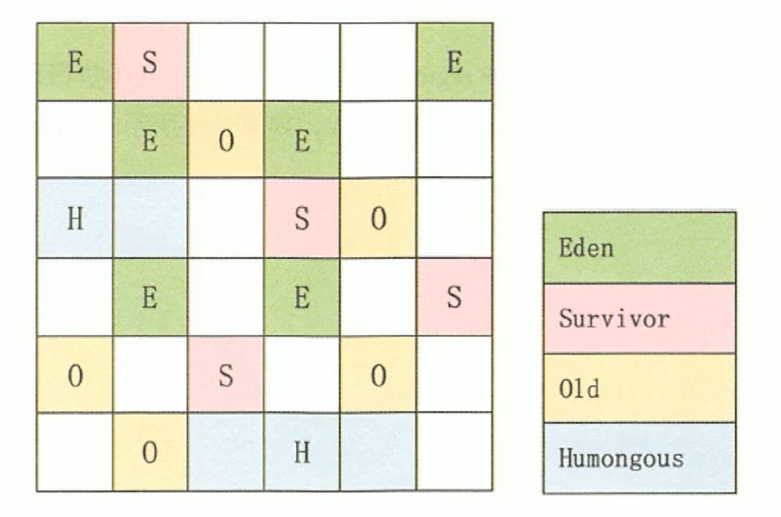 (图中将堆划分为多个小 Region)
(图中将堆划分为多个小 Region)
# 14. 写在最后
本篇介绍了垃圾回收中的标记算法(引用计数、可达性分析)、对象的 finalization 机制以及三种基础的清除算法(标记-清除、复制、标记-整理)。同时,也探讨了分代收集、增量收集和分区算法这些更宏观的 GC 策略思想。
需要强调的是,这些只是基础的算法思路。现代高性能 JVM 中的实际垃圾收集器实现远比这些基础算法复杂得多,它们通常是复合算法的结合,并且大量运用了并行 (Parallel) 和并发 (Concurrent) 技术来优化效率、减少 STW 时间。理解这些基础算法是深入学习和调优具体垃圾收集器的前提。