 JVM - 监控及诊断工具GUI
JVM - 监控及诊断工具GUI
# 1. 工具概述:从命令行到图形化界面
上一章节介绍了多种基于命令行的 JVM 监控和诊断工具(如 jps, jstat, jinfo, jmap, jstack, jcmd)。这些工具能帮助我们获取目标 Java 应用性能相关的基础信息,但在某些场景下存在局限性:
- 缺乏方法级分析:命令行工具通常无法提供方法级别的详细数据,例如方法间的调用关系、每个方法的调用次数和执行时间。而这些信息对于精确定位应用性能瓶颈至关重要。
- 登录限制:通常需要登录到目标 Java 应用所在的服务器(宿主机)才能使用这些命令,操作不便,尤其是在远程或隔离环境中。
- 结果展示不直观:命令行输出的纯文本数据不够直观,需要人工解析和关联,分析效率较低。
为了克服这些局限,业界涌现了许多图形化(GUI)的 JVM 监控和诊断工具。这些工具不仅提供了更友好的用户界面,还集成了更强大的分析功能,能够帮助开发者更高效地定位和解决内存泄漏、性能瓶颈等问题。
本章将重点介绍几款常用的 GUI 工具:
JDK 自带工具 (位于 JDK 的 bin 目录下):
- JConsole: JDK 5 开始自带的可视化监控工具,提供基本的 JVM 概览、内存、线程、类加载等监控功能,基于 JMX。
- VisualVM: 功能更强大的多合一工具 (JDK 6u7 后自带),集成了多种命令行工具的功能,并支持插件扩展,提供性能分析(Profiling)、内存快照分析等。
- JMC (Java Mission Control): Oracle JDK 7u40 后自带 (Java 11 后开源),内置强大的 JFR (Java Flight Recorder),以极低的性能开销收集详细的运行时数据,适用于生产环境。
第三方工具:
- MAT (Memory Analyzer Tool): 基于 Eclipse 的强大堆内存分析器,专门用于分析 Heap Dump 文件,查找内存泄漏和优化内存消耗。免费且功能丰富。
- JProfiler: 著名的商业 Java 性能分析工具,功能极其强大全面,覆盖 CPU、内存、线程、数据库、网络等多个方面,但需要付费。
- Arthas: 阿里巴巴开源的 Java 诊断工具,虽然主要是命令行交互,但提供了 Web Console,并且可以在不重启应用、无需预先配置参数的情况下动态诊断线上问题,功能独特。
# 2. JConsole:基础 JVM 监控面板
官方文档参考 (Java 7):
https://docs.oracle.com/javase/7/docs/technotes/guides/management/jconsole.html
JConsole 是自 Java 5 起 JDK 内置的一个标准可视化监控和管理工具。它基于 JMX (Java Management Extensions) 技术,允许用户连接到本地或远程的 JVM 进程,实时监控其运行概况,包括内存使用情况(堆、非堆)、线程状态、类加载数量、CPU 占用率以及 MBean 信息。
启动方式:
直接在命令行运行 jconsole 命令,或者进入 JDK 的 bin 目录双击 jconsole.exe (Windows) 或执行 jconsole (Linux/macOS)。
连接方式:
JConsole 支持三种连接方式:
本地进程 (Local Process):
- 自动检测并列出当前用户在本地系统上运行的 JVM 进程。
- 选择要监控的进程即可连接。
- 连接基于文件系统授权,简单方便,但仅限于监控同一台机器上的进程。
- 注意:执行 JConsole 的用户需要与目标 Java 进程的运行用户相同。
远程进程 (Remote Process):
- 通过 RMI (Remote Method Invocation) 连接器连接到远程 JVM 暴露的 JMX 代理。
- 需要目标 JVM 启动时配置了 JMX 相关参数(如
-Dcom.sun.management.jmxremote.port=端口号,-Dcom.sun.management.jmxremote.authenticate=false(不推荐,无认证),-Dcom.sun.management.jmxremote.ssl=false(不推荐,无加密) 等)。 - 连接地址格式通常为:
service:jmx:rmi:///jndi/rmi://<hostName>:<portNum>/jmxrmi。 - 如果远程 JMX 配置了用户名/密码认证,需要在 JConsole 连接时提供凭据。
高级 (Advanced):
- 允许使用自定义的 JMX 连接器 URL 进行连接。
- 适用于需要通过非标准 RMI 连接器或连接到实现了 JMX 但非标准 RMI 方式暴露的 JMX 代理(例如某些旧版本应用服务器或自定义实现)的场景。
主要界面功能:
JConsole 连接成功后,会展示多个标签页,提供不同维度的监控信息:
概述 (Overview):
- 展示 CPU 使用率、堆内存使用情况、活动线程数、已加载类数量的实时曲线图。
- 提供 JVM 基本信息(版本、供应商、启动时间等)。
- 可以快速了解 JVM 的整体运行状态。
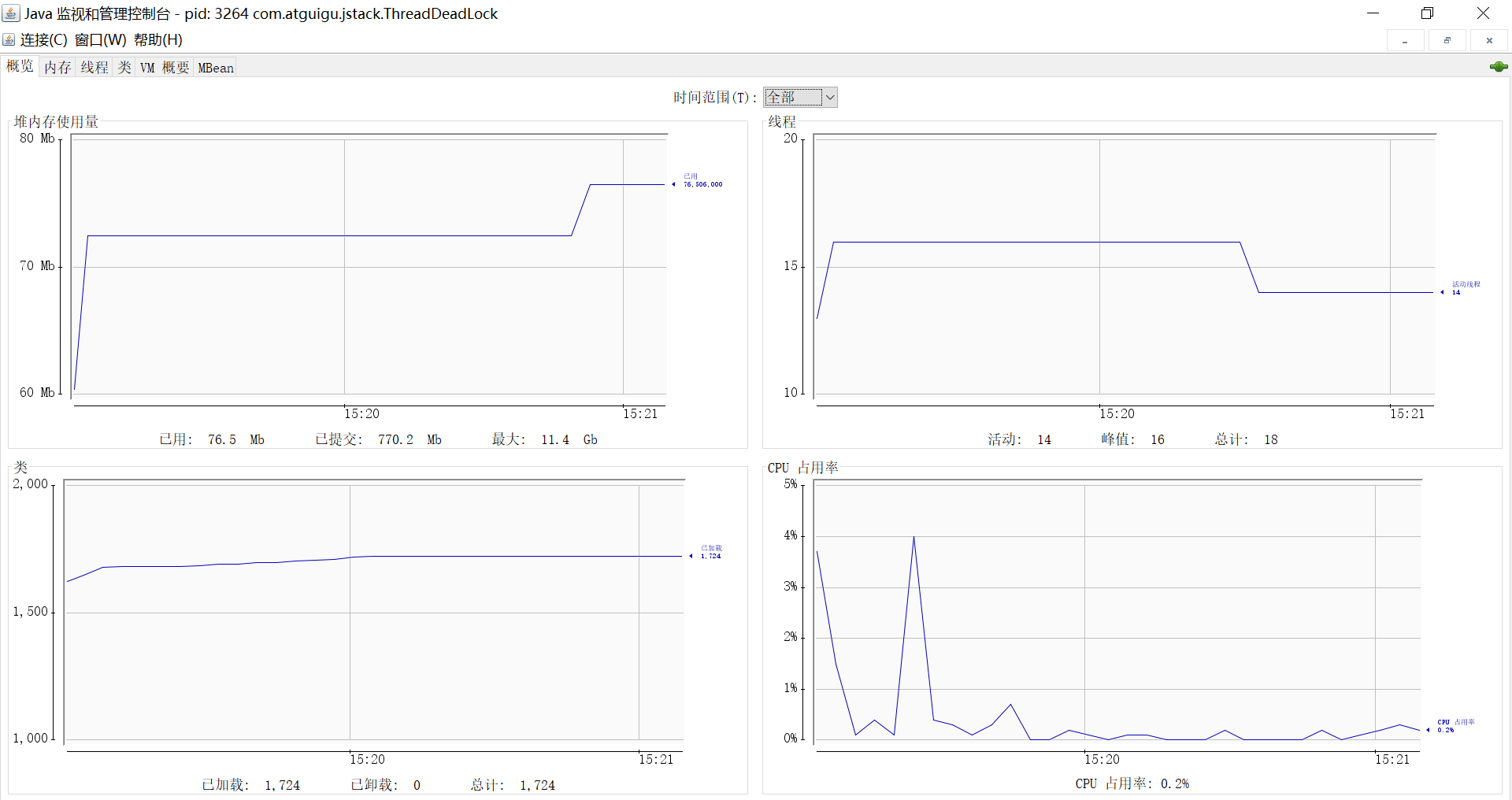 图:JConsole - 概述标签页
图:JConsole - 概述标签页
内存 (Memory):
- 提供各内存池(如 Eden Space, Survivor Space, Old Gen, Metaspace/PermGen)的使用情况曲线图和详细数据(已用、已提交、最大值)。
- 可以手动执行 GC 操作(谨慎在生产环境使用)。
- 底部可以选择不同的内存区域查看详细信息。
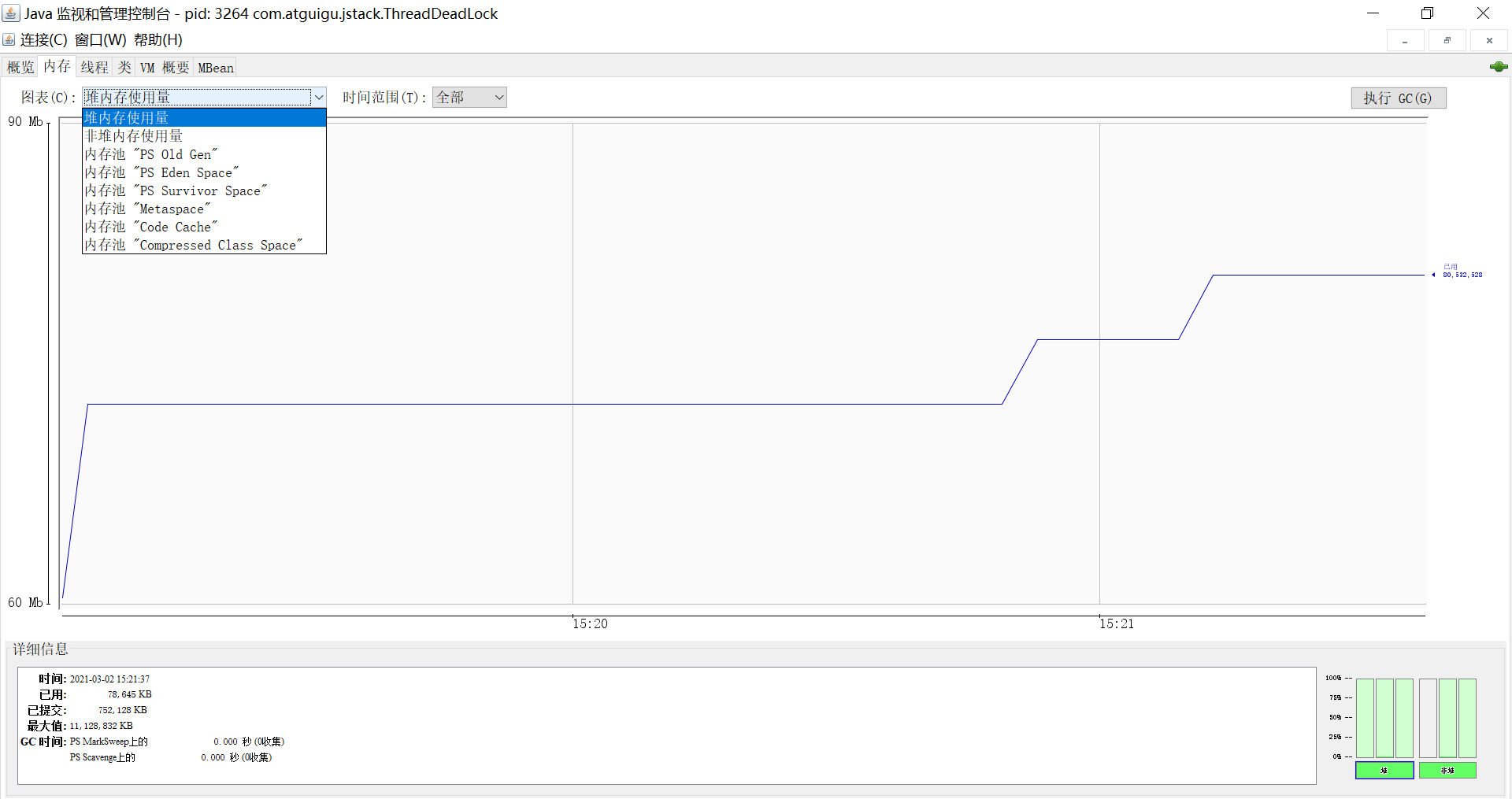 图:JConsole - 内存标签页
图:JConsole - 内存标签页
线程 (Threads):
- 显示当前所有活动线程的列表及其状态 (Runnable, Waiting, Blocked, Timed Waiting)。
- 可以查看每个线程的堆栈跟踪信息。
- 提供检测死锁 (Detect Deadlock) 的功能。
- 显示峰值线程数和当前活动线程数。
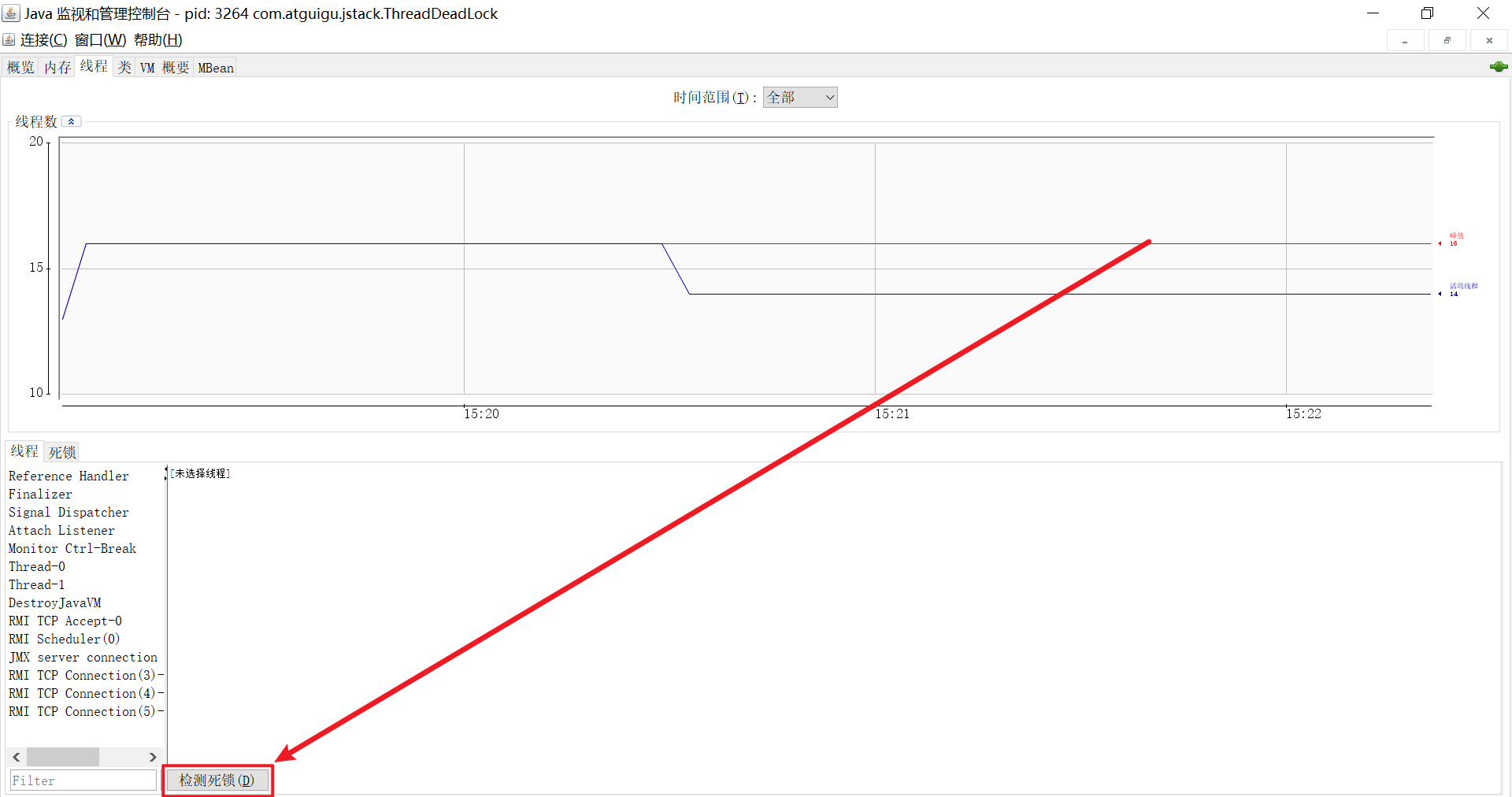 图:JConsole - 线程标签页
图:JConsole - 线程标签页
类 (Classes):
- 显示当前已加载类的总数和已卸载类的总数。
- 提供类加载活动的实时曲线图。
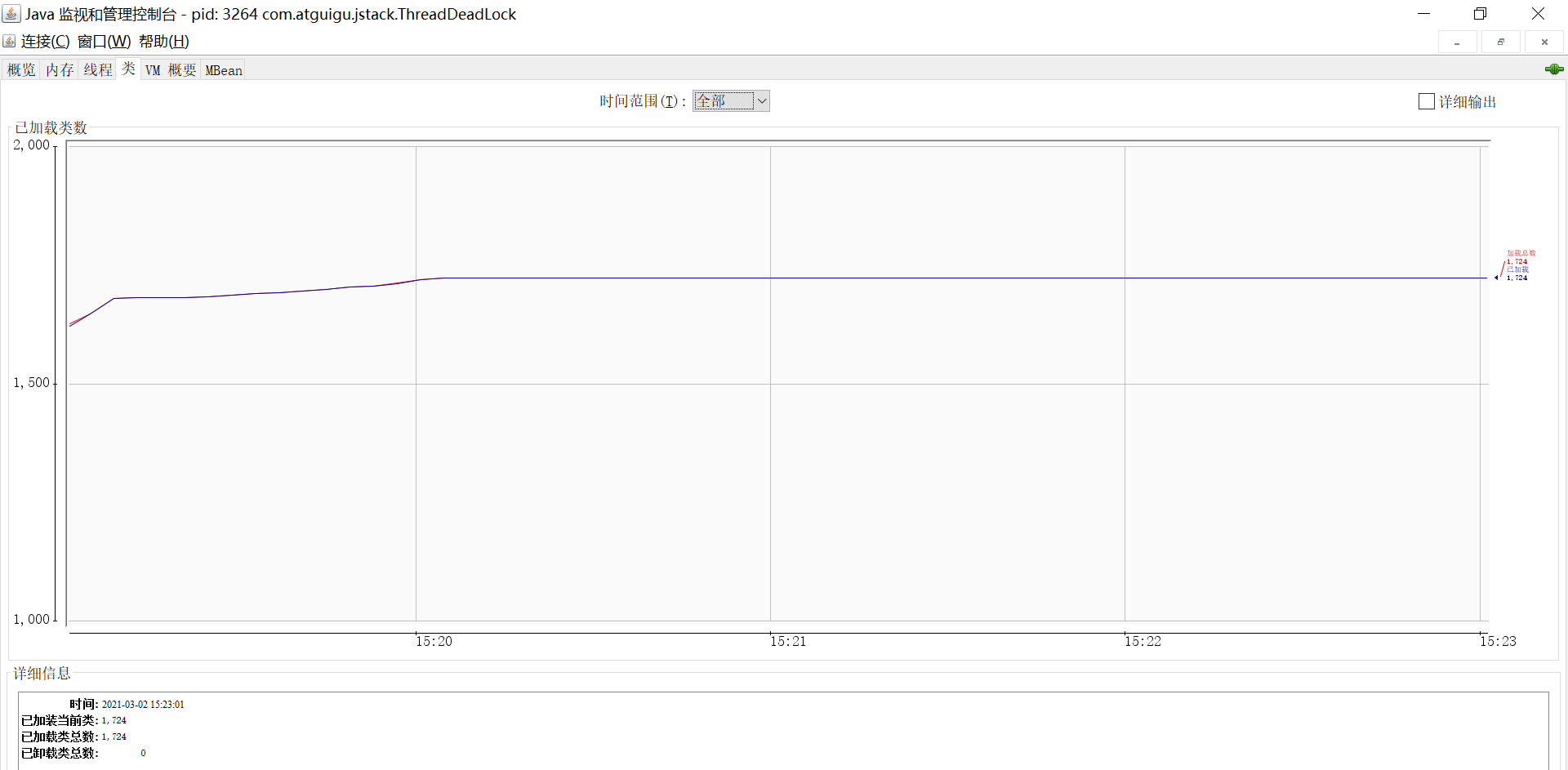 图:JConsole - 类标签页
图:JConsole - 类标签页
VM 摘要 (VM Summary):
- 汇总显示 JVM 的详细信息,包括:
- 虚拟机版本、供应商、运行时间。
- JVM 参数 (VM arguments)。
- 类路径 (Classpath)、库路径 (Library path)。
- 系统属性 (System properties)。
- 操作系统信息。
- 内存和 GC 配置概要。
 图:JConsole - VM 摘要标签页
图:JConsole - VM 摘要标签页
- 汇总显示 JVM 的详细信息,包括:
MBean (Managed Bean):
- 提供对 JVM 内部所有已注册的 MBean 的访问。
- 可以通过 MBean 查看更底层的 JVM 指标、执行特定的管理操作(如修改某些属性值、调用管理方法)。
- 例如,可以查看
java.lang:type=Memory获取内存信息,java.lang:type=Threading获取线程信息,java.lang:type=GarbageCollector获取 GC 信息等。
JConsole 功能相对基础,但作为 JDK 自带工具,无需额外安装,是快速了解 JVM 运行状态的便捷选择。
# 3. VisualVM:多合一可视化监控与分析平台
官方地址:
https://visualvm.github.io/index.html
VisualVM 是一个功能更强大的多合一故障诊断和性能监控可视化工具。它整合了多个 JDK 命令行工具的功能(如 jps, jinfo, jstat, jstack, jmap),并提供了更友好的图形界面。自 JDK 6 Update 7 以后,VisualVM 作为 JDK 的一部分随之发布(位于 JDK 的 bin 目录下),完全免费。
核心特性:
- 集成多种工具能力:在一个界面中完成进程查看、环境配置查看、CPU/内存/线程/类监控、线程 Dump、堆 Dump 等操作。
- 性能分析 (Profiling):可以对 CPU 和内存进行抽样 (Sampling) 或插桩 (Instrumentation) 分析,找出性能瓶颈和内存分配热点。
- 内存快照分析:可以直接生成和打开 Heap Dump 文件,进行基本的内存泄漏分析。
- 插件化扩展:支持安装插件来扩展功能,例如著名的 Visual GC 插件可以动态可视化 GC 过程和内存分布。
- 支持本地和远程连接:与 JConsole 类似,支持监控本地和远程 JVM 进程(远程连接同样需要目标 JVM 配置 JMX)。
插件安装:
VisualVM 的强大之处在于其插件系统。
- 在线安装:通过菜单
工具 (Tools)->插件 (Plugins)->可用插件 (Available Plugins),选择需要的插件(如Visual GC)进行在线安装。 - 离线安装:从 VisualVM 插件中心 (opens new window) 下载插件文件 (
.nbm格式),然后在插件 (Plugins)对话框的已下载 (Downloaded)页面,点击添加插件 (Add Plugins...)进行安装。
强烈建议安装 Visual GC 插件,它可以非常直观地展示堆内存的分代布局、对象分配和 GC 活动。
在 IDE 中集成 (以 IntelliJ IDEA 为例):
- 在 IDEA 的插件市场搜索并安装
VisualVM Launcher插件。
- 重启 IDEA。
- 配置 VisualVM 的可执行文件路径:
File->Settings->Tools->VisualVM Launcher,指定你 JDKbin目录下的jvisualvm.exe(Windows) 或jvisualvm(Linux/macOS) 路径。
- 之后就可以在运行/调试配置中,或者直接右键点击运行中的应用,选择
Run with VisualVM或Debug with VisualVM来启动并自动连接 VisualVM。
连接方式:
本地连接:启动 VisualVM 后,它会自动发现本地运行的 Java 进程,列在左侧的“应用程序 (Applications)”窗格中,双击即可连接。
远程连接:
- 右键点击“远程 (Remote)”节点,选择“添加远程主机 (Add Remote Host...)”,输入远程服务器的 IP 地址或主机名。
- 确保远程 JVM 进程已配置 JMX 端口并已启动。
- 右键点击添加的主机节点,选择“添加 JMX 连接 (Add JMX Connection...)”,输入 JMX 服务的端口号(以及可能的用户名/密码),进行连接。
- (对于 Tomcat 等应用服务器,可能需要修改其启动脚本如
catalina.sh或catalina.bat来添加 JMX 参数,并可能需要在conf目录下配置jmxremote.access和jmxremote.password文件进行安全认证。同时确保防火墙和安全组策略允许 JMX 端口的访问。)
主要功能界面:
连接到一个 Java 进程后,VisualVM 会显示多个标签页:
- 概述 (Overview):显示 JVM 基本信息、JVM 参数、系统属性等,类似于
jinfo的功能。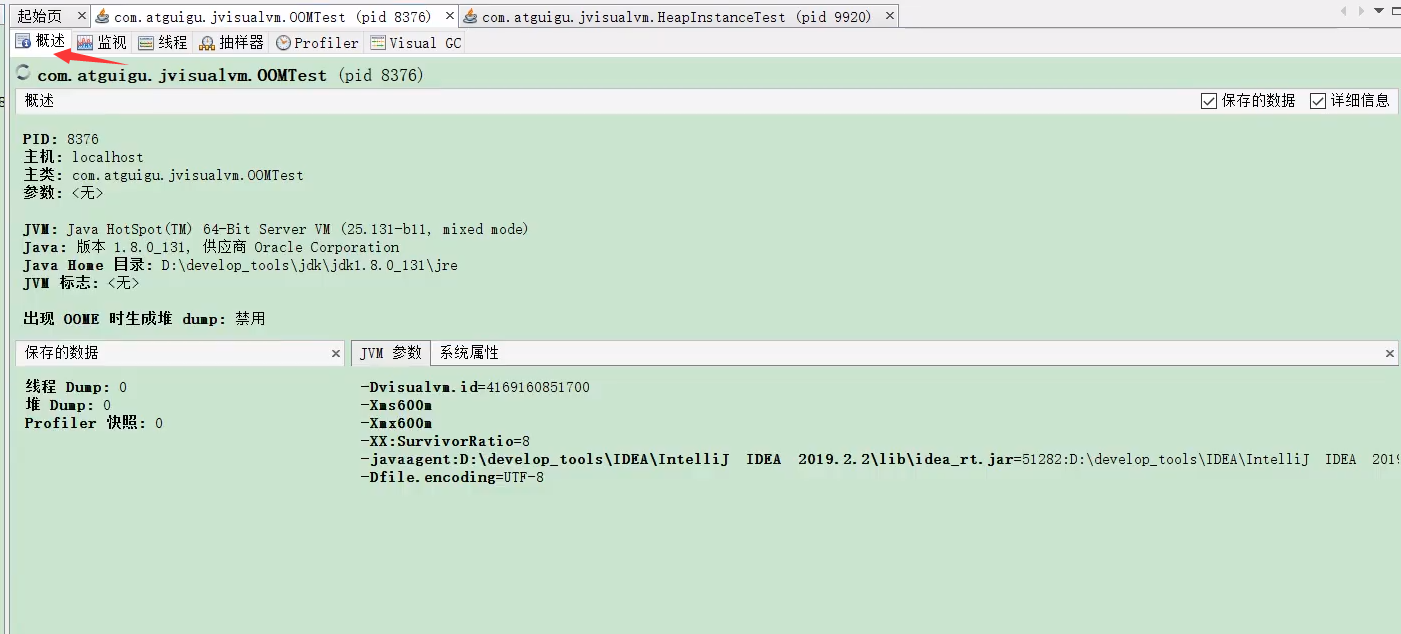
- 监视 (Monitor):
- 提供 CPU、内存(堆、元空间/永久代)、类加载、线程数量的实时监控图表,类似于
jstat和 JConsole 的功能。 - 可以手动执行垃圾回收。
- 可以生成堆 Dump (Heap Dump) 文件。
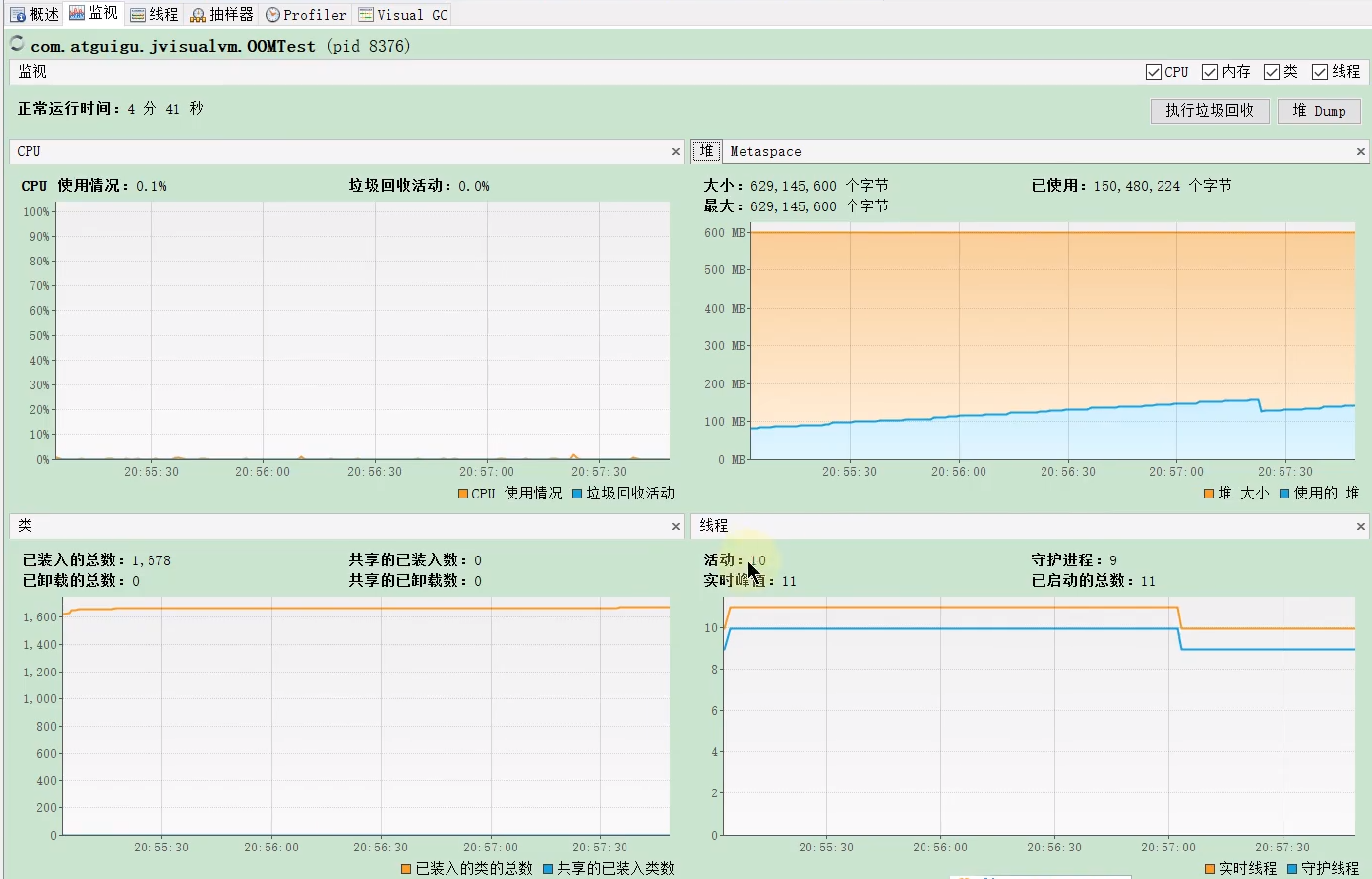
- 提供 CPU、内存(堆、元空间/永久代)、类加载、线程数量的实时监控图表,类似于
- 线程 (Threads):
- 实时显示所有线程的状态(列表和时间线视图)。
- 可以选择单个线程查看其堆栈跟踪。
- 可以生成线程 Dump (Thread Dump),相当于执行
jstack。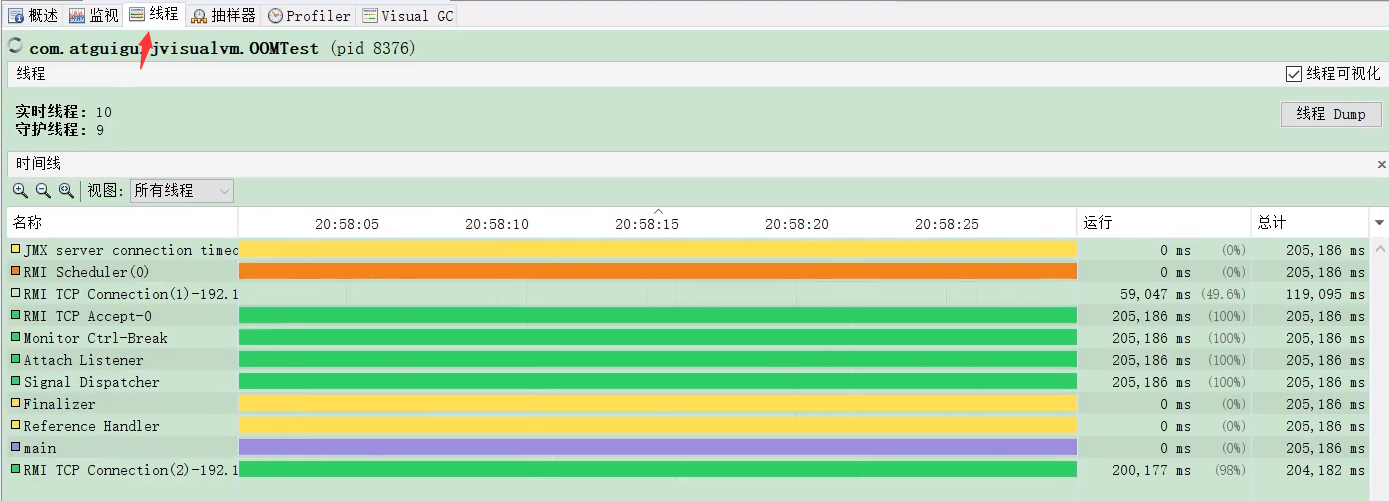
- 抽样器 (Sampler) / Profiler:
- CPU 分析:通过抽样或插桩的方式,分析哪些方法消耗了最多的 CPU 时间。
- 内存分析:分析对象的创建频率、内存占用,查找内存分配热点。
- 性能分析会对目标应用产生一定开销,特别是插桩模式。
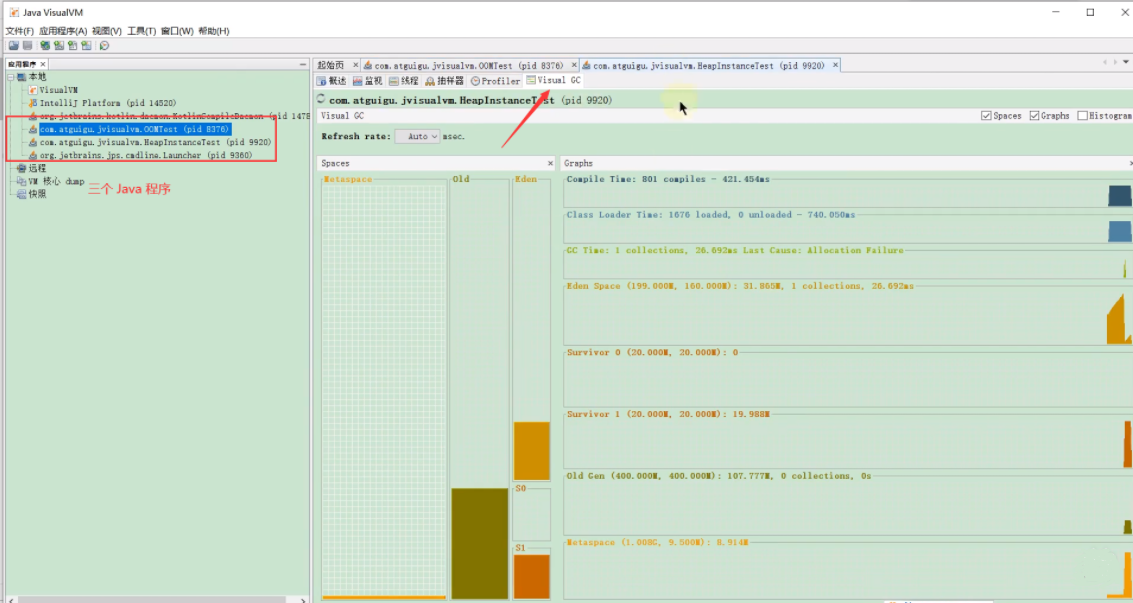
- Visual GC (需要安装插件):
- 动态、可视化地展示堆内存(Eden, S0, S1, Old)和元空间的使用情况。
- 实时显示 GC 活动(Minor GC, Full GC)的次数和耗时。
- 非常直观地理解 GC 过程和内存分配模式。
- 快照 (Snapshots):
- 可以在这里查看已生成的堆 Dump 或线程 Dump 文件。
- VisualVM 提供了基本的堆 Dump 分析功能,可以查看对象列表、查找大对象等。
VisualVM 功能比 JConsole 更全面,尤其是在性能分析和 GC 可视化方面,是 Java 开发和调优的常用工具。
# 4. Eclipse MAT:专业的堆内存分析器
官方地址:
https://www.eclipse.org/mat/downloads.php
MAT (Memory Analyzer Tool) 是一款功能强大的、免费开源的 Java 堆内存分析器。它基于 Eclipse 平台开发(可以作为 Eclipse 插件使用,也可以作为独立应用运行),专门用于深入分析 Heap Dump 文件 (.hprof)。
核心目标:
- 查找内存泄漏 (Memory Leaks):通过分析对象引用关系、可达性、支配树等,帮助定位不再被需要但无法被 GC 回收的对象。
- 减少内存消耗 (Reduce Memory Consumption):识别占用内存过多的对象、重复对象、优化集合类使用等。
获取 Heap Dump 文件的方式:
MAT 本身不直接监控运行中的 JVM,它需要一个 .hprof 格式的堆转储文件作为输入。获取 dump 文件的方式有多种:
jmap 命令:
jmap -dump:live,format=b,file=heap.hprof <pid>1JVM 参数自动 Dump:
# OOM 时自动 dump -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/path/to/heapdump.hprof # Full GC 前自动 dump (某些场景下有用,但会影响性能) # -XX:+HeapDumpBeforeFullGC1
2
3
4VisualVM / JConsole:这些工具提供了手动触发生成 Heap Dump 的按钮。
MAT 直接获取:MAT 也可以连接到正在运行的 Java 进程(通过 JMX 或其他方式)并直接触发和获取 Heap Dump。
Arthas 命令:
heapdump /path/to/heapdump.hprof。
考虑到生产环境中直接在线分析大型 dump 文件不现实,最常见的组合是使用 jmap 或 JVM 参数在生产环境生成 dump 文件,然后将文件下载到本地使用 MAT 进行离线分析。
MAT 核心功能与界面:
打开 Dump 文件:启动 MAT,选择
File->Open Heap Dump...选择.hprof文件。MAT 在打开大型 dump 文件时可能需要较多内存和时间。
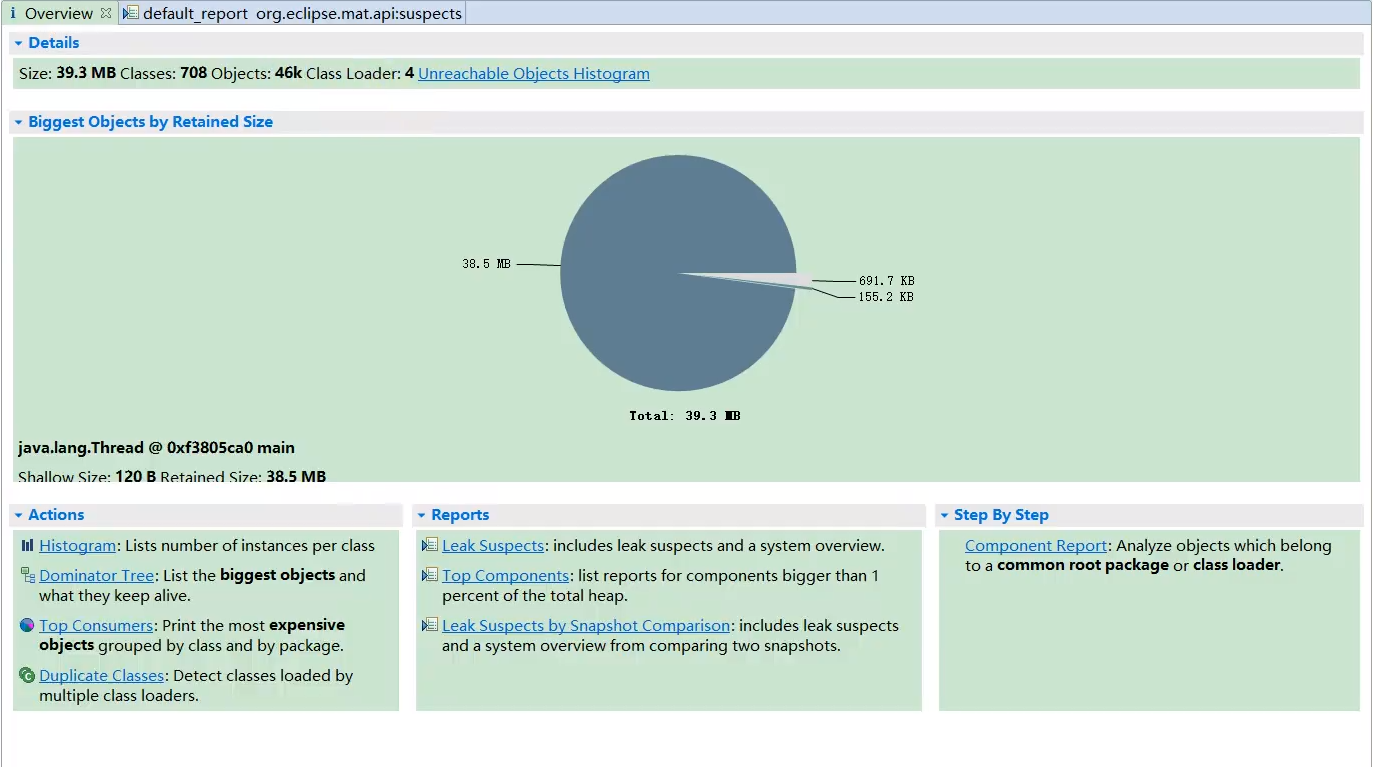
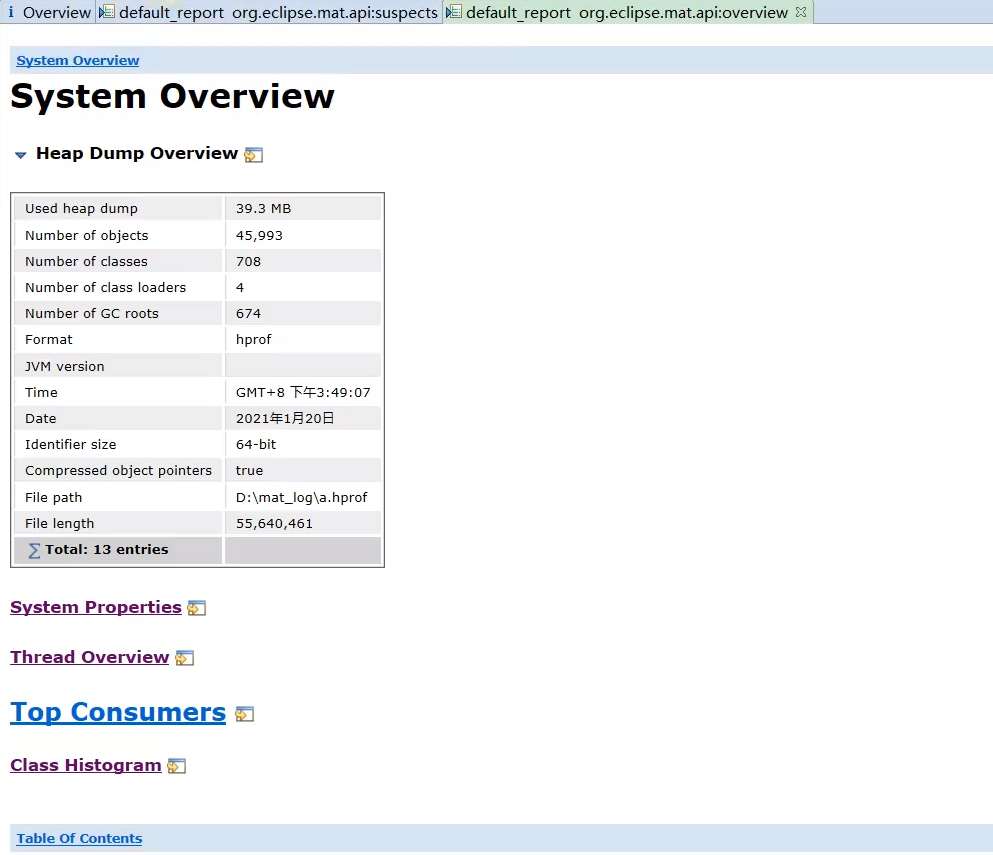
概览 (Overview):
- 打开 dump 文件后首先看到的界面。
- 显示 dump 文件的基本信息:大小、创建时间、对象数量、类数量、类加载器数量等。
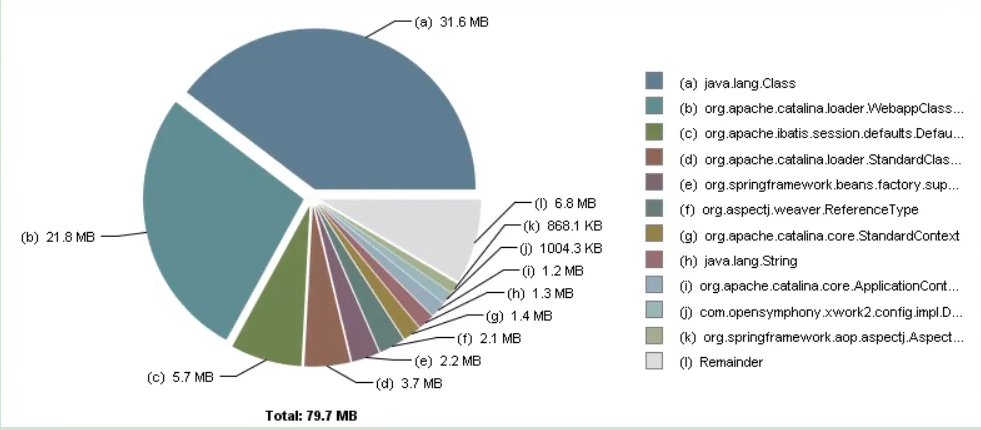
- 提供一个饼图展示最大的几个对象(按 Retained Heap 排序)。
- 包含几个关键的快捷操作入口:
- Histogram: 查看所有类的实例数量和大小。
- Dominator Tree: 查看对象支配树。
- Top Consumers: 按类或类加载器聚合,查看内存消耗大户。
- Leak Suspects: MAT 的核心功能之一,自动分析并报告可能的内存泄漏点。
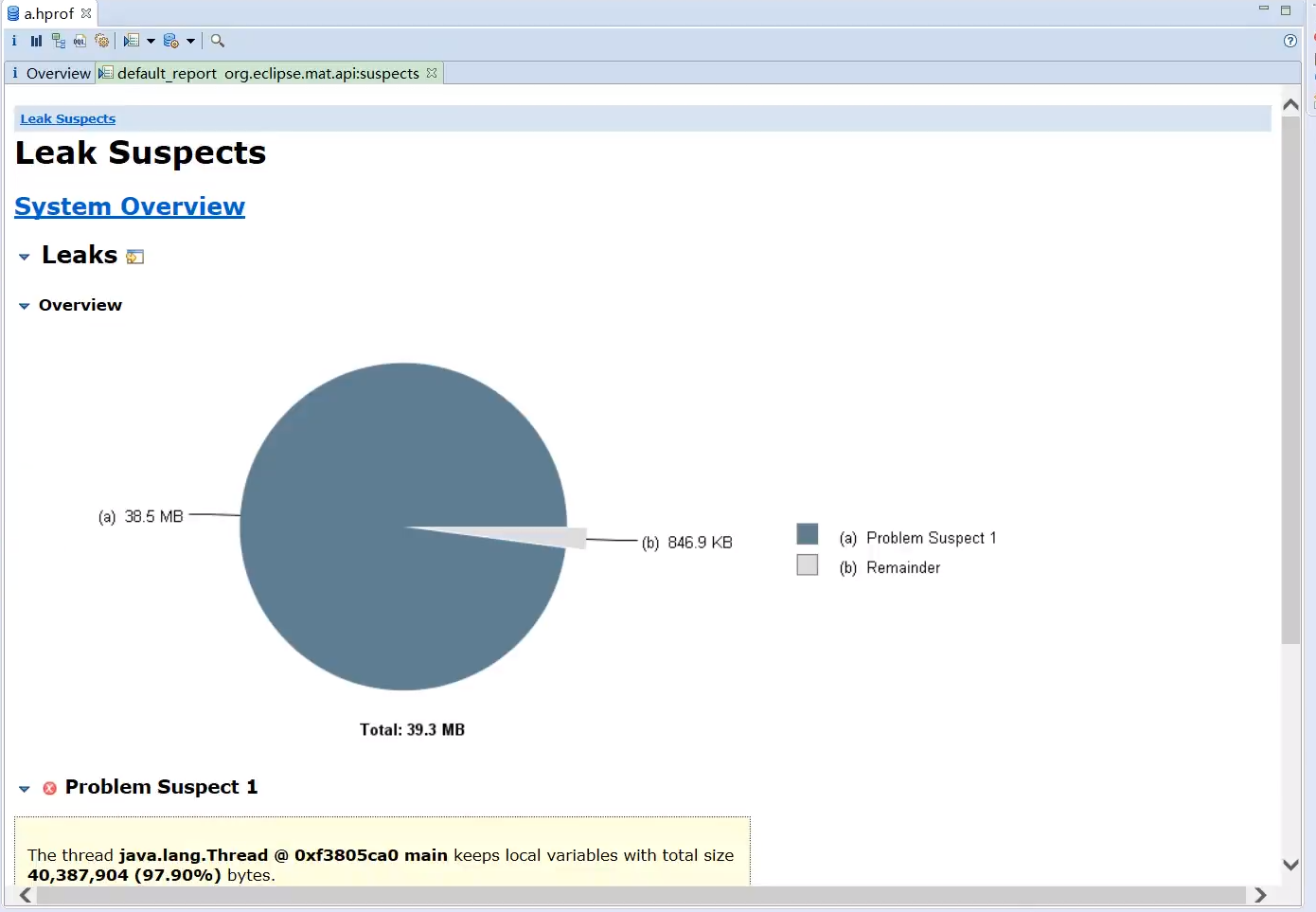
直方图 (Histogram):
- 列出堆中每个类的实例数量 (Objects)、浅堆大小 (Shallow Heap) 和深堆大小 (Retained Heap)。
- 可以通过类名、包名进行分组和过滤。
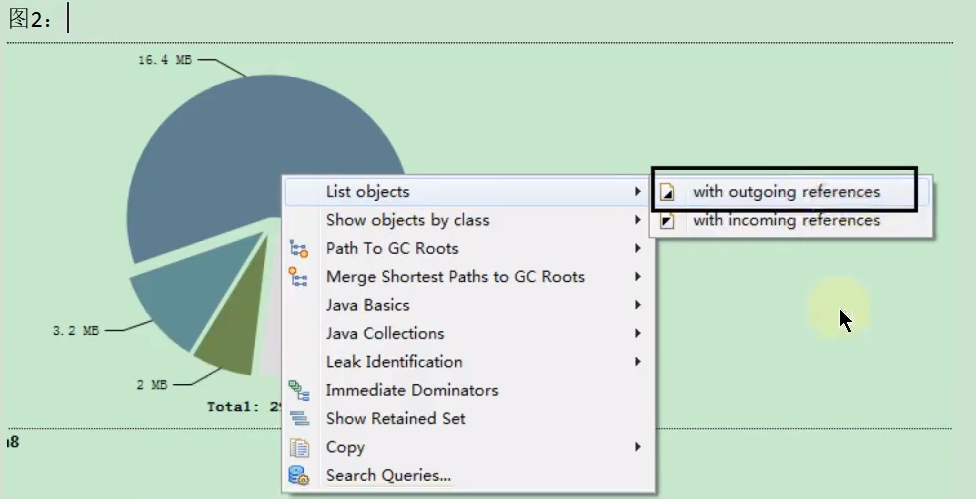
- 右键点击某个类,可以进行更多操作:
List objects: 查看该类的所有实例。with outgoing references: 查看该实例引用的其他对象。with incoming references: 查看引用该实例的其他对象。
Merge Shortest Paths to GC Roots: 查找该类的实例到 GC Roots 的最短引用路径,这是分析对象为何没有被回收的关键。Show objects by class in Dominator Tree: 在支配树视图中定位该类的实例。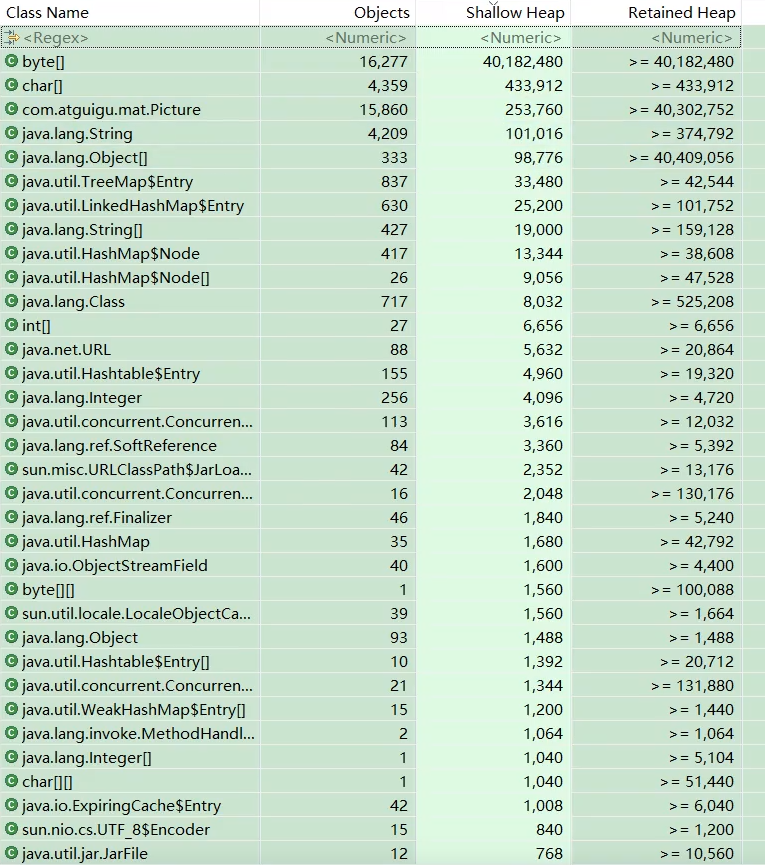
支配树 (Dominator Tree):
- 将复杂的对象引用关系转换为一棵树状结构,清晰地展示对象的支配关系。
- 定义:如果所有指向对象 B 的路径都必须经过对象 A,那么对象 A 支配 B。离 B 最近的支配者称为直接支配者。
- 关键特性:
- 对象 A 的子树(所有被 A 支配的对象)构成了 A 的保留集 (Retained Set),子树中所有对象的浅堆大小之和就是 A 的深堆大小 (Retained Heap)。
- 深堆大小表示如果对象 A 被回收,能够释放多少内存。
- 支配树是查找内存消耗大户(Retained Heap 大的对象)的有力工具。
- 视图中会列出所有对象(或按类分组),按 Retained Heap 大小排序。
 (图:右键菜单,可查看支配关系)
(图:右键菜单,可查看支配关系)
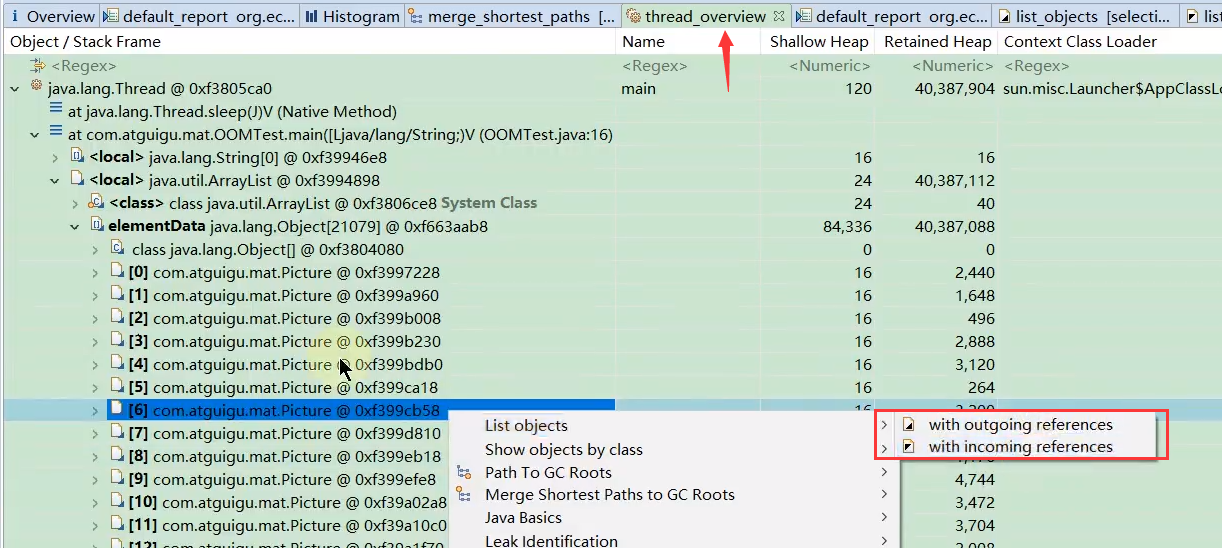
线程概览 (Thread Overview):
- 列出 dump 时所有线程的信息,包括线程名、状态和线程栈信息。
- 可以查看每个线程栈帧中的局部变量。这对于分析某些线程持有大对象或特定状态很有用。

核心概念:浅堆 (Shallow Heap) 与 深堆 (Retained Heap)
理解这两个概念对于使用 MAT至关重要:
浅堆 (Shallow Heap):
- 指对象本身占用的内存大小,不包括它引用的其他对象。
- 计算方式:对象头大小 + 各个成员变量大小的总和 (+ 可能的对齐填充)。
- 例如,一个
String对象本身的浅堆可能只包含其内部char[] value的引用、int hash等字段的大小以及对象头,与其包含的字符串长度无关。
保留集 (Retained Set):
- 指仅能通过某个对象 A 直接或间接访问到的所有对象的集合(包含 A 自身)。
- 换句话说,如果对象 A 被垃圾回收,那么它的 Retained Set 中的所有对象也将因为不再可达而被回收。
深堆 (Retained Heap):
- 指对象 A 的保留集中所有对象的浅堆大小之和。
- 深堆代表了如果对象 A 被回收,GC 能够释放的总内存大小。这是衡量一个对象“真实”内存占用的关键指标。
对象实际大小 (Actual Size) (非 MAT 标准术语,易混淆):
- 指一个对象能访问到的所有对象的浅堆大小之和(包括可以通过其他路径访问的对象)。
- 这个概念与垃圾回收关系不大,不如深堆有用。
图解区分:
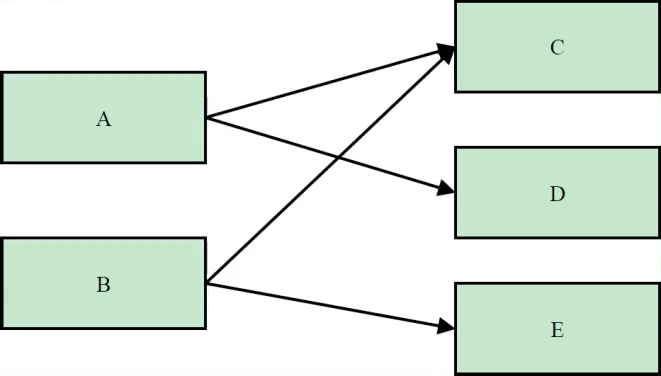
- A 的浅堆: 只有 A 本身的大小。
- A 的实际大小: A + C + D 的浅堆之和。
- A 的保留集: {A, D} (因为 C 还可以通过 B 访问)。
- A 的深堆: A 的浅堆 + D 的浅堆。
- B 的保留集: {B, E} (因为 C 还可以通过 A 访问)。
- B 的深堆: B 的浅堆 + E 的浅堆。
练习题图解:
场景 1: GC Roots 同时引用 A, B, D 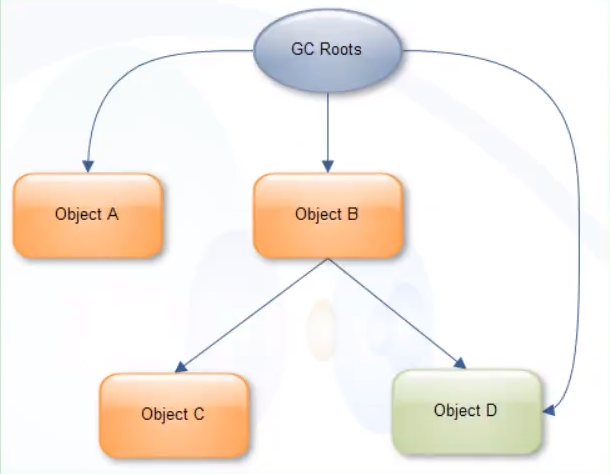
- A 的 Retained Set = {A} => A 的 Retained Size = A 的 Shallow Size
- B 的 Retained Set = {B, C} (C 只能通过 B 访问) => B 的 Retained Size = B 的 Shallow Size + C 的 Shallow Size
- D 的 Retained Set = {D} => D 的 Retained Size = D 的 Shallow Size
场景 2: GC Roots 只引用 A, B 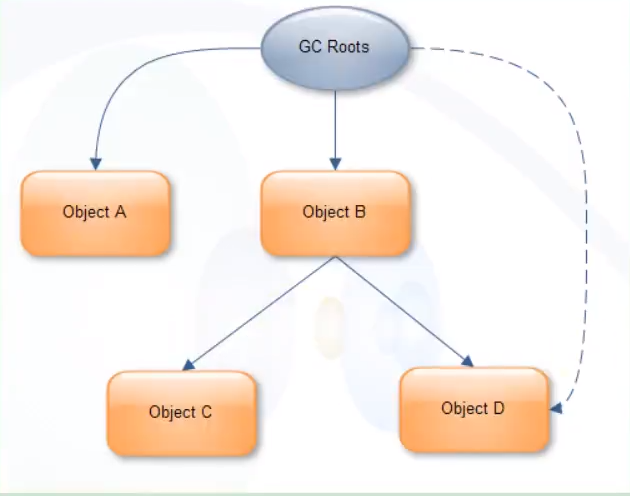
- A 的 Retained Set = {A} => A 的 Retained Size = A 的 Shallow Size
- B 的 Retained Set = {B, C, D} (C, D 只能通过 B 访问) => B 的 Retained Size = B + C + D 的 Shallow Size 之和
深堆与浅堆案例分析 (StudentTrace.java)
这个案例模拟了多个学生访问网页,并将访问历史记录在各自的 history (ArrayList) 中。WebPage 对象最初存储在一个静态 webpages 列表中,然后被添加到学生的 history 中。最后,静态列表 webpages 被 clear(),并执行 System.gc()。
import java.util.ArrayList;
import java.util.List;
/**
* 模拟学生浏览网页记录的程序。
* 用于分析对象引用和内存占用(深堆/浅堆)。
* 启动参数示例: -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\student.hprof
*/
public class StudentTrace {
// 静态列表,持有所有 WebPage 对象
static List<WebPage> webpages = new ArrayList<WebPage>();
/**
* 创建 100 个模拟的 WebPage 对象并添加到静态列表中。
*/
public static void createWebPages() {
for (int i = 0; i < 100; i++) {
WebPage wp = new WebPage();
wp.setUrl("http://www." + Integer.toString(i) + ".com"); // 设置 URL
wp.setContent(Integer.toString(i)); // 设置内容
webpages.add(wp);
}
}
public static void main(String[] args) {
createWebPages(); // 创建 100 个网页
// 创建 3 个学生对象
Student st3 = new Student(3, "Tom");
Student st5 = new Student(5, "Jerry");
Student st7 = new Student(7, "Lily");
// 模拟学生访问网页,将 WebPage 添加到各自的 history 列表
for (int i = 0; i < webpages.size(); i++) {
if (i % st3.getId() == 0) // 如果 i 能被 3 整除
st3.visit(webpages.get(i));
if (i % st5.getId() == 0) // 如果 i 能被 5 整除
st5.visit(webpages.get(i));
if (i % st7.getId() == 0) // 如果 i 能被 7 整除
st7.visit(webpages.get(i));
}
// 清除静态列表的引用。此时 WebPage 对象仅被学生的 history 列表引用。
webpages.clear();
webpages = null; // 显式置 null 更好
// 建议 GC,但不保证立即执行。Heap Dump 如果在这之后生成,应该只包含被学生引用的 WebPage。
System.gc();
// (实际 dump 可能在 GC 前或 OOM 时发生,取决于 JVM 参数)
// 为了分析,可以加一个断点或 sleep 在这里手动 dump。
try {
Thread.sleep(10000); // 等待 dump
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Student {
private int id;
private String name;
// 每个学生持有一个 WebPage 列表作为访问历史
private List<WebPage> history = new ArrayList<>();
public Student(int id, String name) {
super();
this.id = id;
this.name = name;
}
// Getters and Setters ...
public int getId() { return id; }
public void setId(int id) { this.id = id; }
public String getName() { return name; }
public void setName(String name) { this.name = name; }
public List<WebPage> getHistory() { return history; }
public void setHistory(List<WebPage> history) { this.history = history; }
/**
* 学生访问一个网页,将其添加到历史记录中。
* @param wp 被访问的 WebPage 对象。
*/
public void visit(WebPage wp) {
if (wp != null) {
history.add(wp);
}
}
}
class WebPage {
private String url;
private String content;
// Getters and Setters ...
public String getUrl() { return url; }
public void setUrl(String url) { this.url = url; }
public String getContent() { return content; }
public void setContent(String content) { this.content = content; }
// 为了方便在 MAT 中查看,可以重写 toString
@Override
public String toString() {
return "WebPage{" + "url='" + url + '\'' + '}';
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
分析过程:
- 使用 JVM 参数
-XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=d:\student.hprof(或 OOM 参数,或手动 dump) 运行代码,生成student.hprof文件。 - 用 MAT 打开 dump 文件。
- 导航到 Dominator Tree 或 Histogram 视图,查找
Student类的实例。 - 找到
st7(id=7, name="Lily") 这个Student对象。查看其深堆 (Retained Heap) 大小。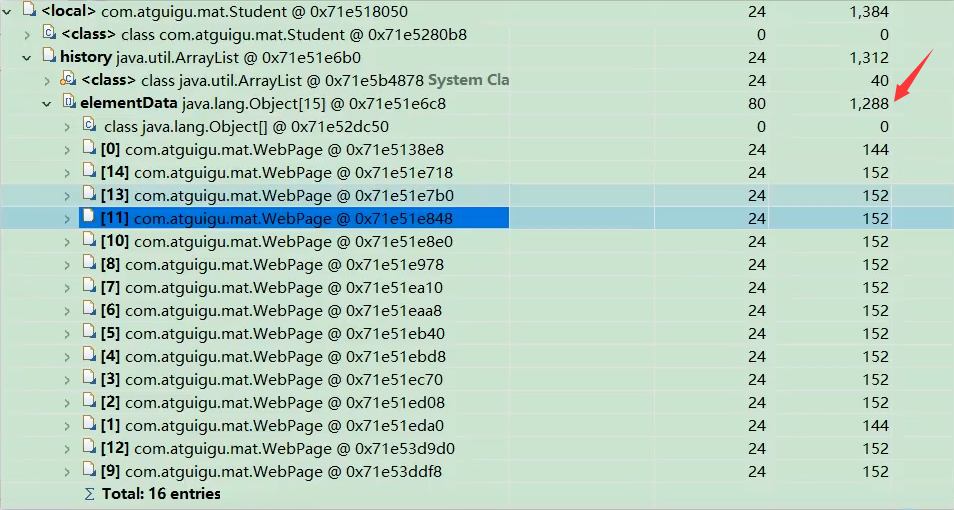 图:MAT 中显示 st7 的 Retained Heap 为 1288 字节
图:MAT 中显示 st7 的 Retained Heap 为 1288 字节
解释 1288 字节的来源:
st7访问了索引能被 7 整除的WebPage对象 (0, 7, 14, ..., 98),共 15 个。st7.history是一个ArrayList,其内部持有一个Object[] elementData数组来存储这 15 个WebPage对象的引用。- 哪些
WebPage对象仅被st7持有?- 我们需要考虑
st3(id=3) 和st5(id=5) 也访问了某些页面。 - 如果一个页面的索引
i只能被 7 整除,而不能被 3 或 5 整除,那么这个WebPage对象就只被st7引用(因为webpages列表已被清空)。 - 在 0 到 99 之间,仅能被 7 整除的数有:7, 14, 28, 49, 56, 77, 91, 98。共 8 个。
- 能被 7 和 3 整除的有:21, 42, 63, 84。 (属于 st7 和 st3 共有)
- 能被 7 和 5 整除的有:35, 70。 (属于 st7 和 st5 共有)
- 能被 3, 5, 7 整除的有:0。 (属于 st3, st5, st7 共有)
- 我们需要考虑
- 计算
st7的深堆 (Retained Heap):st7对象本身的浅堆 (Shallow Heap)。st7.history(ArrayList) 对象本身的浅堆。st7.history.elementData(Object[]) 数组本身的浅堆。- 仅被
st7引用的 8 个WebPage对象的浅堆之和。 - 每个
WebPage对象包含url和content两个String引用,以及对象头。假设每个WebPage浅堆为 X 字节。 - 每个
String对象 (url, content) 也有浅堆,并且它们内部的char[]数组也有浅堆。这些也可能被计算在内,如果它们仅被对应的WebPage引用。
- 反推 1288 字节:
- 图中显示
st7的history列表(elementData)有 15 个元素。 - 如果 Retained Heap 只计算了仅被
st7持有的对象,那么它应该包含st7自身、history列表、elementData数组,以及那 8 个“私有”的WebPage对象(及其可能包含的 String 和 char[])。 - 原文档的计算过程似乎有些偏差,它提到 “15 个 WebPage,每个对应 152 个字节”,这可能是指
WebPage的深堆(如果假设每个页面都是私有的)。 - 然后计算了“共有”的页面 (7 个),用总的减去共有的,得到
2280 - 1064 = 1216。这个1216接近1288,但还差72。 - 原文档解释
72字节是elementData数组本身的开销(15个引用 * 4字节/引用 + 8字节对象头 + 4字节数组长度 = 72字节,按8字节对齐)。 - 更合理的解释:
st7的 Retained Heap (1288 字节) =st7自身浅堆 +history浅堆 +elementData浅堆 (72 字节) + 8 个仅被 st7 引用的 WebPage 对象及其内容的 Retained Heap 之和。 这 8 个 WebPage 及其内容的总 Retained Heap 应该是1288 - 72 - (st7 浅堆) - (history 浅堆)。或者,如果 152 字节是 WebPage 及其内容 的 Retained Heap,那么 8 个私有页面贡献8 * 152 = 1216字节,加上elementData的 72 字节,总计1216 + 72 = 1288字节。这似乎是更可能的解释,即 MAT 计算的st7的 Retained Heap 主要包含了其“私有”的WebPage对象所占用的内存。
- 图中显示
支配树 (Dominator Tree) 的应用:
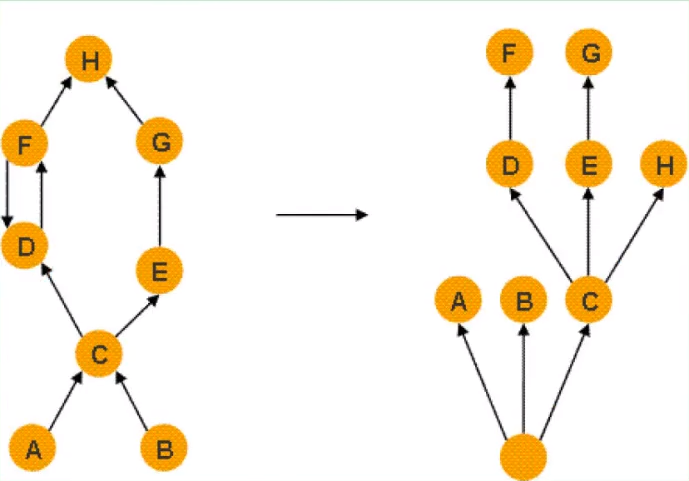 左图:对象引用图;右图:对应的支配树
左图:对象引用图;右图:对应的支配树
- 理解:支配树简化了引用关系,直接展示内存控制流。根节点(GC Roots)支配所有可达对象。如果 A 的子节点是 B,意味着要回收 B,必须先断开 A 到 B 的路径(或者 A 本身被回收)。
- 查找大对象根源:在支配树视图中,可以直接看到哪个对象的 Retained Heap 最大。展开该对象的子树,可以看到是哪些被它支配的对象贡献了内存。
- 分析案例:
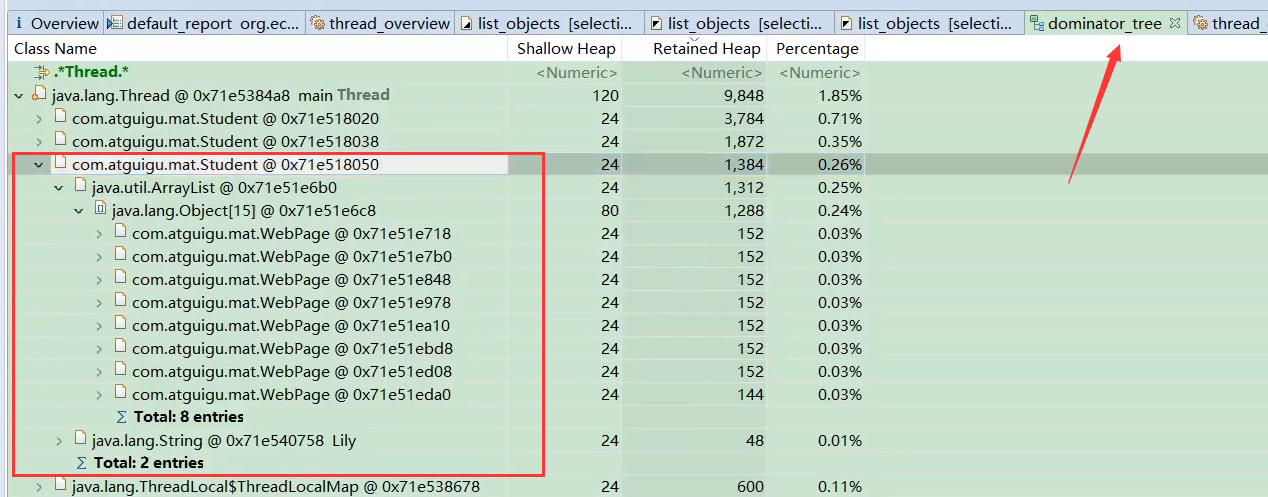 图:在支配树中查看 st7 的 elementData
图:在支配树中查看 st7 的 elementData - 这个视图显示了
st7的elementData数组。展开它,可以看到它直接支配(即持有引用)的 15 个WebPage对象。 - 支配树可以更清晰地展示哪些
WebPage对象(及其内容)被计算在了elementData数组的 Retained Heap 中(即仅通过这个数组才能访问到的对象)。图中应该能看到 8 个WebPage出现在elementData的子树中,贡献了主要的 Retained Heap。
- 这个视图显示了
Tomcat 堆溢出分析案例 (基于图片解读)
这个案例分析了一个因请求压力过大导致 Tomcat 发生 OOM 的 Heap Dump 文件。
概览与最大对象:
- 图 1 显示 MAT 概览,提示有一个
org.apache.catalina.session.StandardManager对象占用了大量内存。 - 图 2 Leak Suspects 报告也指向了同一个
StandardManager,暗示 Session 管理可能是问题所在。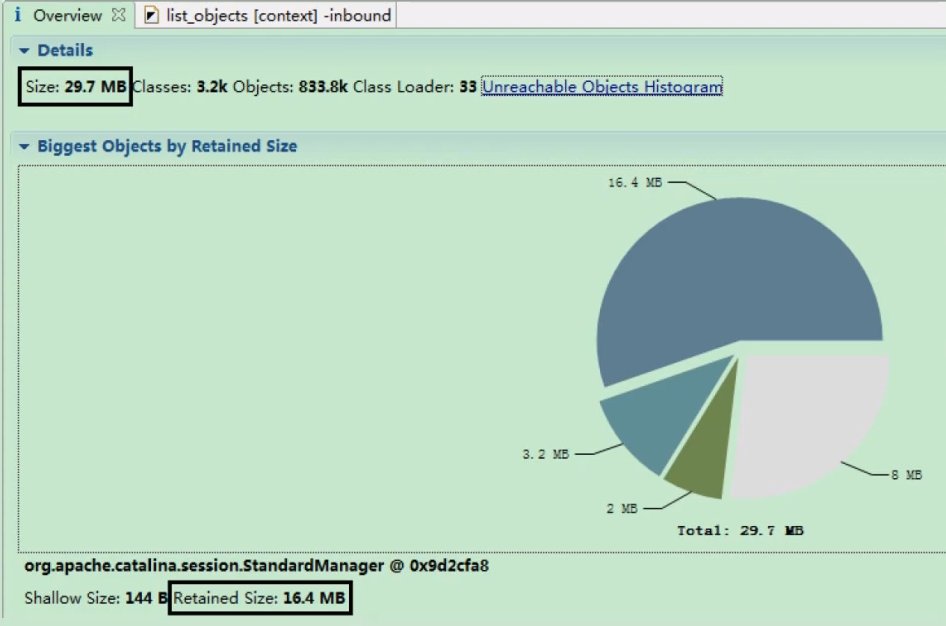
- 图 1 显示 MAT 概览,提示有一个
深入 StandardManager:
- 在 Dominator Tree 中找到
StandardManager,发现其内部持有一个名为sessions的ConcurrentHashMap,这个 Map 占用了约 17MB 的 Retained Heap。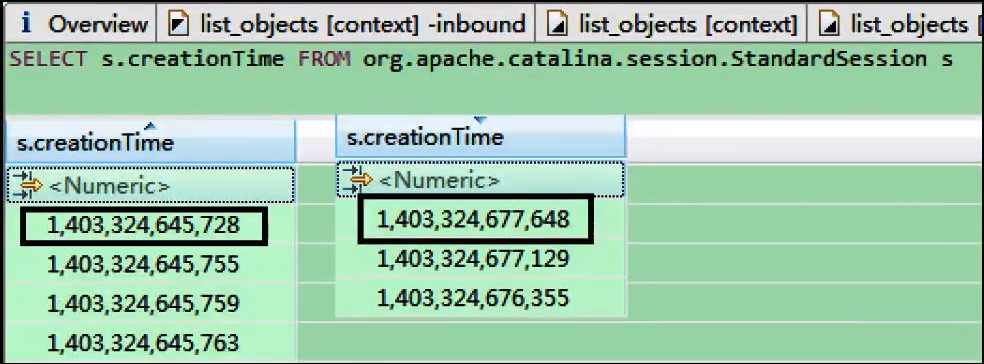
- 在 Dominator Tree 中找到
分析 ConcurrentHashMap:
- 展开
sessions(ConcurrentHashMap),可以看到它内部分为 16 个Segment(这是旧版 ConcurrentHashMap 的实现方式)。 - 每个
Segment的 Retained Heap 大小都比较平均,约为 1MB。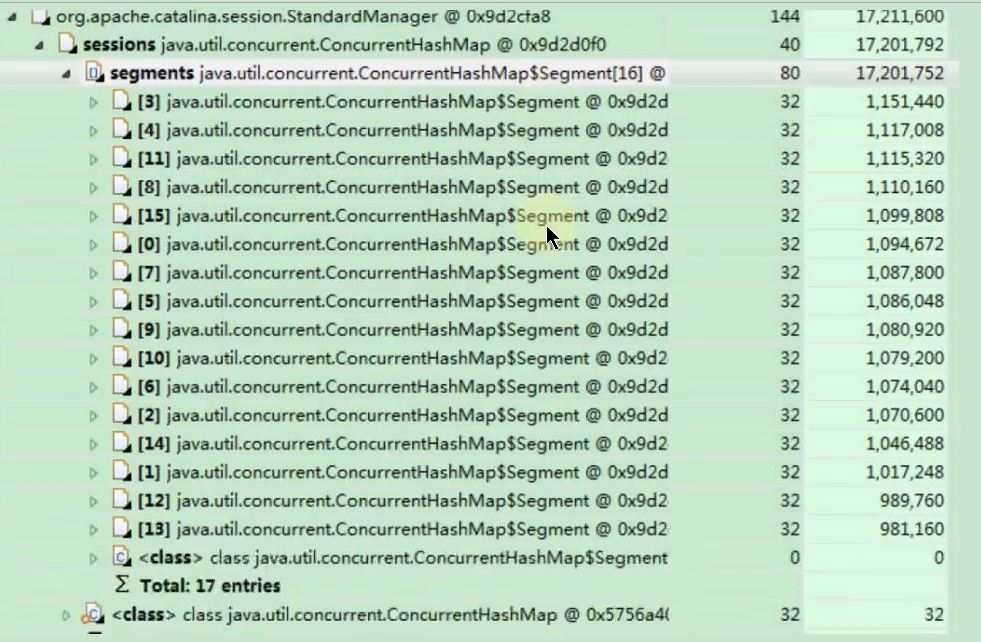
- 展开
查看 Segment 内容:
- 展开其中一个
Segment,可以看到它内部持有一个HashEntry[]数组,数组中存储了大量的StandardSession对象引用。
- 展开其中一个
统计 Session 数量和大小:
- 切换到 Histogram 视图,搜索
org.apache.catalina.session.StandardSession。 - 结果显示,堆中总共有 9941 个
StandardSession实例。 - 每个
StandardSession的浅堆 (Shallow Heap) 很小 (如 112 字节),但深堆 (Retained Heap) 约为 1592 字节(这表示每个 Session 对象及其关联的、仅能通过它访问的数据占用了约 1.5KB)。 - 所有 Session 的总 Retained Heap 约为
9941 * 1592 ≈ 15.8MB,与之前看到的ConcurrentHashMap的 Retained Heap (17MB) 基本吻合,说明内存主要被 Session 对象及其关联数据占据。这占用了当时堆大小 (约 30MB+) 的 50% 以上。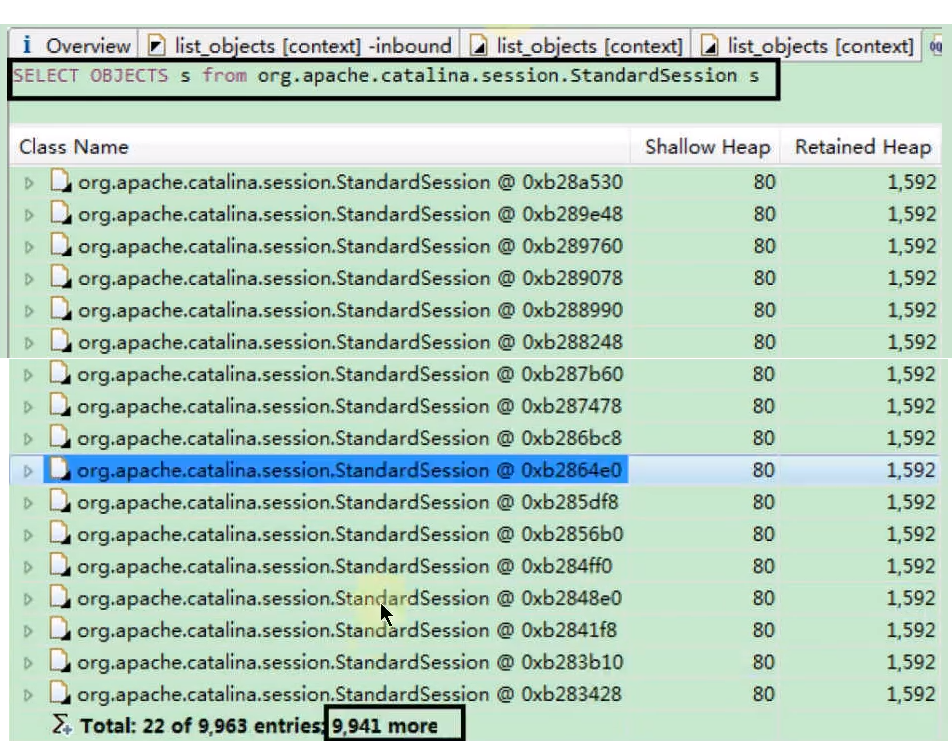
- 切换到 Histogram 视图,搜索
关联 Session 属性:
- 查看
StandardSession对象的attributes属性(通常是一个ConcurrentHashMap),可以看到 Session 中存储了哪些数据。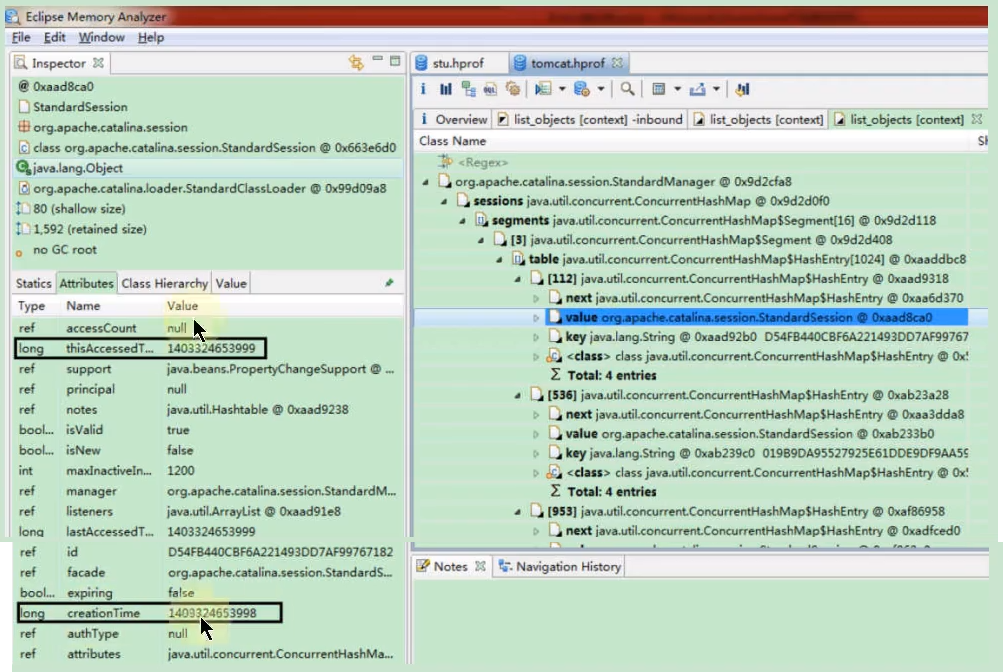
- 查看
结合时间信息推断压力:
- 查看某个
StandardSession的creationTime和lastAccessedTime属性,可以得到 Session 的创建时间和最后访问时间(通常是 long 型时间戳)。 - 图 8 显示了 Session 的创建时间戳。通过比较最早和最晚 Session 的创建时间差(约 30 秒),结合 Session 总数 (9941),可以估算出 OOM 发生前约 30 秒内,平均每秒创建了
9941 / 30 ≈ 331个 Session。这反映了当时 Tomcat 面临的请求压力。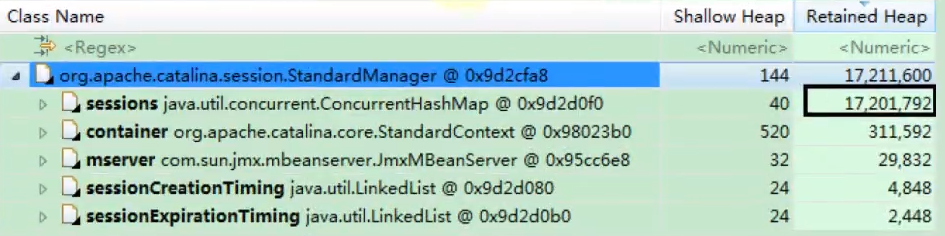
- 查看某个
结论:该 Tomcat OOM 的直接原因是短时间内创建了大量 HTTP Session,并且这些 Session 及其关联数据占用了过多的堆内存,超出了 JVM 的 -Xmx 限制。可能的解决方案包括:增加堆内存、缩短 Session 超时时间、优化 Session 中存储的数据量、或者排查是否所有请求都需要创建 Session。
MAT 凭借其强大的堆分析能力,特别是 Leak Suspects 报告、Histogram 和 Dominator Tree 视图,是诊断 Java 内存问题的必备工具。
# 5. 再谈内存问题:泄漏与溢出
理解内存泄漏 (Memory Leak) 和内存溢出 (OutOfMemoryError, OOM) 的区别与联系对于排查问题至关重要。
# 内存泄漏 (Memory Leak)
- 定义:指程序中某些不再被需要 (No Longer Needed) 的对象,由于仍然被可达的引用链(从 GC Roots 出发可以访问到)所持有,导致垃圾收集器 (GC) 无法回收它们占用的内存。
- 本质:对象逻辑上已废弃,但物理上仍被引用。
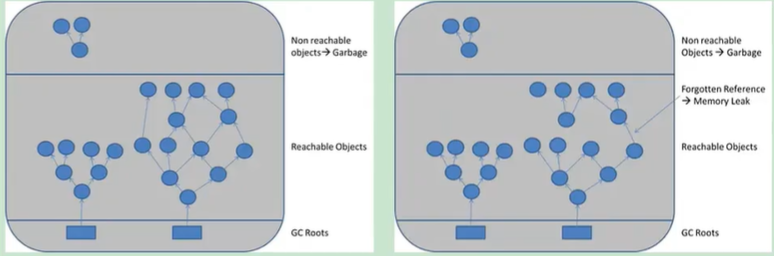
- 图中对象 Y 已不再被程序逻辑需要 (生命周期结束),但由于对象 X (生命周期可能更长) 仍然持有对 Y 的引用,GC 无法回收 Y。如果 X 还引用了其他短生命周期的对象 (A, B, C),并且这些对象又引用了其他对象 (a, b, c),那么这条引用链会导致大量无用对象滞留内存。
- 通俗比喻:“占着茅坑不拉屎”。内存被无效对象占据,无法被重新分配给新对象。
- 后果:内存泄漏会逐渐消耗可用内存,导致 GC 越来越频繁,单次 GC 时间变长,应用性能下降,最终可能引发内存溢出 (OOM)。
- 分类:
- 经常发生 (Frequent):泄漏代码被反复执行,每次泄漏一小块内存,累积效应明显。
- 偶然发生 (Occasional):仅在特定条件下触发。
- 一次性 (One-time):泄漏代码只执行一次,影响固定,相对不严重。
- 隐式泄漏 (Implicit Leak):严格来说不算泄漏,指对象生命周期过长,长时间占用内存但不释放,直到程序或某个长周期对象结束。如果执行时间极长,也可能耗尽内存。
# 内存溢出 (OutOfMemoryError, OOM)
- 定义:指程序在尝试申请新的内存空间时(例如创建新对象、扩展数组等),发现可用内存不足以满足请求,JVM 无法继续分配,从而抛出的严重错误 (
Error)。 - 原因:
- 内存泄漏累积:可用内存被泄漏的对象逐渐耗尽。
- 堆空间不足:JVM 配置的堆大小 (
-Xmx) 确实小于程序正常运行所需的内存。 - 创建超大对象:程序试图创建一个巨大的对象(如超大数组),单次分配就超过了剩余可用内存或单个内存区域的限制。
- 元空间/永久代溢出:加载过多的类或方法信息超出了 Metaspace 或 PermGen 的限制 (
-XX:MaxMetaspaceSize/-XX:MaxPermSize)。 - 栈溢出 (
StackOverflowError):通常由过深的递归调用或过大的线程栈帧导致,虽然不是堆内存溢出,但也属于内存相关错误。
- 通俗比喻:“坑位不够用了”。无论是有人占着茅坑不走(内存泄漏),还是同时来了太多人(内存需求过大),或者想建一个超大的坑位(创建大对象),最终导致没有可用的坑位。
- 关系:内存泄漏是导致内存溢出的常见原因之一,但并非唯一原因。内存溢出是内存不足的结果。
# 常见的 8 种内存泄漏情况
静态集合类 (Static Collections):
原因:如果
HashMap,ArrayList等集合被声明为static,它们的生命周期与 JVM 进程一致。如果持续向这些静态集合中添加短生命周期的对象引用,而没有及时移除,这些短生命周期的对象将因为被静态集合引用而无法被回收。示例:
public class StaticCollectionLeak { // 静态列表,生命周期与类相同 static List<Object> list = new ArrayList<>(); /** * 这个方法每次调用都会创建一个新对象并添加到静态列表中。 * 如果这个方法被频繁调用,list 会持续增长,其中的对象无法回收。 */ public void addToList() { Object obj = new Object(); // obj 是局部变量,方法结束时引用消失 list.add(obj); // 但 obj 被添加到了静态 list 中,被长生命周期对象引用 } // 需要在合适的时候手动从 list 中移除不再需要的对象,或者避免使用静态集合存储临时对象。 }1
2
3
4
5
6
7
8
9
10
11
12
13
14
单例模式 (Singleton Pattern):
原因:单例对象通常也是静态的,生命周期贯穿整个应用。如果单例对象持有对外部对象的引用(例如,传入的某个临时对象、回调接口等),并且没有在适当的时候释放这些引用,那么这些外部对象就无法被回收。
示例:
public class SingletonLeak { private static SingletonLeak instance = new SingletonLeak(); private Object externalObject; // 持有外部对象的引用 private SingletonLeak() {} public static SingletonLeak getInstance() { return instance; } /** * 如果这个方法持有了某个短生命周期的对象,并且没有后续置 null 操作, * 那么 externalObject 会一直引用它,导致泄漏。 */ public void holdObject(Object obj) { this.externalObject = obj; } // 需要在 externalObject 不再需要时,显式地将其置为 null: this.externalObject = null; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
内部类持有外部类引用 (Inner Class Holding Outer Class):
- 原因:非静态内部类(包括匿名内部类)会隐式地持有其外部类实例的引用。如果一个内部类实例的生命周期比其外部类实例长(例如,内部类实例被传递到其他地方并被长期持有),那么即使外部类实例本身已经不再被直接使用,它也无法被 GC 回收,因为它被其内部类实例引用着。
- 常见场景:回调、监听器、异步任务(如 Handler、Runnable、Thread)中使用了匿名内部类或非静态内部类访问了外部类的成员。
- 解决方法:
- 将内部类声明为静态 (static),静态内部类不持有外部类的引用。
- 在内部类中不直接引用外部类实例,可以通过构造函数传递必要的参数。
- 在外部类生命周期结束时(如 Activity 的
onDestroy),确保解除对内部类实例的引用(如果外部类持有内部类引用的话),或者内部类主动断开对外部资源的引用。
各种连接未关闭 (Connections Not Closed):
原因:数据库连接 (
Connection)、网络连接 (Socket)、文件/IO流 (InputStream,OutputStream,Reader,Writer) 等资源,在使用完毕后必须显式地调用close()方法来释放底层资源和相关联的 Java 对象。如果忘记关闭,这些连接对象(以及它们可能占用的系统资源)将一直存在,无法被 GC 回收,导致泄漏。最佳实践:始终在
finally块中关闭资源,或者使用 Java 7 及以上版本的try-with-resources语句自动管理资源关闭。示例 (try-finally):
Connection conn = null; Statement stmt = null; ResultSet rs = null; try { // 1. 获取连接 conn = DriverManager.getConnection("url", "user", "password"); // 2. 创建 Statement stmt = conn.createStatement(); // 3. 执行查询 rs = stmt.executeQuery("SELECT * FROM users"); // 4. 处理结果集... } catch (SQLException e) { e.printStackTrace(); } finally { // 5. 在 finally 块中按逆序关闭资源 if (rs != null) { try { rs.close(); } catch (SQLException e) { /* log or ignore */ } } if (stmt != null) { try { stmt.close(); } catch (SQLException e) { /* log or ignore */ } } if (conn != null) { try { conn.close(); } catch (SQLException e) { /* log or ignore */ } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25示例 (try-with-resources):更简洁、安全
try (Connection conn = DriverManager.getConnection("url", "user", "password"); Statement stmt = conn.createStatement(); ResultSet rs = stmt.executeQuery("SELECT * FROM users")) { // 处理结果集... // conn, stmt, rs 会在 try 块结束时自动关闭 (即使发生异常) } catch (SQLException e) { e.printStackTrace(); }1
2
3
4
5
6
7
8
变量作用域不合理 (Improper Variable Scope):
原因:一个对象的引用变量的作用域(生命周期)远远超过了它实际需要被使用的范围,导致对象存活时间过长。特别是成员变量,其生命周期与所属对象一致。
示例:
public class UnreasonableScope { private String msg; // 成员变量,生命周期与 UnreasonableScope 对象相同 public void processMessage() { readFromNet(); // 读取网络数据到 msg saveDB(); // 将 msg 保存到数据库 // 此时 msg 变量中的数据逻辑上已不再需要,但 msg 变量本身仍然存在, // 并且持有对 String 对象的引用,直到 UnreasonableScope 对象被回收。 // 如果 processMessage 被多次调用,msg 会被新数据覆盖,但旧的 String 对象可能暂时无法回收。 // 改进 1: 将 msg 定义为局部变量 // String localMsg = readFromNetAndReturn(); // saveDB(localMsg); // localMsg 生命周期仅限于此方法 // 改进 2: 使用后显式置 null (如果必须是成员变量) // this.msg = null; } private void readFromNet() { // 模拟从网络读取数据 this.msg = "Data from network " + System.currentTimeMillis(); } private void saveDB() { // 模拟保存到数据库 System.out.println("Saving to DB: " + this.msg); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28建议:尽量缩小变量的作用域,优先使用局部变量。如果必须使用成员变量存储临时数据,在不再需要时及时将其引用置为
null。
修改了放入 Set/Map 中对象的哈希码相关字段 (Changing Hash Code):
原因:当一个对象被放入
HashSet或作为HashMap的 Key 后,绝对不能修改那些参与计算hashCode()的字段。如果修改了,对象的hashCode()会变化,导致集合内部结构不一致。此时,即使使用该对象的引用去调用remove()或contains()方法,集合也可能因为哈希码对不上而找不到该对象,导致该对象永远无法从集合中移除,造成泄漏。为何 String 适合做 Key? 因为
String是不可变的,其hashCode()一旦计算就不会改变。自定义类作 Key/存入 Set:必须确保参与
hashCode()计算的字段是不可变的,或者在对象存入集合后不再修改这些字段。示例 1 (修改后 remove 失败):
import java.util.HashSet; import java.util.Objects; public class ChangeHashCodeLeak { public static void main(String[] args) { HashSet<Person> set = new HashSet<>(); Person p1 = new Person(1001, "AA"); Person p2 = new Person(1002, "BB"); set.add(p1); set.add(p2); System.out.println("Set after adding p1, p2: " + set); // [Person{id=1001, name='AA'}, Person{id=1002, name='BB'}] // 修改了 p1 的 name 字段,该字段参与了 hashCode 计算 p1.name = "CC"; // 此时 p1 的 hashCode 变了,HashSet 内部结构可能已不匹配 System.out.println("p1 hashCode changed to: " + p1.hashCode()); // 尝试移除 p1,HashSet 会根据 p1 当前的 hashCode (基于 "CC") 去找位置, // 但 p1 当初是根据 "AA" 的 hashCode 存进去的,位置不对,找不到! boolean removed = set.remove(p1); System.out.println("Removing p1 (name='CC') successful? " + removed); // 输出 false System.out.println("Set after trying to remove p1: " + set); // p1 依然在集合中,但 name 是 "CC" 了 // [Person{id=1001, name='CC'}, Person{id=1002, name='BB'}] - 内存泄漏 // 尝试添加一个新的 Person(1001, "CC") // HashSet 会根据新对象的 hashCode 查找,可能找不到与原 p1 冲突的位置,添加成功 set.add(new Person(1001, "CC")); System.out.println("Set after adding new Person(1001, 'CC'): " + set); // 集合中可能有重复逻辑的对象 // 尝试添加回 Person(1001, "AA") // HashSet 会根据 "AA" 的 hashCode 查找,可能会添加到另一个位置 set.add(new Person(1001, "AA")); System.out.println("Set after adding new Person(1001, 'AA'): " + set); } } class Person { int id; String name; // name 参与 hashCode 计算 public Person(int id, String name) { this.id = id; this.name = name; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Person person = (Person) o; return id == person.id && Objects.equals(name, person.name); } @Override public int hashCode() { // hashCode 基于 id 和 name return Objects.hash(id, name); } @Override public String toString() { return "Person{" + "id=" + id + ", name='" + name + '\'' + '}'; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62示例 2 (Point 类):
import java.util.HashSet; import java.util.Objects; public class ChangeHashCodeLeak2 { public static void main(String[] args) { HashSet<Point> hs = new HashSet<>(); Point cc = new Point(); cc.setX(10); // 初始 hashCode (假设基于 x=10) hs.add(cc); System.out.println("Added Point with x=10, hashCode=" + cc.hashCode()); // 修改了参与 hashCode 计算的字段 x cc.setX(20); // hashCode 变化了 System.out.println("Changed Point x to 20, hashCode=" + cc.hashCode()); // 尝试移除 cc,会根据 x=20 的 hashCode 查找,找不到原位置 boolean removed = hs.remove(cc); System.out.println("hs.remove(cc where x=20) = " + removed); // 输出 false // 再次添加 cc (此时 x=20) // HashSet 会根据 x=20 的 hashCode 查找,发现没有这个 hashCode 的对象 (或者不在那个位置) // 于是将这个 cc (虽然是同一个对象引用,但状态变了) 作为一个新元素添加 hs.add(cc); System.out.println("hs.size = " + hs.size()); // 输出 size = 2 System.out.println(hs); // 输出 [Point{x=20}, Point{x=20}] - 逻辑上可能不希望有两个x=20的点,且第一个x=10的点无法移除 } } class Point { int x; // x 参与 hashCode 计算 public int getX() { return x; } public void setX(int x) { this.x = x; } @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Point point = (Point) o; return x == point.x; } @Override public int hashCode() { // hashCode 基于 x return Objects.hash(x); } @Override public String toString() { return "Point{" + "x=" + x + '}'; } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
缓存泄漏 (Cache Leak):
原因:将对象引用放入缓存(如
HashMap)中后,如果忘记在对象不再需要时从缓存中移除,这些对象就会因为被缓存引用而无法回收。特别是当缓存的生命周期很长时,问题会更严重。示例:程序启动时加载大量数据到静态
HashMap缓存中,如果这些数据后续很少被访问或永不失效,就会一直占用内存。解决方案:
- 使用带有淘汰策略的缓存实现(如 LRU - 最近最少使用)。
- 使用弱引用 (Weak References) 或软引用 (Soft References) 来存储缓存对象,特别是使用
WeakHashMap。WeakHashMap的特点是:如果一个 Key 对象不再有任何强引用指向它(除了来自WeakHashMap内部的弱引用),那么在下一次 GC 发生时,这个 Key 及其对应的 Value 就可能会被自动从 Map 中移除。这非常适合做缓存,可以自动清理不再被外部使用的缓存项。
WeakHashMap示例:import java.util.HashMap; import java.util.Map; import java.util.WeakHashMap; import java.util.concurrent.TimeUnit; public class CacheLeakExample { // 使用 WeakHashMap 作为缓存 static Map<String, String> weakCache = new WeakHashMap<>(); // 使用普通的 HashMap 作为对比 static Map<String, String> strongCache = new HashMap<>(); public static void main(String[] args) throws InterruptedException { // 创建 Key 对象,并放入缓存 String key1 = new String("weakKey"); // 使用 new String 确保是新对象 String key2 = new String("strongKey"); weakCache.put(key1, "Weak Cache Data"); strongCache.put(key2, "Strong Cache Data"); System.out.println("Before GC:"); System.out.println("WeakHashMap: " + weakCache); System.out.println("HashMap: " + strongCache); // 移除外部对 Key 的强引用 key1 = null; key2 = null; System.out.println("\nRemoved external strong references to keys."); // 触发 GC (不保证立即执行,但增加可能性) System.out.println("Triggering GC..."); System.gc(); TimeUnit.SECONDS.sleep(1); // 等待 GC System.out.println("\nAfter GC:"); // WeakHashMap 中的 key1 因为没有其他强引用,很可能被回收,导致 Entry 被移除 System.out.println("WeakHashMap: " + weakCache); // HashMap 中的 key2 虽然外部引用没了,但 HashMap 内部仍然是强引用,不会被回收 System.out.println("HashMap: " + strongCache); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40预期输出:GC 后,
WeakHashMap很可能变为空,而HashMap保持不变。
监听器和其他回调 (Listeners and Callbacks):
- 原因:在事件驱动模型中,经常会将监听器(Listener)或回调(Callback)对象注册到事件源(Source)上。如果在监听器不再需要时(例如,UI 界面关闭),没有从事件源那里显式地注销 (unregister/remove) 监听器,那么事件源会一直持有对监听器的引用,导致监听器对象(以及它可能引用的其他对象)无法被回收。
- 常见场景:Android 开发中的 Context 泄漏(Activity 作为 Listener 注册到某个生命周期更长的对象上,Activity 销毁时未注销)、各种事件总线、观察者模式实现。
- 解决方案:
- 在适当的生命周期结束点(如
onDestroy(),onStop())务必反注册/移除监听器。 - 考虑使用弱引用来持有监听器对象,但这会增加实现的复杂性(事件源需要处理弱引用可能变为 null 的情况)。
- 使用专门管理生命周期的库(如 Android Jetpack Lifecycle)。
- 在适当的生命周期结束点(如
# 栈内存泄漏案例分析 (Stack.java)
这个例子演示了一个自定义栈实现中可能存在的过期引用 (Obsolete Reference) 问题,这也是一种内存泄漏。
import java.util.Arrays;
import java.util.EmptyStackException;
/**
* 一个简单的对象栈实现,演示过期引用导致的内存泄漏问题。
*/
public class StackLeak {
private Object[] elements;
private int size = 0;
private static final int DEFAULT_INITIAL_CAPACITY = 16;
public StackLeak() {
elements = new Object[DEFAULT_INITIAL_CAPACITY];
}
/**
* 入栈操作。
* @param e 要入栈的对象。
*/
public void push(Object e) {
ensureCapacity();
elements[size++] = e;
}
/**
* 出栈操作 - 存在内存泄漏的版本。
* @return 栈顶对象。
* @throws EmptyStackException 如果栈为空。
*/
/* // 错误的版本
public Object pop() {
if (size == 0)
throw new EmptyStackException();
// 直接返回 elements[--size],但并没有将原位置的引用置 null
// elements 数组仍然持有对这个已弹出对象的引用
return elements[--size];
}
*/
/**
* 出栈操作 - 修复了内存泄漏的版本。
* @return 栈顶对象。
* @throws EmptyStackException 如果栈为空。
*/
public Object pop() { // 正确的版本
if (size == 0)
throw new EmptyStackException();
// 先将 size 减 1,获取栈顶元素
Object result = elements[--size];
// 将数组中对应位置的引用置为 null,断开对弹出对象的引用
elements[size] = null; // 清除过期引用
return result;
}
/**
* 确保数组容量足够,如果不够则扩容。
*/
private void ensureCapacity() {
if (elements.length == size)
elements = Arrays.copyOf(elements, 2 * size + 1);
}
public static void main(String[] args) {
StackLeak stack = new StackLeak();
// 入栈 20 个对象
for(int i = 0; i < 20; i++) {
stack.push(new byte[1024 * 1024]); // 假设每个对象 1MB
}
System.out.println("Stack size after push: " + stack.size); // 输出 20
// 出栈 10 个对象
for(int i = 0; i < 10; i++) {
stack.pop();
}
System.out.println("Stack size after pop: " + stack.size); // 输出 10
// 如果使用的是错误的 pop 版本:
// 即使弹出了 10 个对象,stack.elements 数组的索引 10 到 19 的位置
// 仍然持有对那 10 个 1MB byte[] 对象的引用。
// 这些对象逻辑上已不在栈中,但 GC 无法回收它们,造成 10MB 内存泄漏。
// 如果使用的是正确的 pop 版本:
// 每次 pop 时,对应位置的引用被置 null,GC 可以回收弹出的对象。
System.out.println("Check elements array after correct pop (conceptual):");
// for(int i = 0; i < stack.elements.length; i++) {
// System.out.println("elements[" + i + "] = " + stack.elements[i]);
// }
// 预期:索引 0-9 有对象引用,索引 10-19 为 null。
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
问题分析:
- 错误的
pop方法仅仅是将size减 1,并返回了elements[size](减 1 之前的size位置)的对象。 - 但是,
elements数组内部,索引为size(减 1 之后) 的那个位置仍然持有对刚刚弹出的对象的引用。 - 只要
StackLeak对象本身存活,elements数组就存活,那么数组中持有的这些“已弹出”对象的引用就一直存在。 - 这些引用被称为过期引用 (Obsolete Reference),它们指向逻辑上已经不再使用但物理上仍然被引用的对象,导致内存泄漏。
图示:
- 栈增长后:
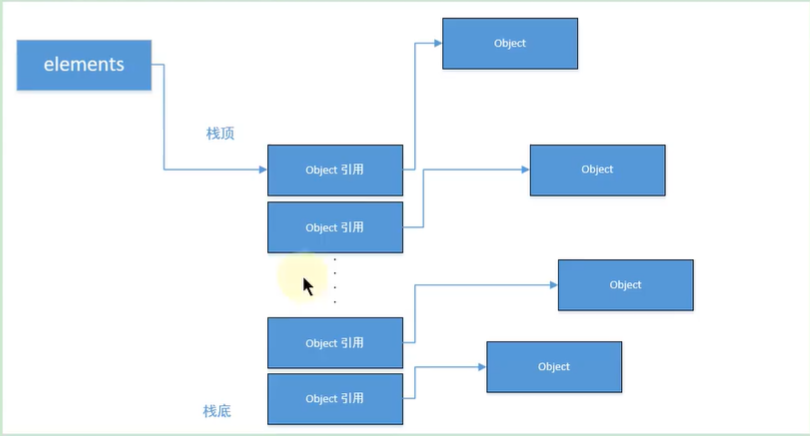
- 错误
pop后: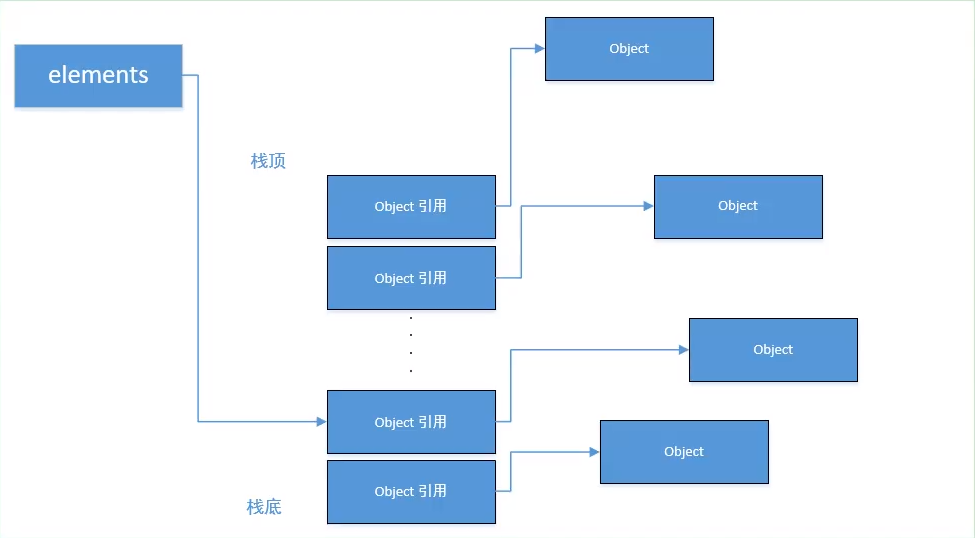 图中灰色部分代表已弹出但仍被数组引用的对象(内存泄漏)。
图中灰色部分代表已弹出但仍被数组引用的对象(内存泄漏)。
解决方法:
在 pop 操作取出对象引用后,必须手动将数组中对应位置的引用设置为 null,断开这个过期引用。
public Object pop() {
if (size == 0)
throw new EmptyStackException();
Object result = elements[--size];
elements[size] = null; // 清除过期引用,允许 GC 回收 result 对象
return result;
}
2
3
4
5
6
7
修复后的 pop 操作示意图: 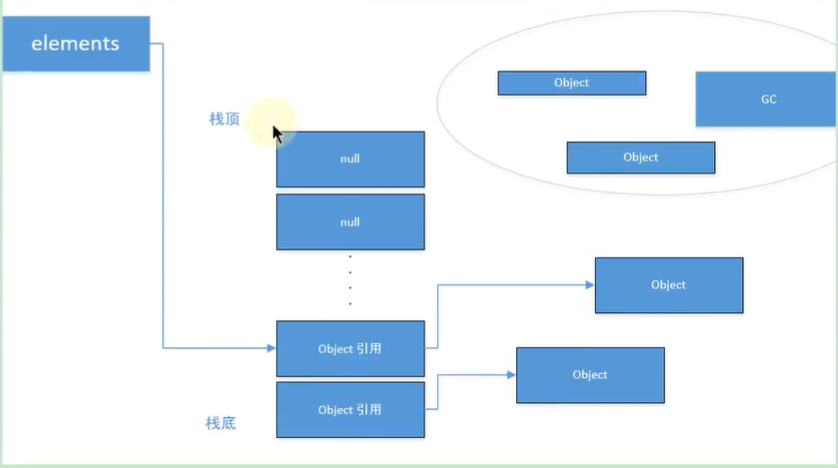
总结:对于集合类、缓存等自己管理对象引用的数据结构,需要特别注意及时清理不再需要的对象的引用,避免过期引用导致的内存泄漏。
# 6. 使用 OQL 语言查询对象信息
MAT 提供了一种强大的对象查询语言 (Object Query Language, OQL),它允许用户使用类似 SQL 的语法在加载的 Heap Dump 中进行复杂的对象查找和筛选。
基本语法结构:
SELECT <select_expression>
FROM <class_name_or_pattern | object_address_or_set> [[AS] <alias>]
[WHERE <filter_expression>]
2
3
SELECT 子句:
- 指定要显示的结果列。
- 可以使用
*选择对象的所有属性。 - 可以使用
OBJECTS关键字,将结果项作为可检查的对象列表返回,而不是简单的文本输出。 - 可以使用
AS RETAINED SET获取结果对象的保留集大小。 - 可以使用
DISTINCT去除结果集中的重复对象。 - 可以访问对象的属性,包括特殊属性(以
@开头)。
常用特殊属性:
@objectid: 对象的 ID。@objectAddress: 对象的内存地址。@shallowHeapSize: 对象的浅堆大小。@retainedHeapSize: 对象的深堆大小。@class: 对象所属的 Class 对象。@length: (仅用于数组) 数组的长度。@GCRootReason: (仅用于 GC Roots) GC Root 的类型。
示例:
SELECT * FROM java.util.Vector v- 查找所有
java.util.Vector类的实例,并显示它们的属性。
- 查找所有
SELECT OBJECTS v.elementData FROM java.util.Vector v- 查找所有
Vector实例,并返回它们内部elementData数组的对象列表。
- 查找所有
SELECT OBJECTS s.value FROM java.lang.String s- 查找所有
String实例,并返回它们内部value(char[]) 数组的对象列表。
- 查找所有
SELECT AS RETAINED SET * FROM cn.kbt.mat.Student- 查找所有
cn.kbt.mat.Student实例,并计算每个实例的保留集大小。
- 查找所有
SELECT DISTINCT OBJECTS classof(s) FROM java.lang.String s- 查找所有
String实例,获取它们对应的Class对象,并去除重复,最终只返回java.lang.String这个 Class 对象。(classof()是 OQL 内置函数)。
- 查找所有
FROM 子句:
- 指定查询的源(从哪里查找)。
- 可以是一个具体的类名 (
java.lang.String)。 - 可以使用正则表达式匹配类名 (
"cn\.kbt\..*"查找cn.kbt包下的所有类)。 - 可以是一个对象的内存地址 (
0x37a0b4d)。 - 可以使用
INSTANCEOF关键字查找某个类及其所有子类的实例 (INSTANCEOF java.util.Vector)。 - 可以是一个对象集合(例如,另一个 OQL 查询的结果)。
WHERE 子句:
- 指定过滤条件,只有满足条件的对象才会被返回。
- 语法类似 SQL 的 WHERE 子句,支持
AND,OR,NOT。 - 支持比较运算符 (
=,!=,>,<,>=,<=)。 - 支持
LIKE操作符(参数是正则表达式)。 - 支持
instanceof操作符。 - 可以访问对象的属性(包括
@特殊属性)。
示例:
SELECT * FROM char[] s WHERE s.@length > 10- 查找所有长度大于 10 的
char数组。
- 查找所有长度大于 10 的
SELECT * FROM java.lang.String s WHERE toString(s) LIKE ".*java.*"- 查找所有内容包含 "java" 子字符串的
String对象。(注意:toString(s)可能比直接访问s.value效率低)。 - 更高效的方式可能是:
SELECT * FROM java.lang.String s WHERE s.value != null AND s.value.@length > 0 AND toString(s.value).contains("java")(假设toString对 char[] 有效) 或通过更复杂的 OQL 操作value数组。
- 查找所有内容包含 "java" 子字符串的
SELECT * FROM java.lang.String s WHERE s.value != null- 查找所有内部
value数组不为 null 的String对象。
- 查找所有内部
SELECT * FROM java.util.Vector v WHERE v.elementData.@length > 15 AND v.@retainedHeapSize > 1000- 查找所有内部数组长度大于 15 且深堆大小超过 1000 字节的
Vector对象。
- 查找所有内部数组长度大于 15 且深堆大小超过 1000 字节的
内置对象与方法:
OQL 提供了一些内置对象和方法方便查询:
- 访问对象属性:
[ <alias>. ] <field> . <field>SELECT toString(f.path.value) FROM java.io.File f: 访问File对象的path属性(假设是String类型),再访问path的value属性(char[]),并转换为字符串。
- 访问特殊属性(见上文
@属性)。 - 内置函数:
toString(),classof(),reachables()(查找可达对象) 等。
OQL 是 MAT 中非常强大的功能,熟练使用 OQL 可以极大地提高分析 Heap Dump 的效率。
# 7. JProfiler:商业级 Java 性能分析瑞士军刀
官网地址:
https://www.ej-technologies.com/products/jprofiler/overview.html
JProfiler 是由 ej-technologies 公司开发的一款商业 (需要付费) 的 Java 应用程序性能诊断工具。它以其功能全面、易于使用和强大的分析能力而闻名,是许多专业开发团队的选择。
核心特点:
- 使用方便,界面友好:提供了直观的图形界面和预设的分析模板。
- 低性能影响 (可配置):提供 Sampling (抽样) 和 Instrumentation (插桩) 两种数据采集方式,Sampling 对应用影响较小。
- 强大的分析能力:在 CPU、线程、内存分析方面尤为突出。
- 广泛的子系统支持:支持对 JDBC (包括 SQL 语句分析)、NoSQL、JSP/Servlet、Socket、RMI、Web Services 等进行专门分析。
- 多种分析模式:支持在线实时分析 (Live Profiling) 和离线分析 (Offline Profiling,基于快照)。
- 支持本地与远程监控:可以监控本地 JVM,也可以通过 Agent 连接到远程 JVM。
- 跨平台:支持 Windows, macOS, Linux 等多种操作系统。
 图:JProfiler 界面概览
图:JProfiler 界面概览
主要功能模块:
方法调用分析 (CPU Views):
- Call Tree (调用树):自顶向下展示方法的调用关系和累积耗时。
- Hot Spots (热点):直接列出消耗 CPU 时间最多的方法。
- Call Graph (调用图):可视化方法间的调用关系。
- Method Statistics (方法统计):详细列出每个方法的调用次数、平均/总执行时间等。
- 帮助定位 CPU 性能瓶颈。
内存分配分析 (Live Memory & Heap Walker):
- All Objects / Recorded Objects: 查看堆上对象的实例数、大小、分配位置(调用栈)。
- Allocation Call Tree / Hot Spots: 分析哪些代码路径或方法创建了最多的对象或占用了最多的内存。
- Class Tracker: 跟踪特定类的实例数量随时间的变化。
- Heap Walker: 强大的堆转储快照分析器,功能类似 MAT,可以查看对象、引用链、计算 Retained Size、执行 OQL 等,用于查找内存泄漏。
线程和锁分析 (Threads & Monitors/Locks):
- Thread History / Monitor: 实时查看线程状态、活动时间线、当前执行的方法。
- Thread Dumps: 获取线程快照。
- Locking History / Graph: 分析锁竞争、等待情况、检测死锁。
高级子系统分析 (Databases, JEE & Probes):
- JDBC/JPA/Hibernate: 分析数据库调用,找出慢 SQL、执行次数过多的 SQL。
- Servlet/JSP: 按 URL 分析请求处理时间。
- Socket/File I/O: 分析网络和文件读写操作。
- Probes (探针): 提供对常用框架和技术的内置支持,进行更高级别的语义分析。
数据采集方式:
JProfiler 主要针对方法调用提供两种采集方式:
- Instrumentation (插桩/重构模式):
- 在类加载时,JProfiler 将分析代码(字节码)注入到需要分析的类中。
- 优点:功能最全面,可以获取精确的方法调用次数、执行时间、内存分配细节等。调用栈信息准确。
- 缺点:对应用性能有较大影响,特别是分析大量类时,CPU 开销可能很高。通常需要配合过滤器 (Filter) 精确指定要插桩的类或包,以减少开销。
- Sampling (抽样):
- JProfiler 定期(例如每 5ms)获取每个线程当前的方法调用栈。通过统计栈顶方法出现的频率来估算方法的执行时间。
- 优点:对应用性能影响非常小,CPU 开销低,适用于生产环境或对性能影响敏感的场景。
- 缺点:无法提供精确的方法调用次数和绝对执行时间,对于执行时间非常短的方法可能采样不到。数据是统计估算值。
JProfiler 界面示例:
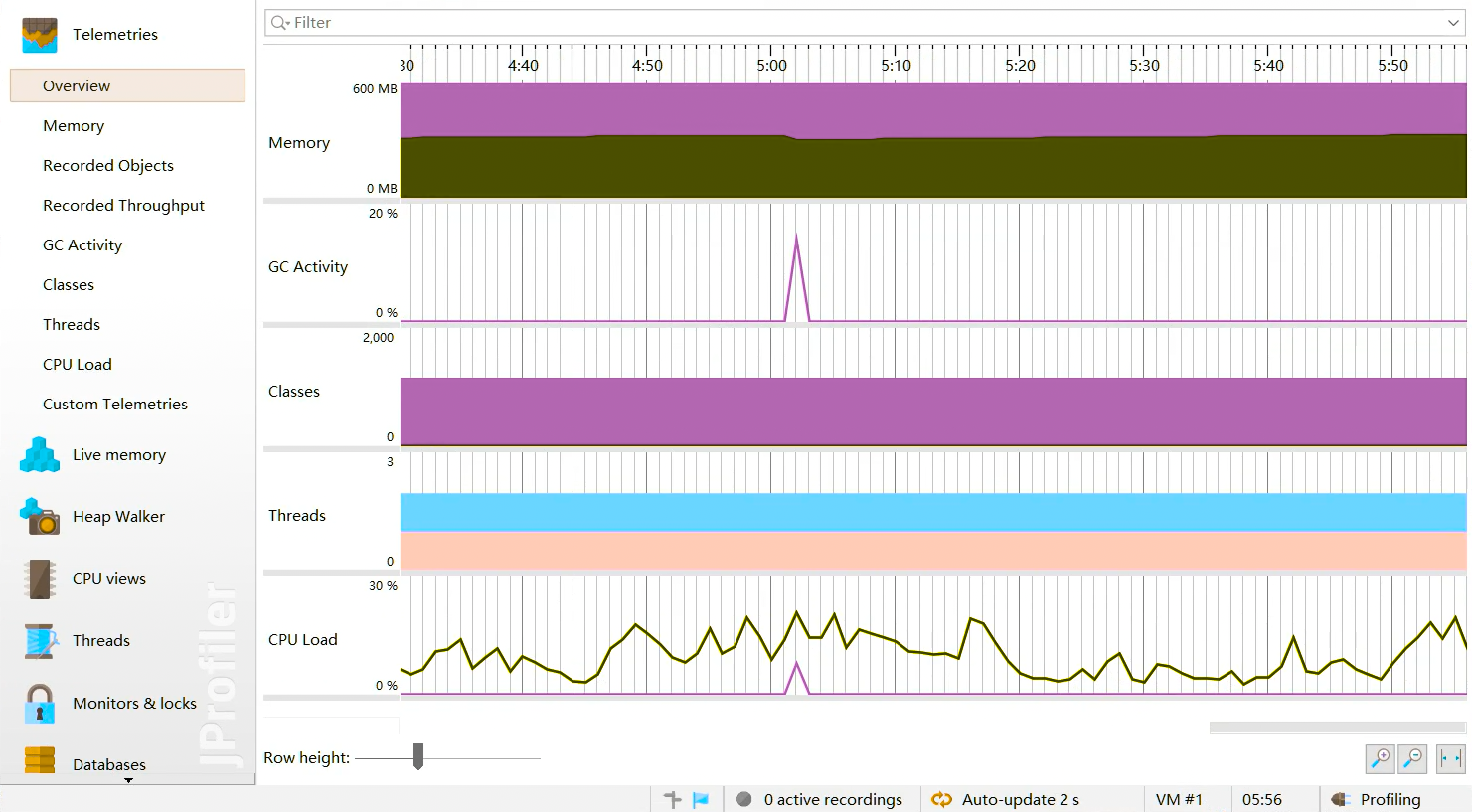
遥感监测 (Telemetries):提供 JVM 整体运行状态的概览图表,类似 JConsole 和 VisualVM 的 Monitor 视图。
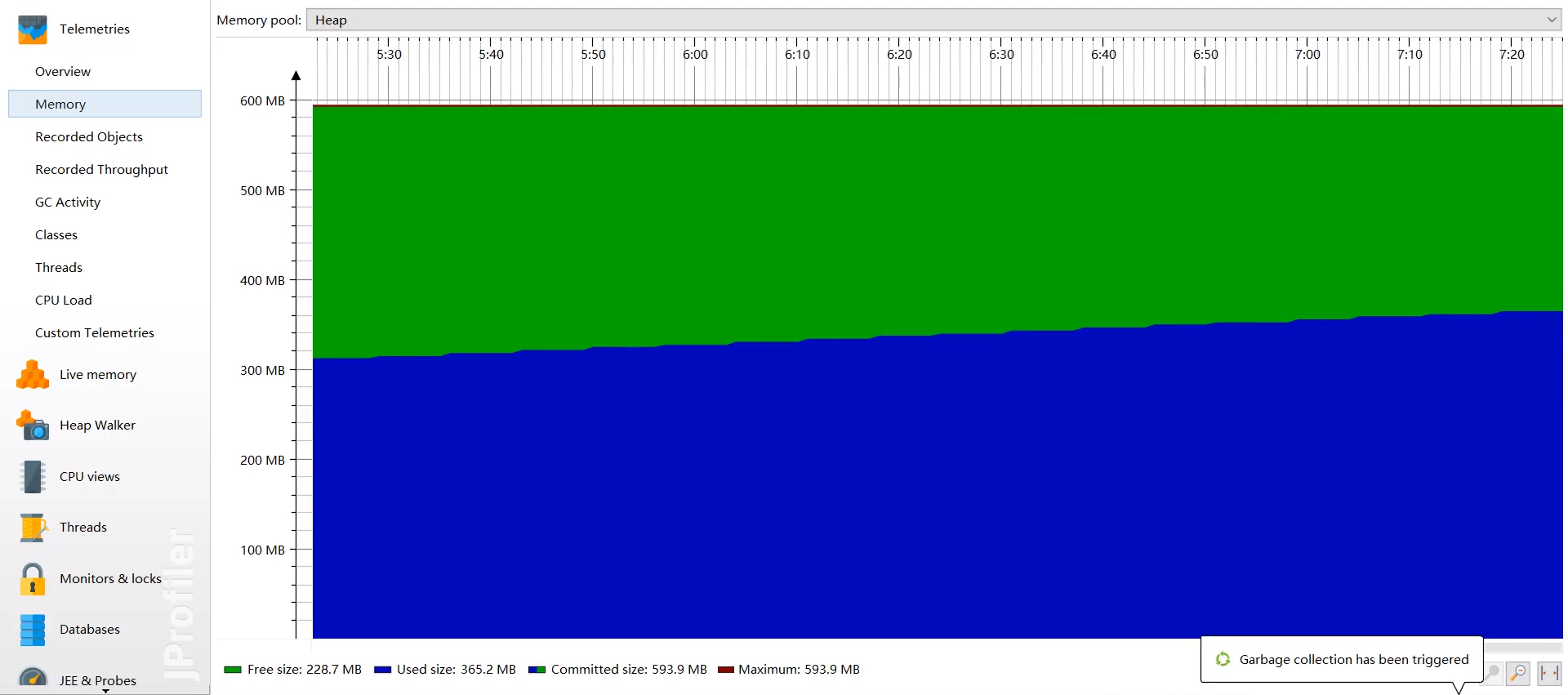
- 内存使用曲线:
- GC 活动:
- 类加载:
- 线程状态:
- CPU 负载:
- 内存使用曲线:
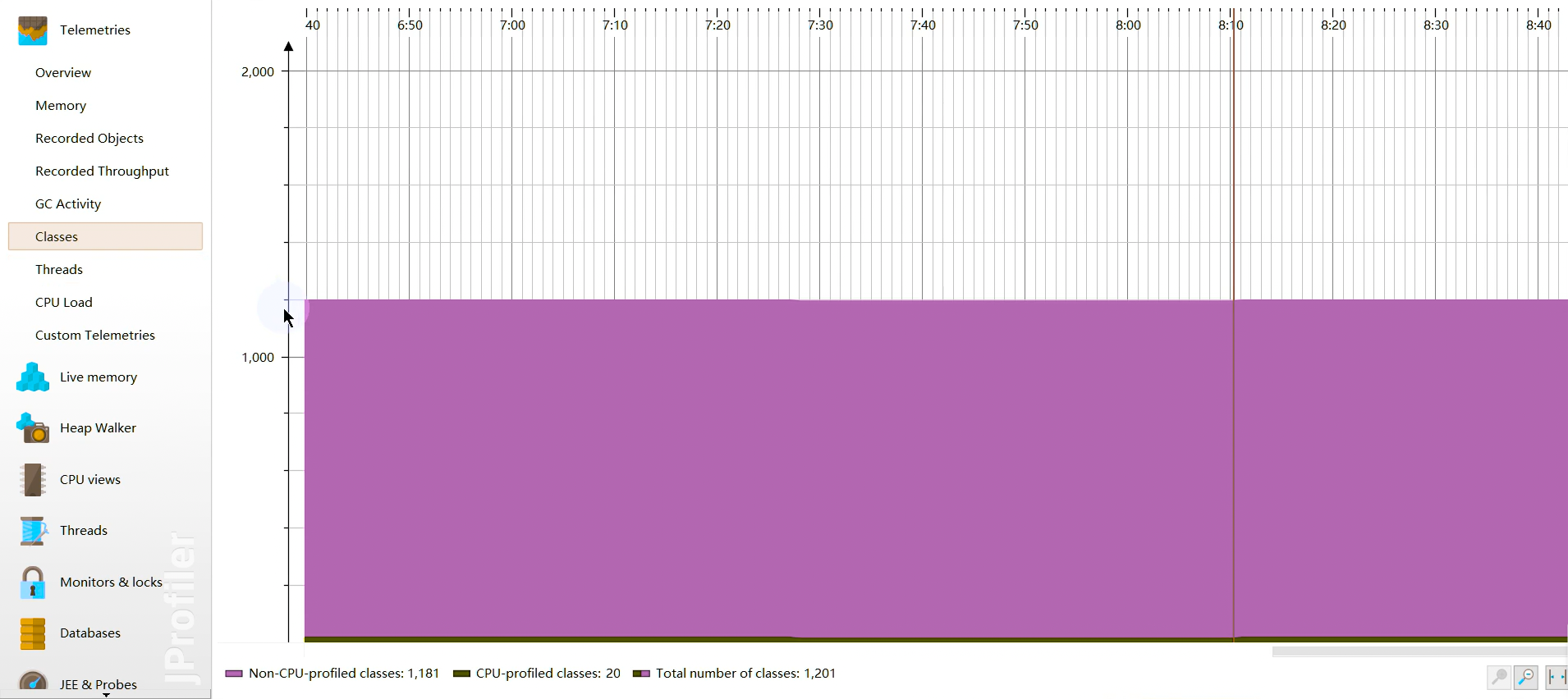
内存视图 (Live Memory):实时分析内存分配。
- All Objects (所有对象视图):

- Allocation Call Tree (分配调用树):
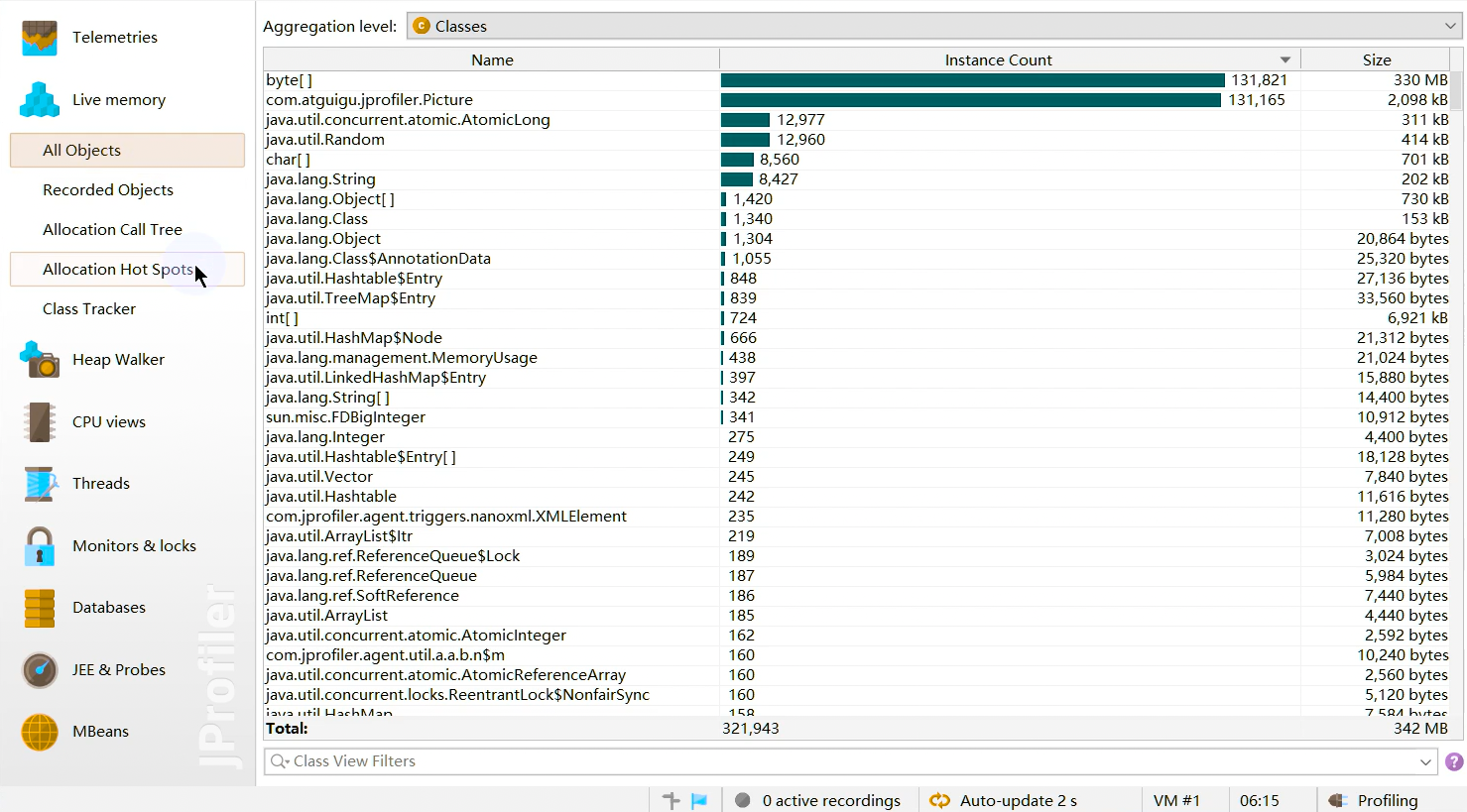
- Allocation Hot Spots (分配热点):
- All Objects (所有对象视图):
堆遍历 (Heap Walker):离线分析 Heap Dump 文件。
- Classes (类视图):
- References (引用视图):查看对象的传入传出引用、分析 GC Roots 路径。
- Classes (类视图):
CPU 视图 (CPU Views):分析 CPU 耗时。
- Call Tree (调用树):
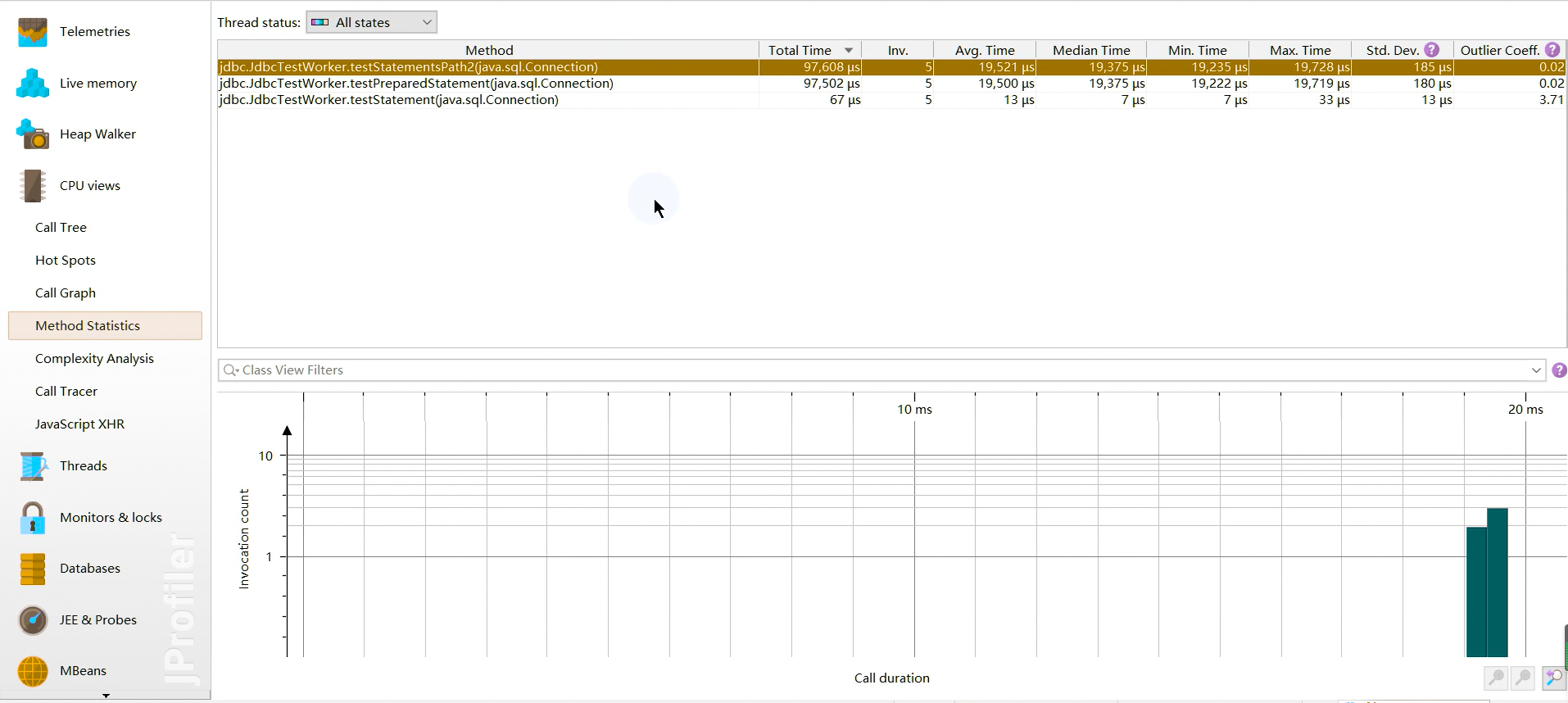
- Hot Spots (热点):
- Call Tree (调用树):
线程视图 (Threads):分析线程活动和状态。
- Thread History (线程历史时间线):
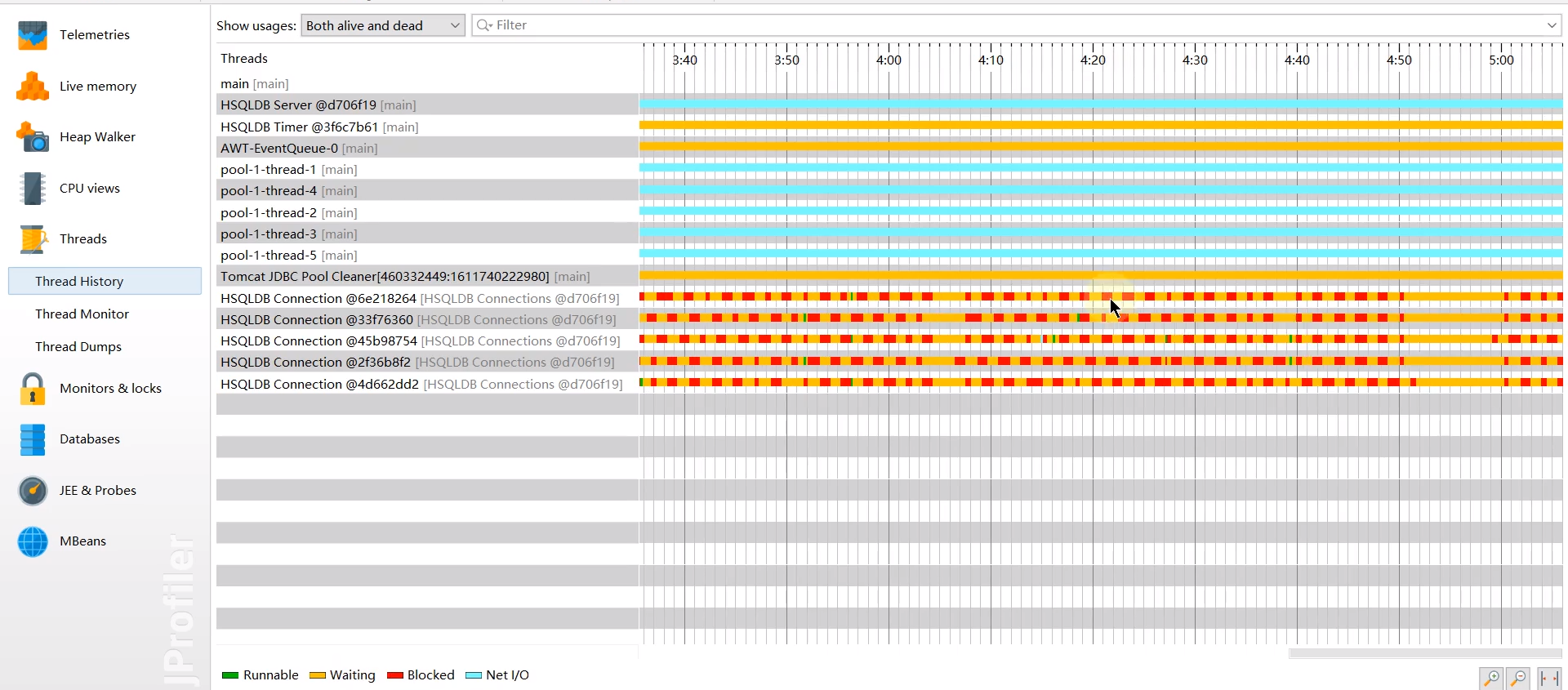
- Thread Monitor (线程监控列表):
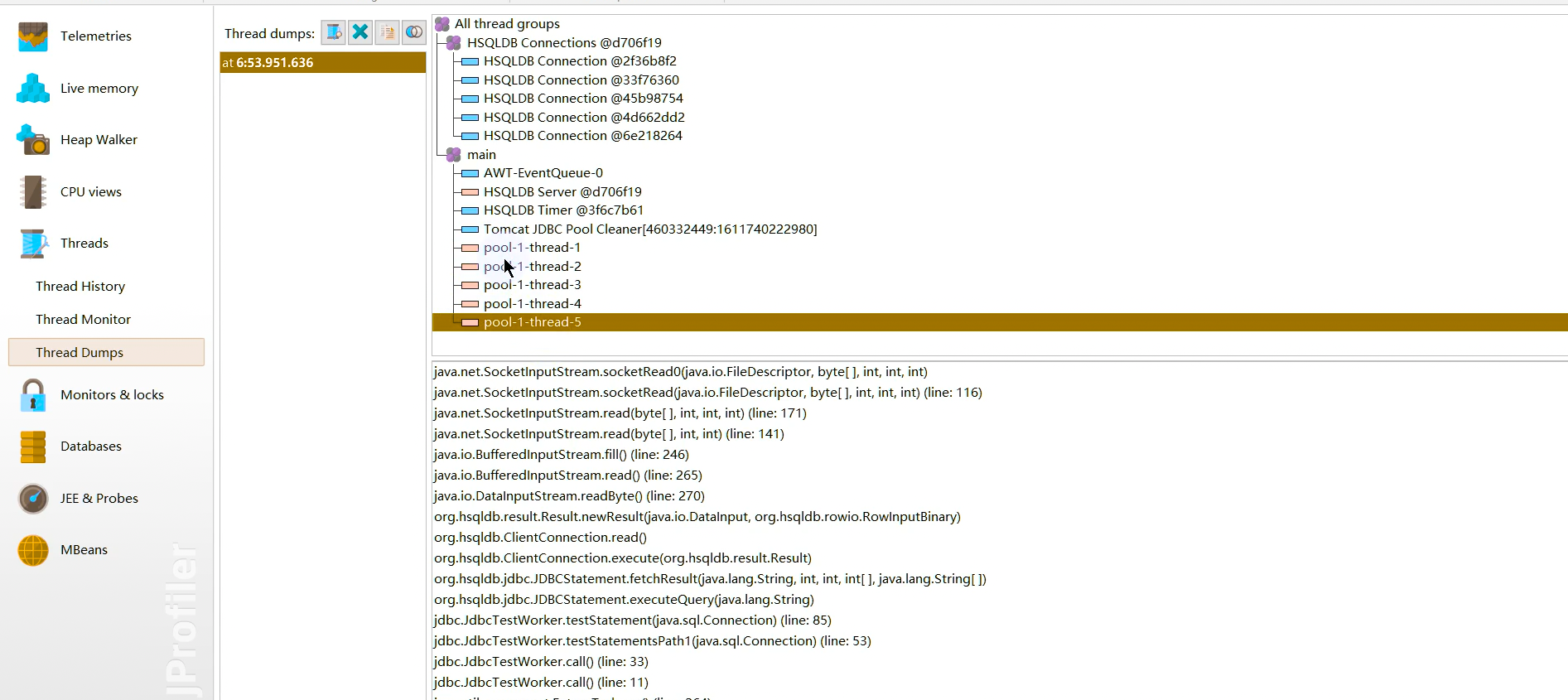
- Thread History (线程历史时间线):
监控和锁 (Monitors & Locks):分析锁竞争和死锁。
JProfiler 简单案例:
案例 1:模拟频繁创建对象 (
JProfilerTest.java)import java.util.ArrayList; import java.util.concurrent.TimeUnit; /** * 模拟在循环中不断创建大量临时对象的场景。 * 用于观察 JProfiler 中的内存分配和 GC 活动。 */ public class JProfilerTest { public static void main(String[] args) { while (true) { // 无限循环 ArrayList<Data> list = new ArrayList<>(); // 在循环内部创建列表 for (int i = 0; i < 500; i++) { Data data = new Data(); // 创建 Data 对象 list.add(data); } // list 和内部的 Data 对象在循环结束后理论上应可被回收 try { TimeUnit.MILLISECONDS.sleep(500); // 短暂休眠 } catch (InterruptedException e) { e.printStackTrace(); } } } } class Data { private int size = 10; // 每个 Data 对象包含一个 1MB 的字节数组 private byte[] buffer = new byte[1024 * 1024]; private String info = "hello,kele"; }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31JProfiler 分析结果:
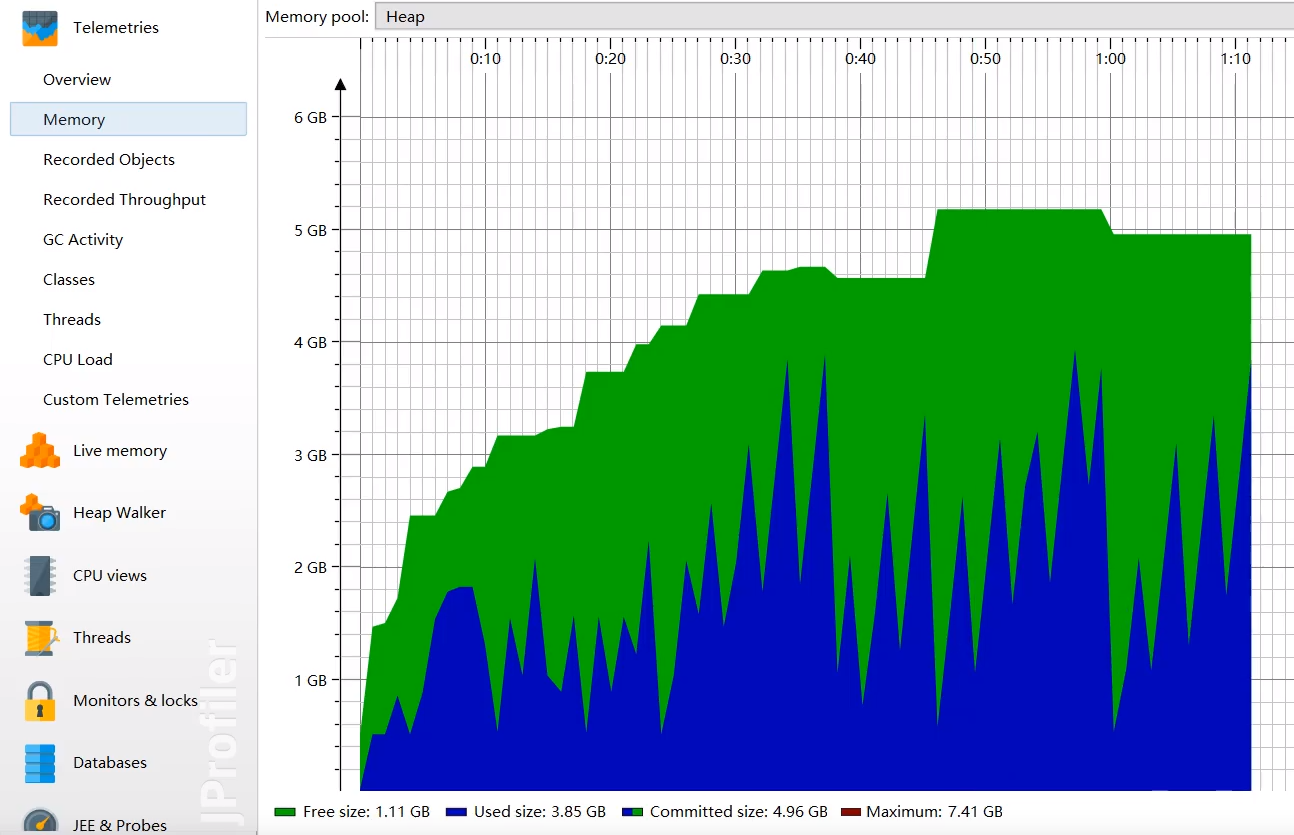
- 遥感监测 (Telemetries) 中的内存视图会显示典型的锯齿状图形,表示内存不断分配(上升),然后被 Young GC 回收(下降)。
- GC 活动视图会显示频繁的 Young GC。
- Live Memory 视图的 Allocation Hot Spots 可以看到
Data对象的构造函数 (<init>) 是主要的内存分配来源。
- 遥感监测 (Telemetries) 中的内存视图会显示典型的锯齿状图形,表示内存不断分配(上升),然后被 Young GC 回收(下降)。
案例 2:模拟静态集合内存泄漏 (
MemoryLeak.java)import java.util.ArrayList; import java.util.concurrent.TimeUnit; /** * 模拟使用静态集合导致内存泄漏的场景。 */ public class MemoryLeak { public static void main(String[] args) { while (true) { ArrayList<Bean> beanList = new ArrayList<>(); for (int i = 0; i < 500; i++) { Bean data = new Bean(); // 将一个 10KB 的 byte 数组添加到 Bean 的静态 list 中 data.list.add(new byte[1024 * 10]); beanList.add(data); // beanList 是局部变量,会被回收 } // beanList 及其包含的 Bean 对象引用在循环结束后消失, // 但 Bean.list 是静态的,它持有的 byte[] 数组无法被回收。 try { TimeUnit.MILLISECONDS.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } } } class Bean { int size = 10; String info = "hello,kele"; // !!!问题所在:静态列表,生命周期与类相同!!! static ArrayList<byte[]> list = new ArrayList<>(); // 正确的写法应该是实例变量: // ArrayList<byte[]> list = new ArrayList<>(); }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35JProfiler 分析结果:
- 内存视图会显示堆内存持续增长,即使发生 GC 也无法完全回收,因为
Bean.list持有的byte[]越来越多。
- Heap Walker 分析会显示
Bean.list(ArrayList) 对象及其内部的elementData(Object[]) 占用了大量的 Retained Heap,并且持有大量byte[]实例。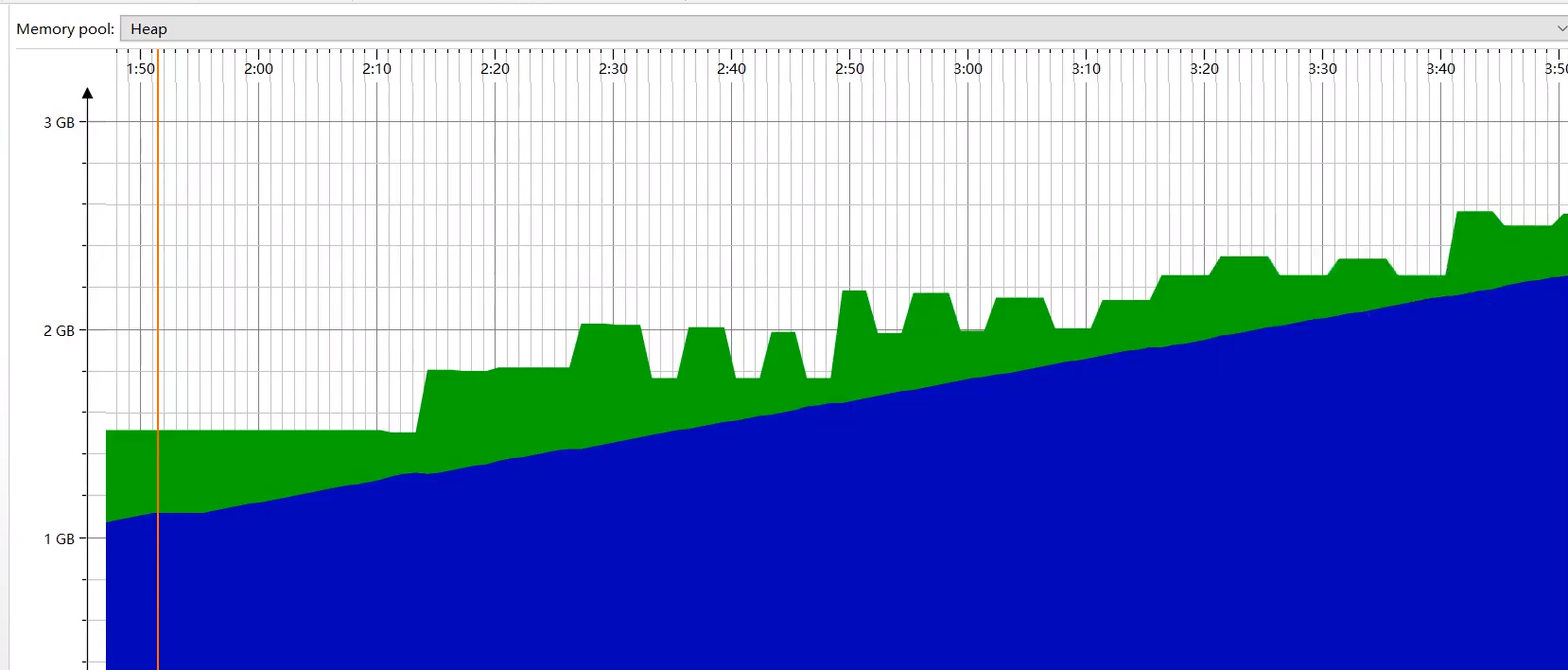
- 内存视图会显示堆内存持续增长,即使发生 GC 也无法完全回收,因为
JProfiler 是一款非常专业的工具,虽然需要付费和一定的学习成本,但其强大的功能对于深入分析和解决复杂的 Java 性能问题非常有价值。
# 8. Arthas:阿里开源的 Java 诊断神器
官方网站与文档:
https://arthas.aliyun.com/doc/
Arthas (阿尔萨斯) 是阿里巴巴开源的一款 Java 在线诊断工具,旨在解决线上 Java 应用的常见问题,尤其是在不方便重启或添加日志的情况下。它深受开发者喜爱,被誉为“Java 诊断神器”。
解决痛点:
- 无需远程连接配置:Arthas 直接 attach 到目标 Java 进程,无需预先在目标 JVM 中配置 JMX 或其他监控参数。
- 无需重启应用:可以在应用运行时动态地进行诊断和分析。
- 网络隔离环境友好:由于是 attach 到本地进程,不受网络隔离限制。
- 动态代码跟踪与修改:可以在不修改源码、不重新部署的情况下,观察方法调用、参数、返回值,甚至热更新代码。
- 实时 JVM 状态监控:提供丰富的命令实时查看 JVM 内部状态。
- 开源免费。
核心能力:
- 类加载问题排查:查看类从哪个 Jar 包加载,诊断
ClassNotFoundException,NoClassDefFoundError等。 - 代码执行路径确认:验证某段代码是否被执行,调用栈是怎样的。
- 在线 Debug 模拟:观察方法的入参、返回值、内部变量、抛出的异常。
- 全局运行状况监控:提供 Dashboard 查看系统实时状态(线程、内存、GC、CPU 等)。
- 性能热点定位:快速找出消耗 CPU 最多的线程和方法,支持生成火焰图。
安装与启动:
Arthas 本质上是一个 Java Agent。
下载
arthas-boot.jar:# 从官方或镜像下载启动包 wget https://arthas.aliyun.com/arthas-boot.jar # 或者使用国内镜像 # wget https://arthas.gitee.io/arthas-boot.jar1
2
3
4启动并 Attach:
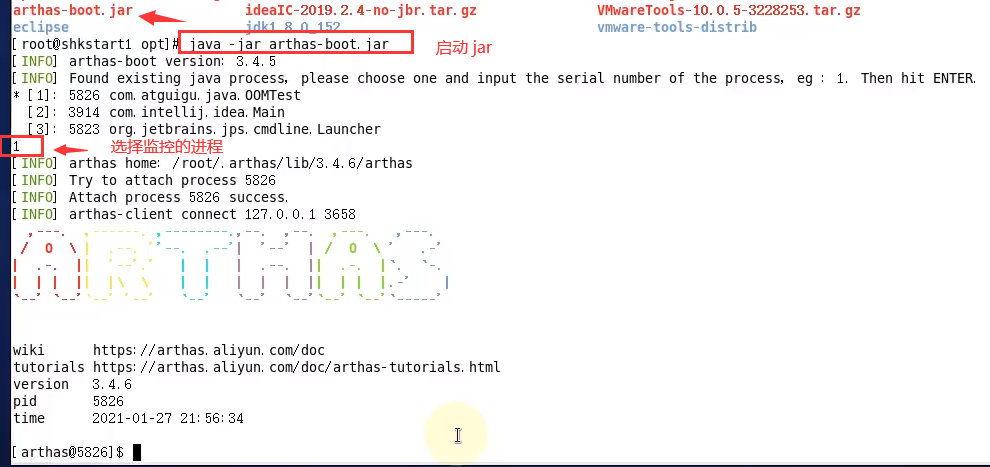
方式一:交互式选择进程
java -jar arthas-boot.jar1运行后,Arthas 会列出当前机器上所有正在运行的 Java 进程,提示用户输入要 Attach 的进程编号。
方式二:直接指定 PID
# 先用 jps 或 ps -ef | grep java 找到目标进程 PID jps # 假设 PID 为 5826 java -jar arthas-boot.jar 58261
2
3
4
进入 Arthas 控制台: Attach 成功后,会进入 Arthas 的命令行交互界面,显示
[arthas@<PID>]$提示符,可以在此输入各种诊断命令。
Web Console:
Arthas Attach 成功后,会自动在本地启动一个 Web 服务器(默认端口 8563)。可以通过浏览器访问 http://127.0.0.1:8563/ 来使用 Web 版的控制台,操作方式与命令行完全一致。
Arthas 常用指令 (部分):
(详细指令请参考官方文档,支持 Tab 自动补全)
基础指令:
help: 查看命令帮助。dashboard: 显示实时数据面板(线程、内存、GC、运行时信息等)。quit/exit: 退出当前 Arthas 客户端连接(服务端仍在运行)。stop/shutdown: 关闭 Arthas 服务端,所有客户端断开。cls: 清屏。history: 查看命令历史。reset: 重置所有被 Arthas 增强过的类(恢复原始字节码)。
JVM 相关:
thread: 查看线程信息,thread -b查看死锁,thread -n <N>查看最忙的 N 个线程。jvm: 查看 JVM 详细信息(内存、GC、类加载等)。sysprop: 查看或修改系统属性。sysenv: 查看环境变量。vmoption: 查看或修改 VM 参数(可管理的)。heapdump <file>: 生成 Heap Dump 文件。
类/类加载器相关:
sc: 搜索类信息 (-d查看详情,-f查看字段)。sm: 搜索方法信息 (-d查看详情)。jad <class>: 反编译类的源码。mc <file.java>: 内存编译 Java 文件。redefine <file.class>: 热更新(重新定义)已加载的类。dump <class>: Dump 类的字节码到文件。classloader: 查看类加载器信息。
方法执行监控/观测/追踪 (核心功能):
monitor: 监控方法的调用次数、成功/失败率、平均耗时。watch: 观测方法的入参、返回值、抛出异常、内部变量(使用 OGNL 表达式)。极其强大,可用于在线 Debug。trace: 追踪方法内部的调用路径及各步骤耗时。stack: 输出方法当前的被调用路径。tt: 时空隧道,记录方法每次调用的详细信息(入参、返回值、耗时等),并可以重新“播放”(replay) 调用过程。
性能分析:
profiler: 启动 async-profiler 进行 CPU 或内存采样,生成火焰图,定位性能热点。
Arthas 以其创新的非侵入式在线诊断能力,极大地提高了 Java 应用线上问题的排查效率,是现代 Java 开发者工具箱中的必备利器。
# 9. Java Mission Control (JMC) 与 Java Flight Recorder (JFR)
JMC 项目地址:
https://github.com/JDKMissionControl/jmc
JMC (Java Mission Control) 是 Oracle 官方提供的一款先进的 Java 监控和管理工具套件。它起源于 JRockit 虚拟机(被 Oracle 收购),后来其核心特性被集成到 HotSpot VM 中。
- 历史:Oracle JDK 7u40 之后内置 JMC。自 Java 11 起,JMC 及其核心组件 JFR (Java Flight Recorder) 已开源。在之前的 Oracle JDK 版本中,JFR 属于商业特性,需要通过
-XX:+UnlockCommercialFeatures参数开启。 - 组成:JMC 主要包含一个 GUI 客户端 和多个插件,其中最重要的插件是 JMX Console 和 Java Flight Recorder (JFR)。
核心优势:
- 极低性能开销:JFR 采用事件采样 (Event Sampling) 而不是代码插桩技术,对正在运行的 Java 应用性能影响极小(官方称默认配置下平均低于 1%)。这使得它非常适合在生产环境下长时间开启,用于监控和诊断满负荷运行的应用。
- 数据全面深入:JFR 能够直接访问 JVM 内部数据,记录非常详细的运行时事件,包括 Java 层面(线程、锁、IO、Socket 等)和 JVM 内部(对象分配、GC、JIT 编译、类加载、安全点等)。
- 工具链完整:JFR 负责高效地收集数据(生成
.jfr文件),JMC 则提供了强大的分析功能来解读这些数据。
Java Flight Recorder (JFR):
JFR 是 JMC 的数据收集引擎。启用后,它会记录一系列在 JVM 运行过程中发生的事件 (Events)。
JFR 事件类型:
- 瞬时事件 (Instant Event):关心其发生与否,如异常抛出、线程启动/结束。
- 持续事件 (Duration Event):关心其持续时间,如 GC、JIT 编译、锁等待、Socket 读写。
- 计时事件 (Timed Event):是持续时间超过了预设阈值的持续事件。
- 取样事件 (Sample Event):周期性地采样获取信息,如方法采样(定期获取线程栈)、对象分配采样。
方法抽样 (Method Sampling) 是 JFR 常用的分析热点代码的方式。通过定期获取所有线程的调用栈,如果某个方法在采样结果中反复出现,则可以推断该方法是性能热点。
使用 JFR 和 JMC:
启用 JFR 记录:
启动参数方式 (推荐):
# 启动时开启 JFR,记录数据到文件 myrecording.jfr java -XX:StartFlightRecording=filename=myrecording.jfr,duration=5m MyApp # 可以指定记录时长 (duration), 文件大小 (maxsize), 事件配置 (settings=profile/default) 等 java -XX:StartFlightRecording=settings=profile,filename=myrec.jfr,dumponexit=true MyApp1
2
3
4动态开启 (通过
jcmd):# 启动 JFR 记录,持续 60 秒,保存到 recording.jfr jcmd <pid> JFR.start name=myrec duration=60s filename=recording.jfr # 查看记录状态 jcmd <pid> JFR.check # 停止记录 jcmd <pid> JFR.stop name=myrec # Dump 记录到文件 jcmd <pid> JFR.dump name=myrec filename=dumped.jfr1
2
3
4
5
6
7
8通过 JMC GUI 开启:连接到目标 JVM 后,在 JMC 客户端中启动飞行记录。
使用 JMC 分析
.jfr文件:- 启动 JMC (位于 JDK
bin目录下,jmc.exe或jmc)。 File->Open File...选择.jfr文件。- JMC 会自动对 JFR 数据进行分析,并以丰富的图表和列表形式展示结果。
- 启动 JMC (位于 JDK
JMC 分析界面示例:
JMC 提供了非常丰富的分析视图,包括但不限于:
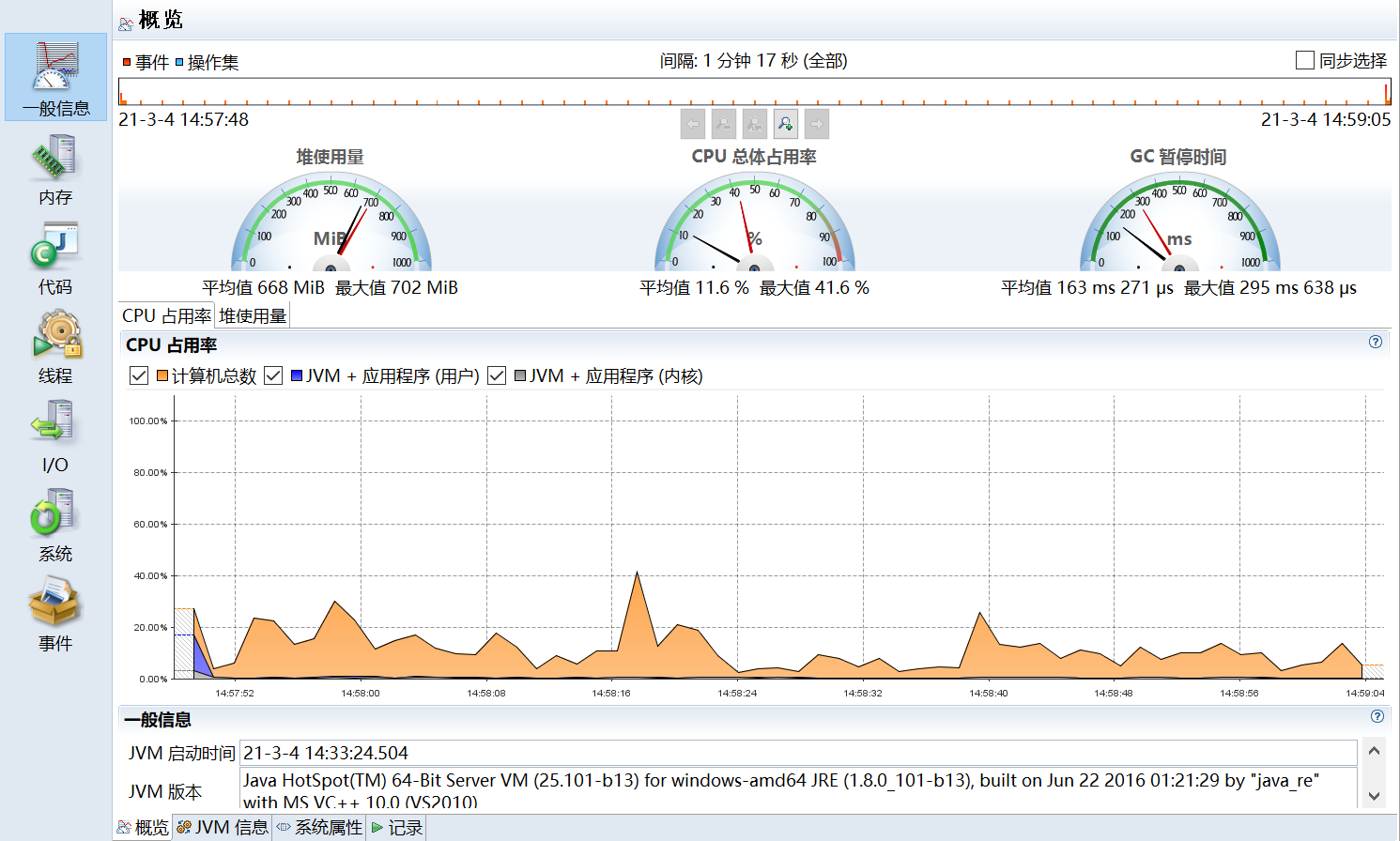
- 总览 (Overview):JVM 基本信息、主要发现。
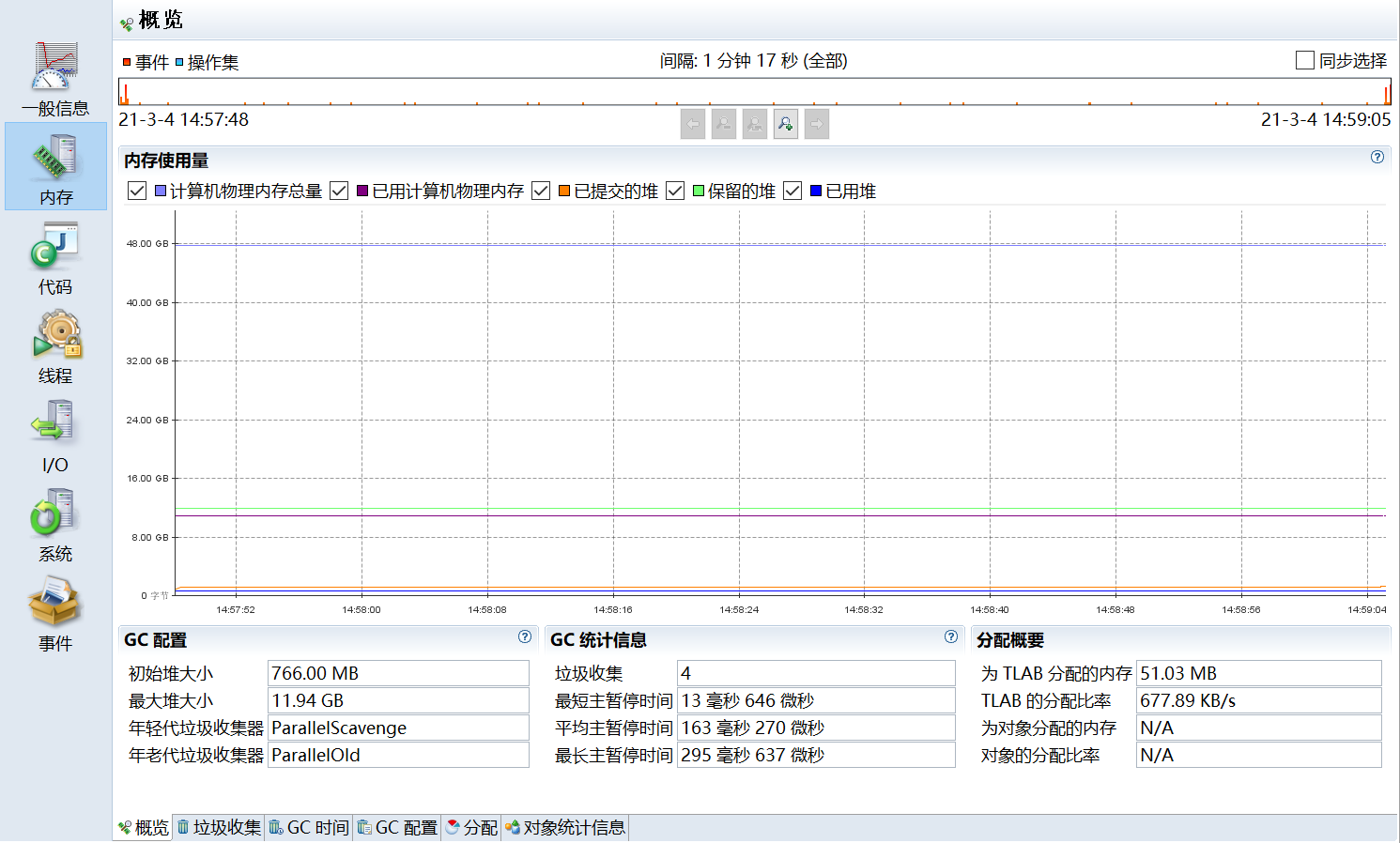
- 内存 (Memory):
- 对象分配统计、压力最大的线程。
- GC 时间、频率、原因分析。
- 堆内存使用趋势。
- 代码 (Code):
- 热点方法 (Hot Methods):通过方法采样找出 CPU 占用高的方法。
- 异常统计。
- 类加载信息。
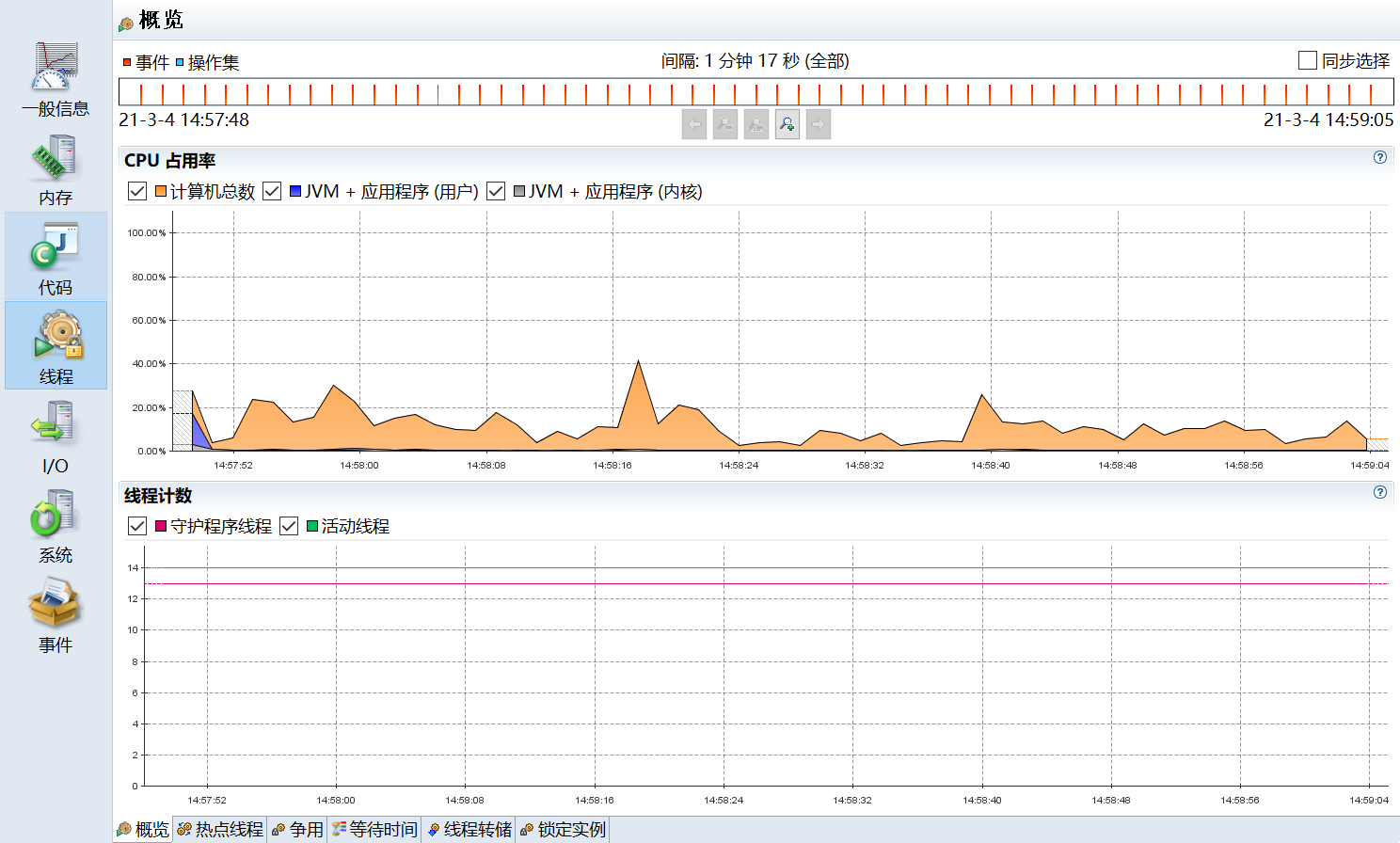
- 线程 (Threads):
- 线程活动时间线。
- 锁竞争分析 (Lock Contention):找出哪些锁被激烈竞争,哪些线程等待时间最长。
- 热点线程。
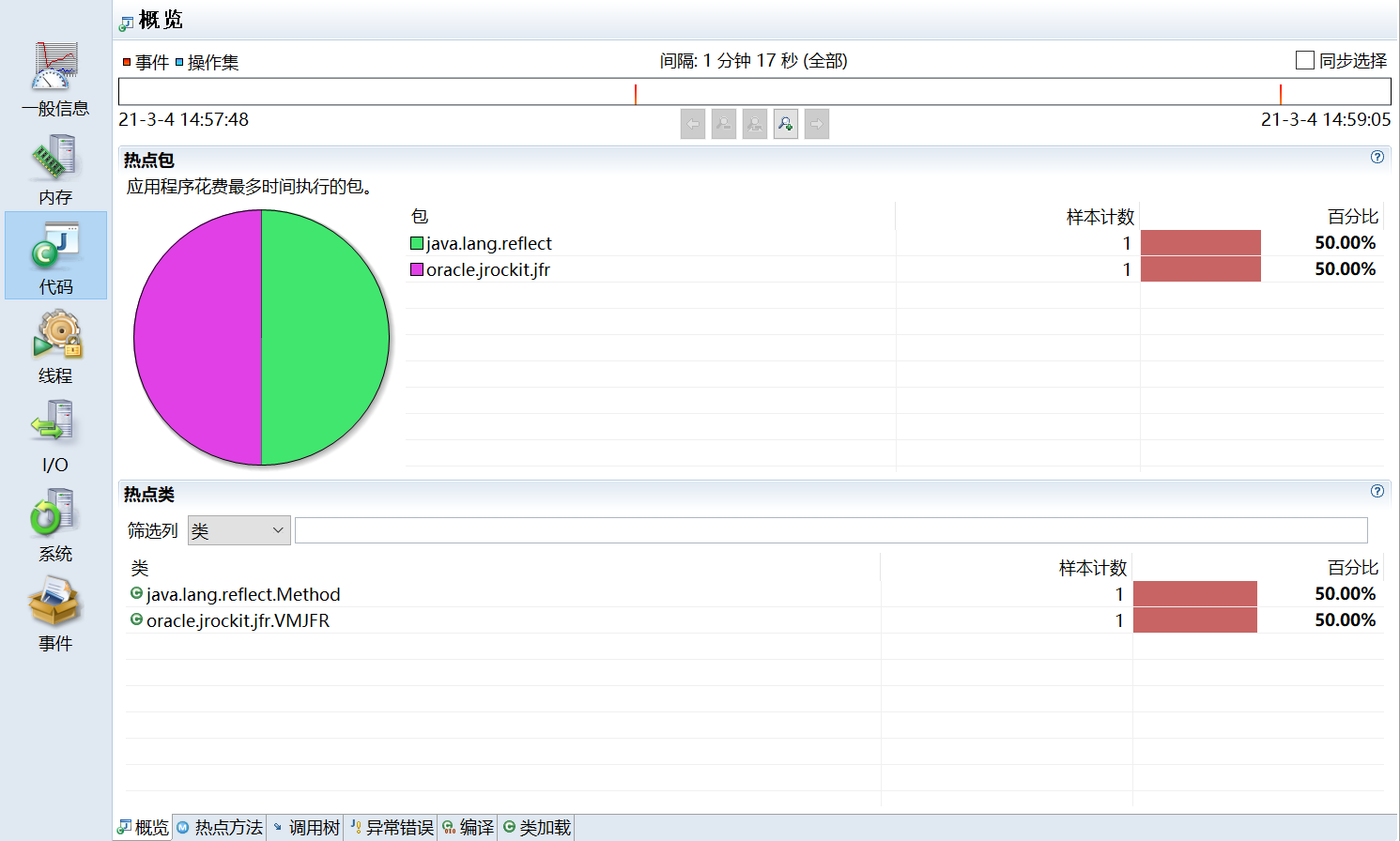
- I/O:
- 文件读写统计。
- Socket 读写统计。
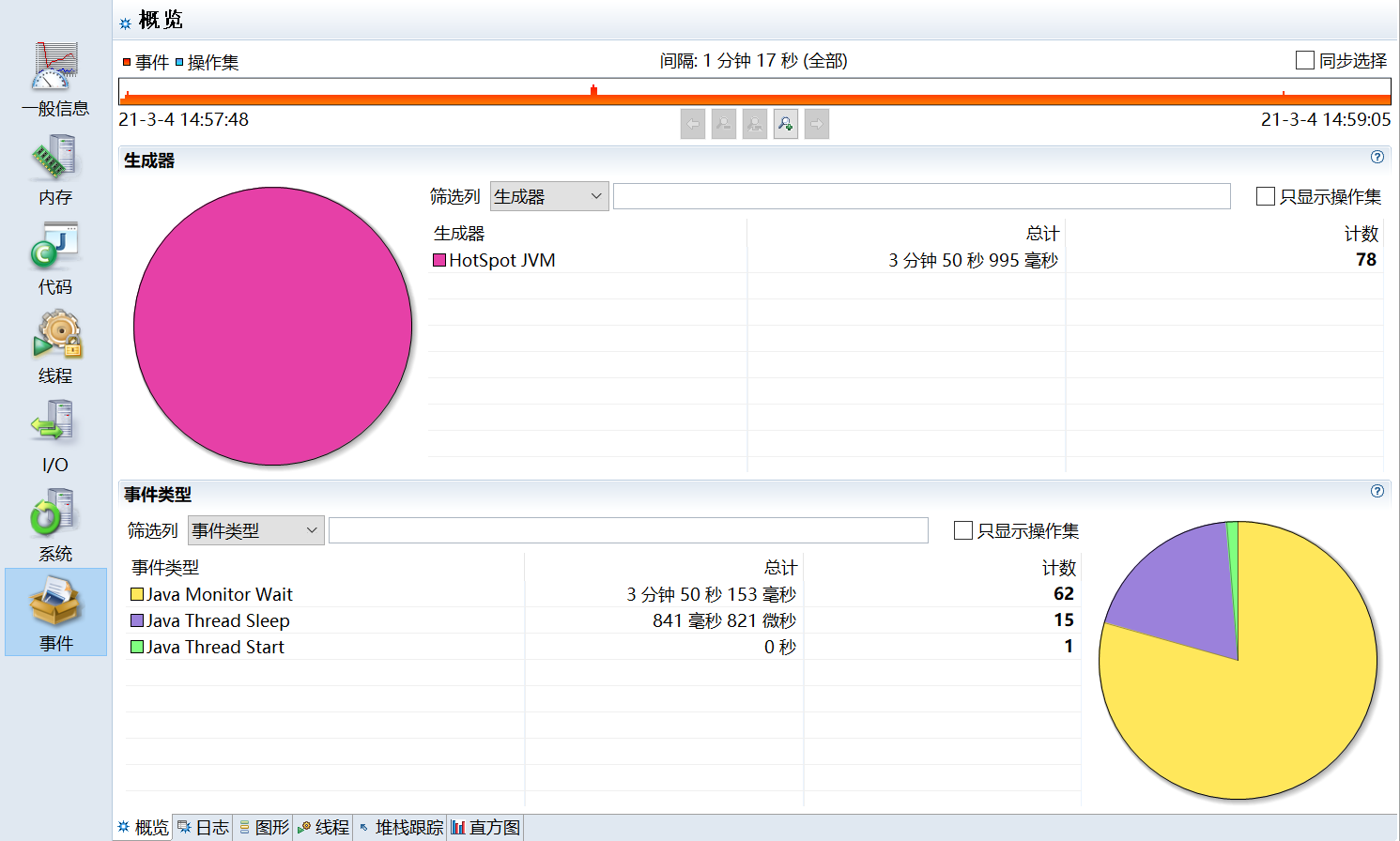
- 系统 (System):CPU 负载、环境变量、系统属性。

- 事件 (Events):可以按类型查看 JFR 记录的所有原始事件。

JMC + JFR 因其低开销和数据全面的特点,特别适合用于生产环境的持续监控和问题诊断。
# 10. 其他相关工具与技术
除了上述主流工具外,还有一些其他值得了解的性能分析工具和技术:
# 火焰图 (Flame Graphs)
- 概念:由 Brendan Gregg 发明的一种性能可视化技术,用于直观地展示 CPU 在程序运行期间的时间消耗分布。
- 特点:
- X 轴:表示 CPU 采样时间。一个方法的横条越宽,表示它(及其调用的子方法)占用的 CPU 时间越多。注意:X 轴通常不代表时间顺序,而是将同名函数合并后的宽度。
- Y 轴:表示调用栈的深度。下面的函数调用上面的函数。
- 颜色:通常没有特殊含义,用于区分不同的函数帧。
- 解读:火焰图顶层(最宽的“火焰山”)代表了消耗 CPU 最多的代码路径。通过观察火焰的宽度和层次,可以快速定位 CPU 性能瓶颈。
- 生成:通常需要结合采样工具(如
perf(Linux),DTrace(macOS/Solaris),async-profiler, JFR)获取调用栈采样数据,然后使用 Brendan Gregg 提供的脚本 (flamegraph.pl) 生成 SVG 格式的火焰图。Arthas 的profiler命令可以直接生成火焰图。 图:火焰图示例
图:火焰图示例
# TProfiler
- 来源:阿里巴巴开源的 Profiler 工具 (
https://github.com/alibaba/TProfiler)。 - 特点:旨在解决特定场景下的性能问题,例如 GC 过于频繁。其核心特性之一是能够统计指定时间段内 JVM 的 Top Methods(调用最频繁或耗时最多的方法),这对于定位造成性能瓶颈(如大量临时对象创建)的代码非常有帮助。据称这是 JMC/JFR 等工具不直接支持的功能。
- 应用场景:据案例分享,使用 TProfiler 成功定位并解决了因业务代码问题导致的频繁 GC,显著提升了 TPS。
# BTrace
- 来源:曾经是 SUN Kenai 平台下的开源项目,现在可能由社区维护。
- 定义:一个用于 Java 平台的安全、动态的追踪工具。
- 原理:使用 Java Agent 技术和字节码注入,允许用户编写简单的 Java 脚本,在不停止目标 JVM 的情况下,动态地插入追踪代码到运行中的类方法中,以获取方法参数、返回值、执行时间、调用位置等信息。
- 优势:动态、非侵入式(相对而言,仍有字节码修改开销),脚本语法类似 Java,相对易用。
- 限制:为了安全,BTrace 脚本能做的事情受到严格限制(如不能创建新对象、不能修改目标程序状态、不能调用大部分 JDK 类库等)。
- 现状:随着 Arthas 等更现代化工具的兴起,BTrace 的使用可能相对减少,但其动态追踪的思想仍然很有价值。
 图:BTrace 官方定义截图
图:BTrace 官方定义截图
# 其他工具
- YourKit Java Profiler: 另一款功能强大的商业 Java Profiler,与 JProfiler 类似。
- JProbe: 曾经流行的商业 Profiler,现在可能已被其他工具取代或整合。
- Spring Insight: Spring 框架提供的应用性能监控工具,侧重于 Spring 应用内部的请求追踪和性能分析。
选择合适的工具取决于具体的需求、场景(开发/测试/生产)、预算以及团队的熟悉程度。掌握一到两款主流的 GUI 工具(如 VisualVM/MAT 或 JProfiler/JMC)并结合命令行工具和 Arthas,将能有效应对大部分 Java 性能问题。