 JVM - 对象实例化内存布局
JVM - 对象实例化内存布局
# 1. 对象的实例化过程
理解 Java 对象如何在 JVM 中创建、存储和访问是深入掌握 JVM 的关键一步。
# 1.1 相关面试题
- 美团:
- 对象在 JVM 中是怎么存储的?
- 对象头信息里面有哪些东西?
- 蚂蚁金服:
- 二面:Java 对象头里有什么?
这些问题都直指对象在 JVM 底层的实现细节。
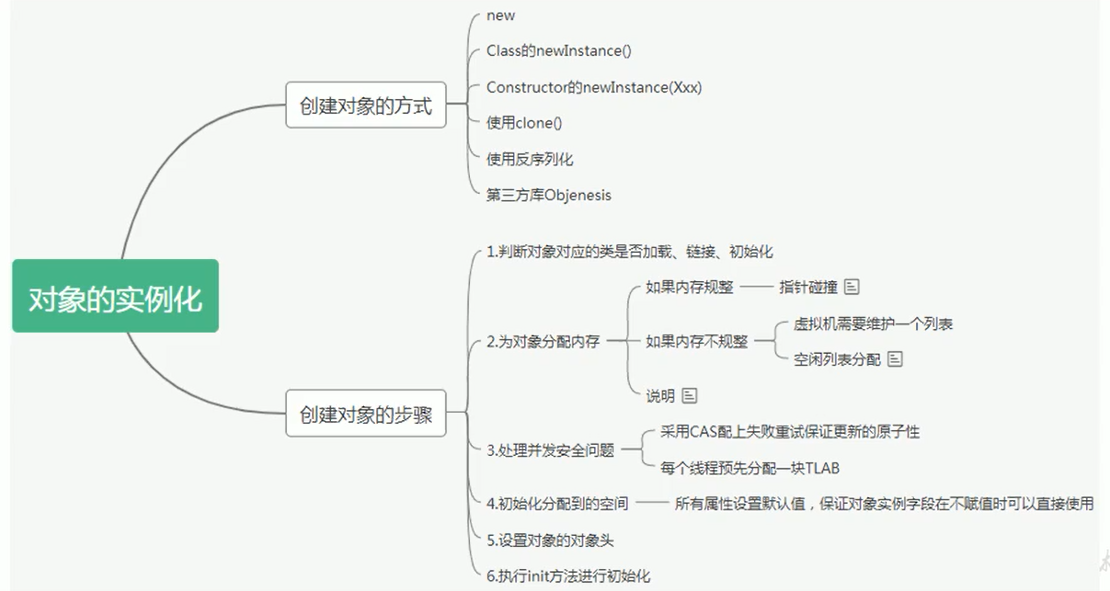
# 1.2 对象的创建方式
Java 中创建对象实例的方式多种多样:
new关键字:最常见、最直接的方式。包括:- 直接使用
new ClassName()。 - 调用单例模式中的
getInstance()静态方法(内部通常也是new)。 - 调用工厂模式(XXXFactory)的静态方法(内部可能封装了
new)。
- 直接使用
Class.newInstance():通过反射创建对象。- 缺点:只能调用无参构造器,且构造器访问权限必须是
public。 - 状态:在 JDK 9 中已被标记为过时 (deprecated)。
- 缺点:只能调用无参构造器,且构造器访问权限必须是
Constructor.newInstance(Object... initargs):通过反射创建对象。- 优点:可以调用任意参数的构造器(包括私有构造器,需先
setAccessible(true))。功能更强大、更灵活。
- 优点:可以调用任意参数的构造器(包括私有构造器,需先
clone()方法:实现对象的浅拷贝或深拷贝(取决于具体实现)。- 特点:不调用任何构造器。
- 要求:当前类必须实现
Cloneable接口并重写clone()方法。
- 反序列化 (Deserialization):从文件、网络或其他来源读取对象的二进制流,并将其还原成对象实例。
- 特点:不调用任何构造器。
- 应用场景:常用于 RPC(远程过程调用)、缓存、Socket 网络传输等。
- 第三方库:如 Objenesis 库,它专门用于绕过构造函数创建对象,常用于 Mock 测试或某些框架的内部实现。
# 1.3 对象创建的详细步骤 (以 new 指令为例)
我们从字节码层面深入理解 new 一个对象时,JVM 内部发生的具体步骤。
示例代码:
// 文件名: ObjectTest.java
public class ObjectTest {
public static void main(String[] args) {
// 创建一个简单的 Object 对象
Object obj = new Object();
}
}
2
3
4
5
6
7
对应的字节码 (javap -v ObjectTest.class):
// main 方法的字节码
public static void main(java.lang.String[]);
descriptor: ([Ljava/lang/String;)V
flags: ACC_PUBLIC, ACC_STATIC
Code:
stack=2, locals=2, args_size=1 // 操作数栈深度2, 局部变量表大小2, 参数个数1
0: new #2 // 指令1: 创建对象实例 (class java/lang/Object)
3: dup // 指令2: 复制栈顶对象引用
4: invokespecial #1 // 指令3: 调用对象初始化方法 (<init>) (Method java/lang/Object."<init>":()V)
7: astore_1 // 指令4: 将栈顶对象引用存入局部变量表索引1的位置 (变量 obj)
8: return // 指令5: 方法返回
LineNumberTable: // 行号表 (源码行号与字节码行号对应)
line 9: 0
line 10: 8
LocalVariableTable: // 局部变量表
Start Length Slot Name Signature
0 9 0 args [Ljava/lang/String; // main 方法参数 args
8 1 1 obj Ljava/lang/Object; // 局部变量 obj
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
结合字节码,JVM 创建对象的详细步骤如下:
步骤 1:类加载检查 (Class Loading Check)
- 当 JVM 遇到
new指令时(字节码行0: new #2),首先会检查指令的参数(这里是#2,指向常量池中java/lang/Object类的符号引用)是否能在方法区 (Metaspace) 的运行时常量池中定位到对应的符号引用。 - 接着检查这个符号引用代表的类(
java.lang.Object)是否已经被加载、解析和初始化。 - 如果类尚未加载:JVM 会启动类加载过程(通常遵循双亲委派模型),找到对应的
.class文件,加载类的元数据到方法区,并进行链接(验证、准备、解析)和初始化。如果找不到.class文件,会抛出ClassNotFoundException。
步骤 2:为对象分配内存 (Memory Allocation)
- 类加载检查通过后,JVM 开始为新对象在 Java 堆中分配内存。
- 所需内存大小:在类加载完成后就已经确定了。对象所需内存大小等于所有实例变量(包括从父类继承的)占用空间的总和,再加上对象头(Header)以及可能的对齐填充(Padding)所占的空间。引用类型的实例变量只分配引用本身的大小(通常是 4 字节或 8 字节)。
- 内存分配方式(取决于堆内存是否规整,由所使用的垃圾收集器决定):
- 指针碰撞 (Bump The Pointer):
- 适用场景:如果 Java 堆内存是规整的(即已使用和未使用的内存分开,中间没有碎片),通常在使用带有压缩整理 (Compact) 功能的垃圾收集器时(如 Serial GC, Parallel Scavenge/Old GC, G1 的部分阶段)。
- 过程:JVM 维护一个指针,指向内存分配的边界。分配内存时,只需将指针向空闲内存方向移动对象大小相等的距离即可。简单高效。
- 空闲列表 (Free List):
- 适用场景:如果 Java 堆内存不规整(已使用和未使用的内存交错,存在碎片),通常在使用标记-清除 (Mark-Sweep) 算法的垃圾收集器时(如 CMS)。
- 过程:JVM 维护一个列表,记录着堆中哪些内存块是可用的。分配时,从列表中查找一块足够大的连续空间分配给对象,并更新列表记录。相对复杂。
- 指针碰撞 (Bump The Pointer):
步骤 3:处理并发问题 (Concurrency Handling)
- 在堆上分配内存是一个高频操作。在多线程环境下,可能出现多个线程同时申请内存的情况,必须保证分配的原子性。JVM 通常采用以下两种方式之一解决并发分配问题:
- CAS (Compare-And-Swap) + 失败重试:JVM 采用 CAS 乐观锁机制来尝试更新内存分配指针或空闲列表。如果更新失败(意味着其他线程修改了),则进行重试,直到成功为止。保证了操作的原子性。
- TLAB (Thread Local Allocation Buffer):(HotSpot JVM 默认推荐的方式)
- 为每个线程在新生代的 Eden 区预先分配一小块私有内存缓冲区 (TLAB)。
- 线程需要分配对象时,优先在自己的 TLAB 中分配。因为 TLAB 是线程私有的,所以在 TLAB 内部分配无需加锁,速度快。
- 只有当 TLAB 用完,需要申请新的 TLAB 时,或者要分配的对象太大无法放入 TLAB 时,才需要使用 CAS 等同步机制在共享的 Eden 区进行分配。
- 可以通过
-XX:+UseTLAB(默认开启) /-XX:-UseTLAB控制是否使用 TLAB。
步骤 4:内存空间初始化 (Zeroing Memory)
- 内存分配完成后,JVM 需要将分配到的内存空间(不包括对象头)都初始化为零值(例如
int为 0,boolean为false, 引用类型为null)。 - 目的:保证对象的实例字段在不显式赋值的情况下也能直接使用(访问到的是对应类型的零值),符合 Java 语言规范。程序员无需担心拿到未初始化的内存。
步骤 5:设置对象头 (Object Header Setup)
- JVM 需要为新创建的对象设置对象头 (Object Header)。对象头包含了关于对象自身状态的重要信息。
- 主要内容(详见后续“对象内存布局”):
- Mark Word (运行时元数据):存储对象自身的运行时数据,如哈希码 (HashCode)、GC 分代年龄、锁状态标志、线程持有的锁、偏向线程 ID 等。这部分数据是动态变化的。
- Klass Pointer (类型指针):指向该对象所属类的元数据(存储在方法区中的
InstanceKlass对象)的指针。通过这个指针,JVM 才能确定这个对象是哪个类的实例。 - Array Length (数组长度):如果对象是一个数组,对象头中还需要额外存储数组的长度。
步骤 6:执行 <init> 方法 (Initialization)
- 上述步骤完成后,从 JVM 的视角看,一个对象已经产生了(内存已分配、对象头已设置)。但从 Java 程序的视角看,对象创建还未完成,需要执行对象的初始化方法
<init>()(即构造函数对应的字节码)。 <init>方法是 Java 编译器生成的,它负责:- 执行实例变量的显式初始化(例如
int id = 1001;)。 - 执行实例初始化块(花括号
{}包裹的代码块)。 - 执行构造函数中指定的代码。
- (隐式地)调用父类的
<init>方法(通常是第一条指令,除非显式调用this(...)或super(...))。
- 执行实例变量的显式初始化(例如
- 字节码指令
4: invokespecial #1就是调用<init>方法。invokespecial用于调用实例初始化方法、私有方法和父类方法。 - 在
<init>方法执行完毕后,对象才真正按照程序员的意愿被初始化,成为一个可用的对象。 - 最后,
new指令创建的对象的引用会被压到操作数栈顶。字节码指令7: astore_1将这个引用从操作数栈存入局部变量表,赋值给变量obj。
<init> 方法内部的赋值顺序:
在 <init> 方法执行期间,对象属性的赋值遵循以下大致顺序(由编译器编译 <init> 方法时的指令顺序决定):
- 属性的默认初始化 (Zeroing):在步骤 4 中 JVM 已经完成。
- 显式初始化:代码中直接赋值,如
int id = 1001;。 - 代码块中初始化:实例初始化块
{ ... }中的赋值。 - 构造器中初始化:构造函数方法体内的赋值。
示例代码与 <init> 字节码对应:
// 文件名: Customer.java
public class Customer {
int id = 1001; // ② 显式初始化
String name; // ① 默认初始化为 null
Account acct; // ① 默认初始化为 null
{ // ③ 代码块初始化
name = "匿名客户";
}
public Customer() { // ④ 构造器初始化
super(); // 隐藏的调用父类构造器
acct = new Account();
}
}
class Account { }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Customer 类的 <init>() 方法字节码 (javap -c Customer.class):
// com.youngkbt.java.Customer();
// descriptor: ()V
// flags:
// Code:
// stack=4, locals=1, args_size=1
0: aload_0 // 加载 this 引用
1: invokespecial #1 // 调用父类 Object 的 <init> 方法
4: aload_0 // 加载 this 引用
5: sipush 1001 // 将 1001 压栈
8: putfield #2 // 将 1001 赋值给 this.id (对应 ② 显式初始化)
11: aload_0 // 加载 this 引用
12: ldc #3 // 加载字符串 "匿名客户" 的引用 (来自常量池)
14: putfield #4 // 将 "匿名客户" 赋值给 this.name (对应 ③ 代码块初始化)
17: aload_0 // 加载 this 引用
18: new #5 // 创建 Account 对象实例 (class com/youngkbt/java/Account)
21: dup // 复制 Account 对象引用
22: invokespecial #6 // 调用 Account 的 <init> 方法
25: putfield #7 // 将 Account 对象引用赋值给 this.acct (对应 ④ 构造器初始化)
28: return
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
(可以看到字节码指令顺序大致对应了 ② -> ③ -> ④ 的初始化过程,而 ① 默认初始化由 JVM 在分配内存后完成)
对象实例化过程总结:
- 类加载检查
- 分配内存(指针碰撞 / 空闲列表)
- 处理并发(CAS / TLAB)
- 内存零值初始化
- 设置对象头
- 执行
<init>方法(显式初始化 / 代码块 / 构造器) - 栈中引用指向对象
# 2. 对象内存布局
一个 Java 对象在堆内存中存储时,其内部结构可以划分为三个主要部分:
- 对象头 (Header)
- 实例数据 (Instance Data)
- 对齐填充 (Padding) (可选)
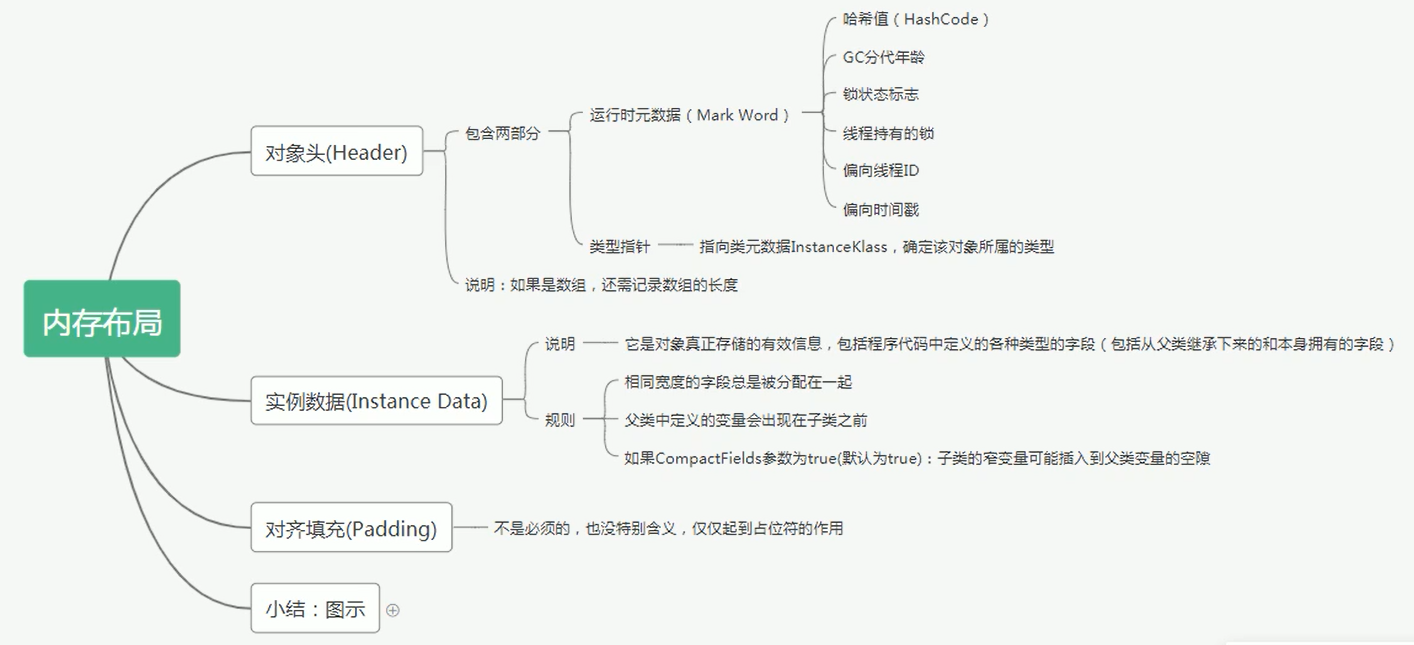
# 2.1 对象头 (Header)
对象头是 JVM 用于管理对象自身状态的元数据,它不存储对象的业务数据。HotSpot 虚拟机的对象头包含以下两(或三)部分信息:
1. 运行时元数据 (Mark Word):
- 作用:存储对象自身的运行时状态信息,这部分数据会随着对象的锁状态、GC 状态等变化而动态更新。
- 内容 (在 64 位 JVM 中通常占用 8 字节 / 64 位):
- 哈希码 (HashCode):对象的标识哈希码(懒加载,非对象地址)。
- GC 分代年龄 (GC Age):记录对象在新生代 Survivor 区经历过的 Minor GC 次数,用于判断何时晋升到老年代(最大通常为 15,占 4 bits)。
- 锁状态标志 (Lock Status):标记对象当前处于哪种锁状态(无锁、偏向锁、轻量级锁、重量级锁)。
- 线程持有的锁 (Thread Lock):在轻量级锁和重量级锁状态下,指向持有锁的线程栈上的锁记录 (Lock Record) 或监视器对象 (Monitor)。
- 偏向线程 ID (Biased Thread ID):在偏向锁状态下,记录持有偏向锁的线程 ID。
- 偏向时间戳 (Biased Timestamp):配合偏向锁撤销。
- 结构复用:Mark Word 的空间是有限的,JVM 会根据对象当前的状态(如是否加锁、锁的类型)复用这块空间来存储不同的信息。例如,无锁状态下存储 HashCode 和 GC Age,加锁后会存储锁相关信息。
2. 类型指针 (Klass Pointer / Type Pointer):
- 作用:指向该对象所属类的元数据(即方法区中的
InstanceKlass对象)的指针。 - 目的:JVM 通过这个指针可以知道该对象是哪个类的实例,从而能够确定对象的结构、调用对象的方法等。
- 大小:在 64 位 JVM 中,如果开启了指针压缩 (
-XX:+UseCompressedOops,默认开启),类型指针占用 4 字节;如果未开启指针压缩,则占用 8 字节。
3. 数组长度 (Array Length):
- 条件:只有当对象是一个数组时,对象头中才会包含这部分信息。
- 作用:记录数组的长度。
- 大小:通常占用 4 字节。
总结对象头大小 (64位 JVM, 开启指针压缩):
- 非数组对象:Mark Word (8 字节) + Klass Pointer (4 字节) = 12 字节
- 数组对象:Mark Word (8 字节) + Klass Pointer (4 字节) + Array Length (4 字节) = 16 字节
# 2.2 实例数据 (Instance Data)
- 作用:这部分是对象真正存储有效信息的主体,即程序代码中定义的各种实例字段 (成员变量) 的值,包括从父类继承下来的字段和子类自己定义的字段。
- 存储顺序:受到 JVM 分配策略参数(
-XX:FieldsAllocationStyle)和字段在源码中定义顺序的影响。HotSpot 默认策略通常会优先分配占用空间小的字段(如 byte, boolean),并可能将相同宽度的字段集中在一起,以优化空间利用率。父类的字段通常会出现在子类字段之前。 - 数据类型:包括基本数据类型的值和引用类型的引用地址。
# 2.3 对齐填充 (Padding)
- 作用:占位符,确保对象的总大小是某个特定数值(通常是 8 字节)的整数倍。
- 原因:现代 CPU 访问内存时,按块(Cache Line,通常 64 字节)读取效率最高。对象按 8 字节对齐有助于提高 CPU 访问对象字段的效率,避免跨缓存行读取。
- 必要性:不是必需的。只有当对象头和实例数据的大小加起来不是 8 字节的整数倍时,才需要填充若干字节使其对齐。
- 类比:就像快递箱子里的泡沫填充物,用来保证易碎品(对象数据)在箱子(内存)中位置稳定、方便存取。
# 小结:对象内存布局示例
再次使用 Customer 类示例:
// 文件名: Customer.java (片段)
public class Customer {
int id = 1001; // 实例数据 (int: 4字节)
String name; // 实例数据 (引用: 4字节,开启指针压缩)
Account acct; // 实例数据 (引用: 4字节,开启指针压缩)
// ...构造器和代码块...
public static void main(String[] args) {
Customer cust = new Customer();
}
}
class Account {}
2
3
4
5
6
7
8
9
10
11
假设在 64 位 JVM 中开启指针压缩:
- 对象头:12 字节 (Mark Word 8 + Klass Pointer 4)
- 实例数据:
id: 4 字节 (int)name: 4 字节 (引用)acct: 4 字节 (引用)- 总计:4 + 4 + 4 = 12 字节
- 对象总大小 (未填充前):对象头 (12) + 实例数据 (12) = 24 字节
- 对齐填充:因为 24 字节已经是 8 的整数倍,所以无需填充。
- 最终对象大小:24 字节。
内存布局图解 (cust 引用指向堆中的 Customer 对象):
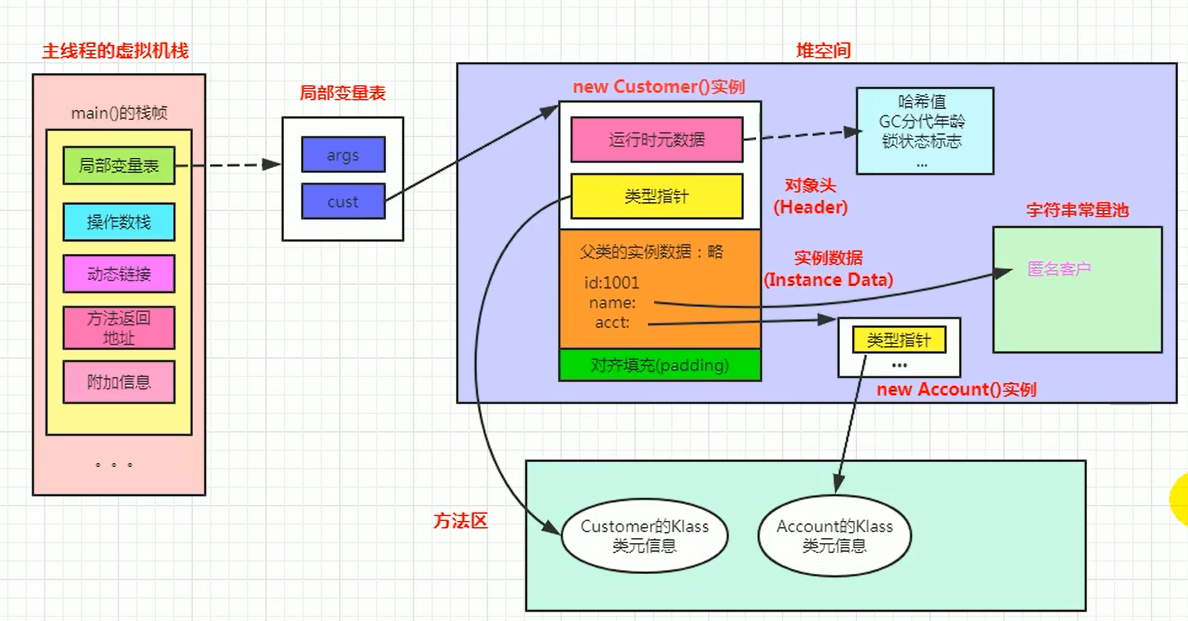 (注意:此图的文字说明“因为发送了逃逸分析,所以放在栈中分配”可能不准确或指特定优化场景。对于标准的
(注意:此图的文字说明“因为发送了逃逸分析,所以放在栈中分配”可能不准确或指特定优化场景。对于标准的 new Customer(),对象实例 cust 指向的内容在堆中,其布局如上所述。cust 这个引用本身在 main 方法的栈帧中。)
# 3. 对象的访问定位
当 Java 程序需要访问堆上的对象时(例如,通过栈上的引用变量调用对象的方法或访问字段),JVM 是如何定位到堆中对象实例以及其类型信息的呢?主要有两种主流方式:
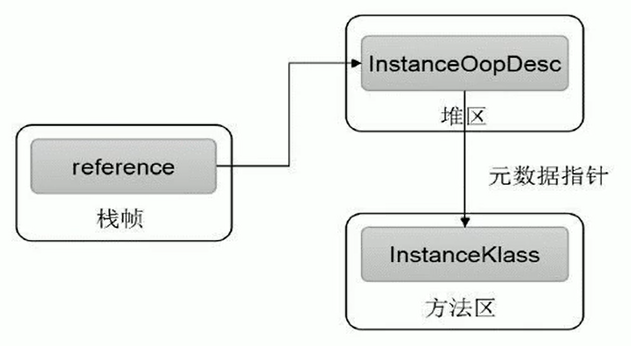 (栈帧中的引用变量是访问堆对象的起点)
(栈帧中的引用变量是访问堆对象的起点)
# 3.1 句柄访问 (Handle Access)
- 机制:Java 堆中会划分出一块独立的内存区域作为句柄池 (Handle Pool)。
- 栈上的引用变量 (reference) 存储的是对象在句柄池中的地址 (句柄地址)。
- 句柄池中的每个句柄包含两个指针:
- 一个指向堆中对象实例数据的指针。
- 一个指向方法区中对象类型数据(类元数据)的指针。
- 访问过程:访问对象需要两次指针解引用:reference -> 句柄 -> 对象实例数据/类型数据。
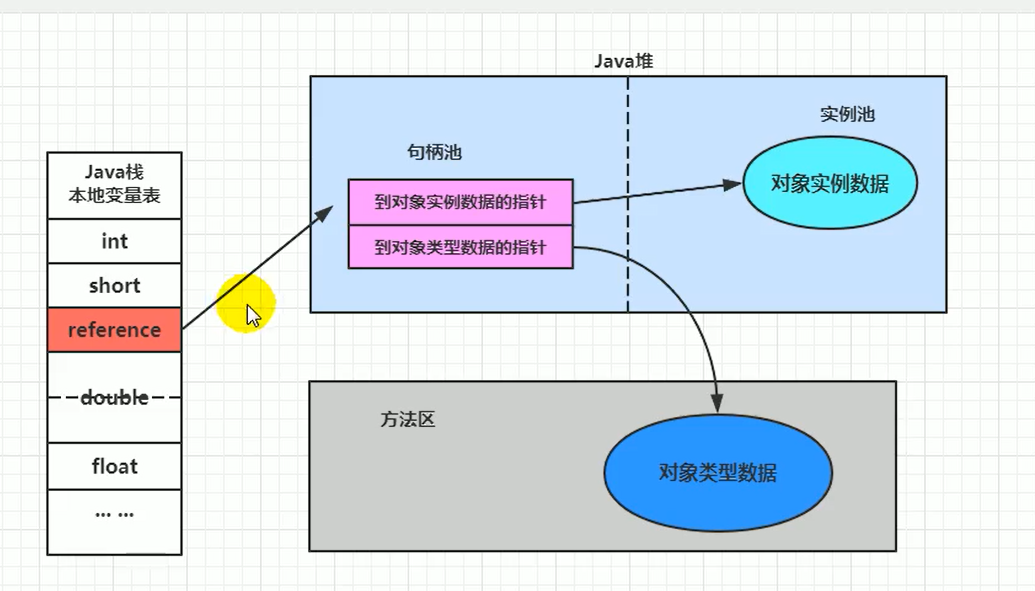
- 优点:
- 引用稳定:当对象在堆中被移动时(例如 GC 过程中的内存整理),只需要修改句柄池中指向实例数据的指针,而栈上的 reference 本身不需要改变。这对于垃圾回收非常友好。
- 缺点:
- 访问效率低:需要两次指针解引用才能访问到对象本身的数据,增加了访问开销。
- 额外空间开销:需要额外的句柄池空间。
# 3.2 直接指针访问 (Direct Pointer Access) - HotSpot 采用
- 机制:栈上的引用变量 (reference) 直接存储对象在堆中的地址。
- 堆中的对象实例内部(通过对象头中的类型指针) 包含指向方法区中对象类型数据的指针。
- 访问过程:
- 访问对象实例数据:只需一次指针解引用(reference -> 对象实例数据)。
- 访问对象类型数据(如调用方法):需要两次指针解引用(reference -> 对象实例 -> 类型数据)。
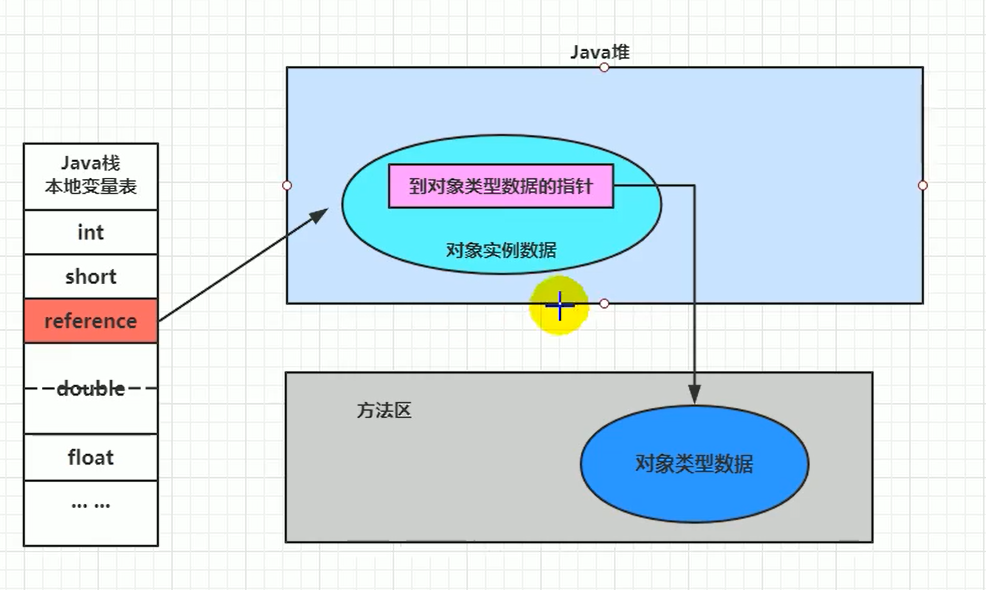
- 优点:
- 访问速度快:访问对象实例数据只需要一次指针解引用,比句柄访问少了一次,这是非常频繁的操作,因此整体性能较高。
- 缺点:
- 引用不稳定:当对象在堆中被移动时(GC 内存整理),必须修改栈上所有指向该对象的 reference 的值,这会带来额外的维护开销。
总结:HotSpot 虚拟机主要采用的是直接指针访问方式,因为它在对象字段访问这一高频操作上具有性能优势。虽然对象移动时需要更新引用,但现代 JVM 的 GC 算法能够高效地处理这个问题。
# 图示
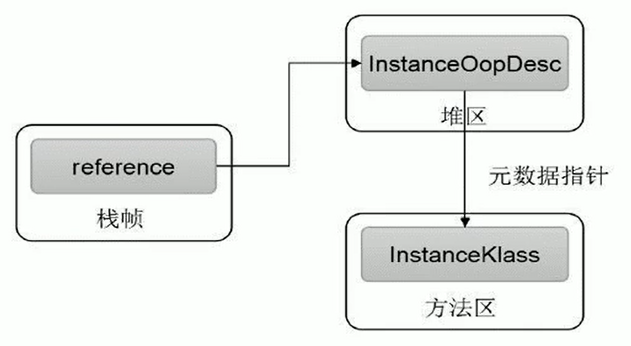
JVM 是如何通过栈帧中的对象引用访问到其内部的对象实例呢?
# 对象访问的两种方式
句柄访问
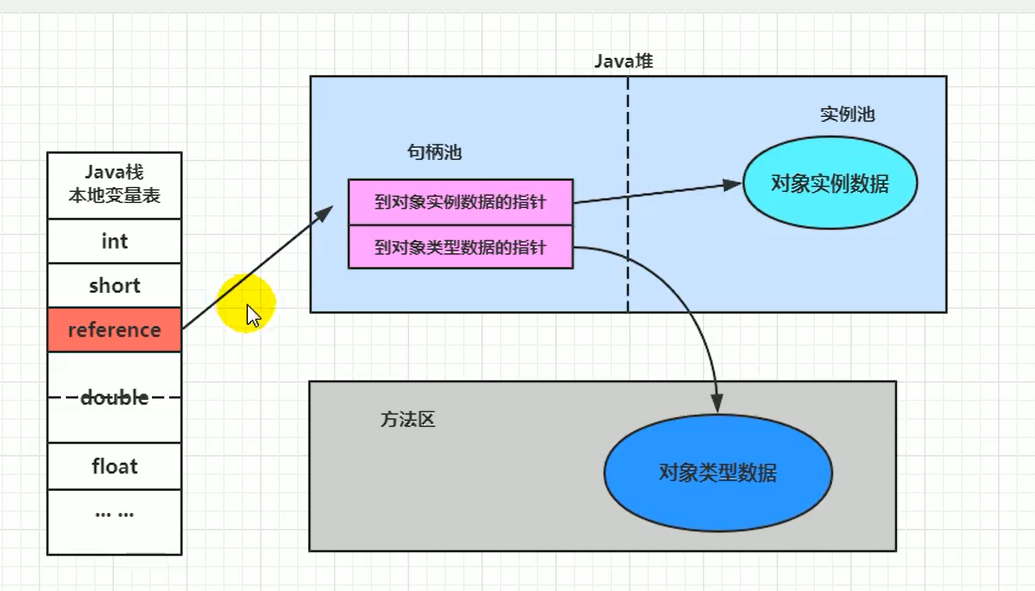
句柄访问就是说栈的局部变量表中,记录的对象的引用,然后在堆空间中开辟了一块空间,也就是句柄池。
优点和缺点
优点:reference 中存储稳定句柄地址,对象被移动(垃圾收集时移动对象很普遍)时只会改变句柄中实例数据指针即可,reference 本身不需要被修改。
缺点:在堆空间中开辟了一块空间作为句柄池,句柄池本身也会占用空间;通过两次指针访问才能访问到堆中的对象,效率低。
直接指针(HotSpot 采用)
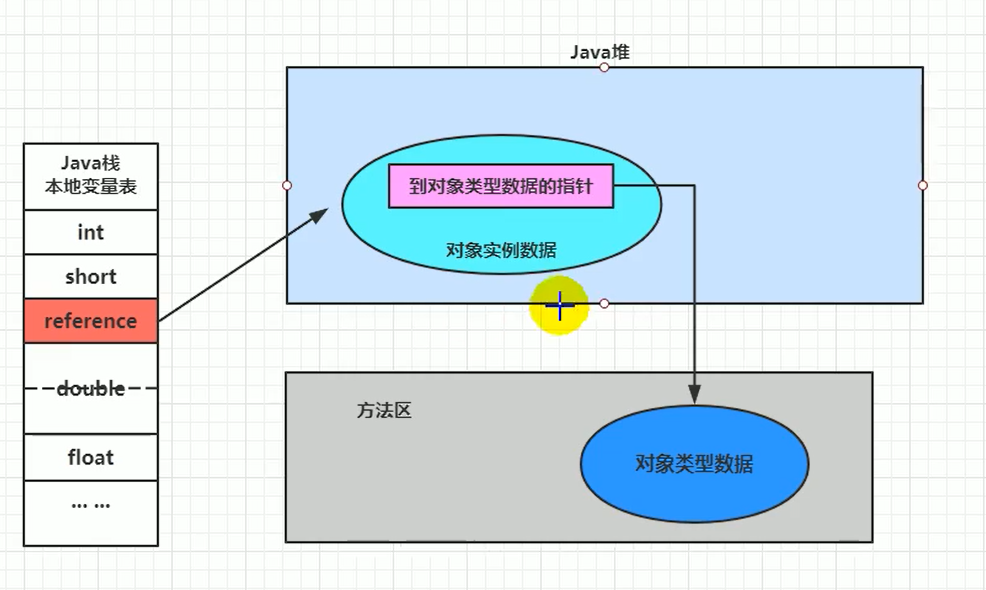
直接指针是局部变量表中的引用,直接指向堆中的实例,在对象实例中有类型指针,指向的是方法区中的对象类型数据。
优点和缺点
优点:直接指针是局部变量表中的引用,直接指向堆中的实例(一步到位),在对象实例中有类型指针,指向的是方法区中的对象类型数据。
缺点:对象被移动(垃圾收集时移动对象很普遍)时需要修改 reference 的值。