 JVM - 字符串常量池 (StringTable)
JVM - 字符串常量池 (StringTable)
# 1. String 的基本特性
String 是 Java 中非常基础且重要的类,用于表示字符串。理解其特性对于深入 JVM 至关重要。
声明方式: 使用一对双引号
""或new String()关键字。// 字面量定义方式,"kele" 会放入字符串常量池 String s1 = "kele"; // new 对象的方式,对象在堆中,"bingtang" 字面量可能在常量池 String s2 = new String("bingtang");1
2
3
4final类:String类被final修饰,意味着它不能被继承。这是为了保证其不可变性和安全性。接口实现:
- 实现
Serializable接口:表示字符串对象支持序列化,可以在网络传输或持久化到文件中。 - 实现
Comparable<String>接口:表示字符串可以进行比较大小(按字典顺序)。
- 实现
内部存储结构变化 (JDK 9):
JDK 8 及以前: 内部使用
final char[] value存储字符串数据,每个字符占用 2 个字节 (UTF-16)。// JDK 8 内部结构 private final char value[];1
2JDK 9 及以后: 改为
final byte[] value加上一个编码标志coder。// JDK 9+ 内部结构 private final byte[] value; private final byte coder; // 0 for Latin-1, 1 for UTF-161
2
3改变原因: 大量应用数据显示,字符串是堆内存的主要消耗者,且大部分字符串只包含 Latin-1 字符(只需 1 字节存储)。使用
char[]会导致一半空间浪费。改为byte[]+coder标志,可以根据字符串内容选择使用 Latin-1(1字节/字符)或 UTF-16(2字节/字符)编码,显著节约内存空间。StringBuilder和StringBuffer也同步做了修改。
# 1.1 String 的不可变性 (Immutability)
String 对象一旦创建,其内容(字符序列)就不能被改变。这是 String 最核心的特性之一。
- 重新赋值: 当给一个
String变量重新赋值时,并不是修改原始字符串对象,而是让变量指向一个新的字符串对象。 - 连接操作: 使用
+或concat()连接字符串时,会创建一个包含连接结果的新的String对象。 replace()操作: 调用replace()方法替换字符或子串时,会返回一个新的String对象,原始对象不变。- 字面量存储: 通过字面量方式 (
"...") 创建的字符串,其值存储在字符串常量池 (StringTable) 中。
代码示例:
// 文件名: StringTest1.java
/**
* 演示 String 的不可变性
*/
public class StringTest1 {
public static void test1() {
// s1 和 s2 指向常量池中同一个 "abc" 对象
String s1 = "abc";
String s2 = "abc";
System.out.println("s1 == s2 (before reassign): " + (s1 == s2)); // true
// s1 重新赋值,指向常量池中(或新创建的)"hello" 对象
// s2 仍然指向 "abc"
s1 = "hello";
System.out.println("s1 == s2 (after reassign): " + (s1 == s2)); // false
System.out.println("s1: " + s1); // hello
System.out.println("s2: " + s2); // abc
System.out.println("----------------");
}
public static void test2() {
String s1 = "abc";
String s2 = "abc";
// 字符串连接操作 += 会创建一个新的 String 对象 ("abcdef")
// s2 指向这个新对象,s1 保持不变
s2 += "def";
System.out.println("s1: " + s1); // abc
System.out.println("s2: " + s2); // abcdef
System.out.println("----------------");
}
public static void test3() {
String s1 = "abc";
// replace 方法返回一个新的 String 对象 ("mbc")
// s2 指向新对象,s1 保持不变
String s2 = s1.replace('a', 'm');
System.out.println("s1: " + s1); // abc
System.out.println("s2: " + s2); // mbc
}
public static void main(String[] args) {
test1();
test2();
test3();
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
运行结果:
s1 == s2 (before reassign): true
s1 == s2 (after reassign): false
s1: hello
s2: abc
----------------
s1: abc
s2: abcdef
----------------
s1: abc
s2: mbc
2
3
4
5
6
7
8
9
10
# 1.2 面试题:String 作为方法参数
// 文件名: StringExer.java
/**
* 面试题:分析 String 和 char[] 作为方法参数传递后的变化
*/
public class StringExer {
// str 指向堆中 new String("good") 对象,"good" 字面量在常量池
String str = new String("good");
// ch 指向堆中 new char[]{'t','e','s','t'} 数组对象
char[] ch = {'t', 'e', 's', 't'};
/**
* 修改传入的 String 引用和 char[] 数组内容
* @param str 方法内的局部变量,接收 ex.str 的地址副本
* @param ch 方法内的局部变量,接收 ex.ch 的地址副本
*/
public void change(String str, char ch[]) {
// 1. 对 String 的修改:
// str 是局部变量,这行代码让局部变量 str 指向一个新的字符串 "test ok" (在常量池或堆中创建)
// 它并没有改变 main 方法中 ex.str 指向的对象的内容
str = "test ok";
// 2. 对 char[] 的修改:
// ch 是局部变量,存储的是数组对象的地址。
// ch[0] = 'b' 是通过这个地址访问到堆中的数组对象,并修改了其第一个元素的内容。
ch[0] = 'b';
}
public static void main(String[] args) {
StringExer ex = new StringExer();
// 调用 change 方法时,传递的是 ex.str 和 ex.ch 的地址值的副本
ex.change(ex.str, ex.ch);
// 打印 ex.str:由于 String 的不可变性以及 Java 值传递特性,ex.str 指向的对象内容未变
System.out.println("ex.str: " + ex.str); // 输出 good
// 打印 ex.ch:由于 change 方法修改了 ex.ch 指向的数组对象的内容,所以输出改变后的内容
System.out.print("ex.ch: ");
System.out.println(ex.ch); // 输出 best (数组内容被修改了)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
输出结果:
ex.str: good
ex.ch: best
2
解释:Java 中方法参数传递是值传递 (pass-by-value)。对于引用类型,传递的是引用的地址值的副本。
- 在
change方法中修改str = "test ok",只是让方法内的局部变量str指向了新的字符串对象,并没有影响到main方法中ex.str指向的原始对象。 - 在
change方法中修改ch[0] = 'b',是通过地址副本访问到了main方法中ex.ch指向的同一个数组对象,并修改了该对象的内容。
# 1.3 字符串常量池 (String Pool / String Table)
- 唯一性: 字符串常量池中不会存储相同内容(
equals()比较为 true)的字符串。如果尝试存入一个已存在的字符串,会返回池中已存在对象的引用。 - 实现: 内部是一个固定大小的 HashTable(哈希表,通常使用开放寻址法或链地址法解决冲突)。
- 大小与性能:
- HashTable 的大小(桶的数量)会影响
String.intern()方法的性能。如果池中字符串非常多,而桶数量(StringTableSize)过小,会导致严重的哈希冲突,链表过长,查找和插入效率大幅下降。 - JDK 6:
StringTableSize固定为 1009。 - JDK 7:
StringTableSize默认值为 60013。 - JDK 8+:
StringTableSize最小值为 1009,默认值可能与 JDK 7 类似或根据 CPU 核心数等因素调整。 - 配置: 可以使用 JVM 参数
-XX:StringTableSize=<size>来设置 StringTable 的大小(设置为一个合适的素数通常性能较好)。
- HashTable 的大小(桶的数量)会影响
测试 StringTableSize 对 intern() 性能的影响:
生成测试数据 (写入
words.txt):// 文件名: GenerateString.java import java.io.FileWriter; import java.io.IOException; import java.util.Random; /** * 生成包含 10 万个随机字符串(长度 1-10,包含大小写字母)的文件 */ public class GenerateString { public static void main(String[] args) throws IOException { FileWriter fw = new FileWriter("words.txt"); Random random = new Random(); System.out.println("开始生成字符串..."); for (int i = 0; i < 100000; i++) { int length = random.nextInt(10) + 1; // 长度 1 到 10 fw.write(getString(length, random) + "\n"); } fw.close(); System.out.println("字符串生成完毕: words.txt"); } /** * 生成指定长度的随机字符串 (a-z, A-Z) */ public static String getString(int length, Random random) { StringBuilder sb = new StringBuilder(length); for (int i = 0; i < length; i++) { // 随机决定大小写 int base = (random.nextBoolean()) ? 'A' : 'a'; // 随机生成 0-25 的偏移量 int offset = random.nextInt(26); sb.append((char)(base + offset)); } return sb.toString(); } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36读取文件并调用
intern()测试性能:// 文件名: StringTest2.java import java.io.BufferedReader; import java.io.FileReader; import java.io.IOException; public class StringTest2 { public static void main(String[] args) { System.out.println("开始读取文件并调用 intern()..."); BufferedReader br = null; try { br = new BufferedReader(new FileReader("words.txt")); long start = System.currentTimeMillis(); String data; int count = 0; while ((data = br.readLine()) != null) { // 将读取到的字符串尝试放入字符串常量池 // 如果池中没有,则放入;如果已有,则返回池中引用 data.intern(); count++; } long end = System.currentTimeMillis(); System.out.println("处理了 " + count + " 个字符串"); System.out.println("花费的时间为:" + (end - start) + "ms"); } catch (IOException e) { e.printStackTrace(); } finally { if (br != null) { try { br.close(); } catch (IOException e) { e.printStackTrace(); } } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
运行测试 (示例结果,具体时间依赖机器性能):
使用默认
StringTableSize(例如 60013 或更大):花费的时间为:47ms1设置较小的
StringTableSize(例如-XX:StringTableSize=1009):花费的时间为:143ms1结论:
StringTableSize设置过小会导致intern()性能显著下降。对于需要大量使用intern()的应用,适当增大StringTableSize可以提高性能。
# 2. String 的内存分配
理解 String 对象在 JVM 内存(堆、字符串常量池)中的位置是关键。
常量池概念: Java 为 8 种基本数据类型和
String提供了常量池机制,以缓存常用值,提高性能和节省内存。String的常量池(StringTable)最为特殊和常用。字面量存储: 直接使用双引号
""声明的字符串(字面量),其对象实例存储在字符串常量池中。JVM 会确保相同内容的字面量只在池中存在一份。String info = "youngkbt.cn"; // "youngkbt.cn" 在常量池中,info 指向池中地址1new String()存储: 使用new String(...)创建的对象实例存储在Java 堆中。如果构造器参数是字符串字面量(如new String("abc")),JVM 会确保"abc"这个字面量存在于常量池中,但new操作本身总是在堆中创建一个新的String对象。intern()方法: 可以将一个堆中的String对象尝试放入字符串常量池。其行为细节随 JDK 版本变化(详见后文)。
字符串常量池的位置演变 (HotSpot VM):
- JDK 6 及以前: 字符串常量池位于永久代 (Permanent Generation) 中。永久代是方法区的一种实现,位于堆内(但由特定参数控制大小)。
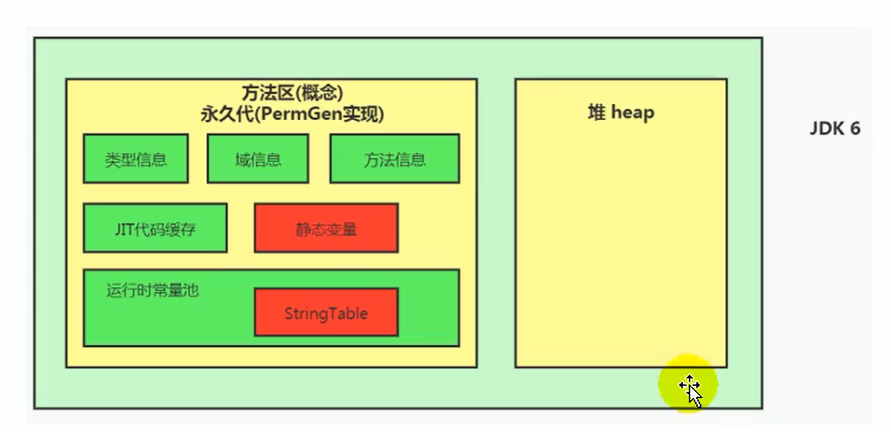
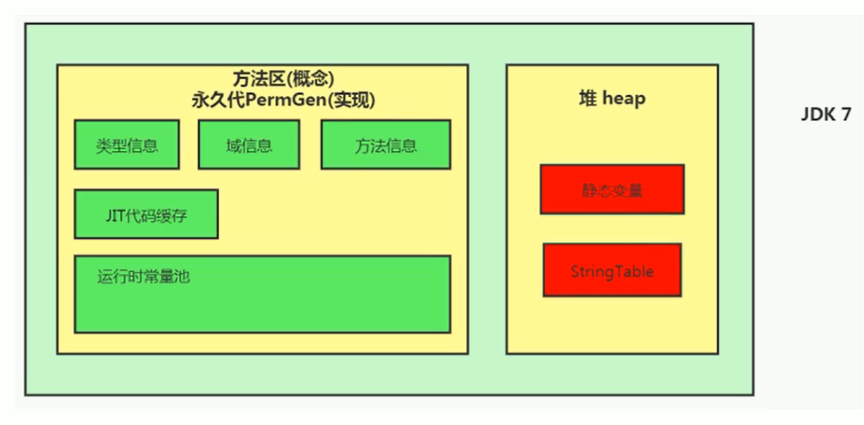
- JDK 7: 字符串常量池从永久代移动到了 Java 堆的主要区域(年轻代/老年代)中。永久代仍然存在,但不再存储字符串常量。
- JDK 8 及以后: 永久代被元空间 (Metaspace) 取代(元空间使用本地内存存储类元数据)。字符串常量池仍然位于 Java 堆中。
为什么将 StringTable 从永久代移到堆中?
- 永久代空间有限且难于调优: 永久代的默认大小通常较小 (
-XX:MaxPermSize),如果应用加载大量类或大量使用intern(),容易导致PermGen space OOM。准确预估所需大小很困难。 - 永久代 GC 效率低: 永久代的垃圾回收通常只在 Full GC 时进行,频率较低。对于生命周期可能较短的字符串常量来说,存放在永久代意味着它们可能长时间得不到回收,即使已经不再被引用。
- 简化内存调优: 将字符串常量池移到堆中,意味着只需要关注和调整堆大小 (
-Xmx) 即可,无需再单独管理永久代(或元空间主要用于类元数据)。堆内存通常更大,且 GC(特别是 Minor GC)更频繁,有助于及时回收不再使用的字符串常量。
实验验证 StringTable 在堆中 (JDK 8+)
通过限制堆和元空间的大小,观察 OOM 类型。
// 文件名: StringTest3.java
import java.util.HashSet;
import java.util.Set;
/**
* 测试 StringTable 在哪个区域导致 OOM
* JDK 8 VM Options: -XX:MetaspaceSize=6m -XX:MaxMetaspaceSize=6m -Xms6m -Xmx6m
*/
public class StringTest3 {
public static void main(String[] args) {
// 使用 Set 持有 intern() 返回的引用,防止字符串常量被 GC 回收
Set<String> set = new HashSet<>();
// short 范围是 -32768 到 32767,足够多
short i = 0;
while (true) {
// 不断生成新的字符串并放入常量池
set.add(String.valueOf(i++).intern());
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
运行结果 (使用 JDK 8+):
Exception in thread "main" java.lang.OutOfMemoryError: Java heap space
at java.util.HashMap.resize(HashMap.java:703)
at java.util.HashMap.putVal(HashMap.java:662)
at java.util.HashMap.put(HashMap.java:611)
at java.util.HashSet.add(HashSet.java:219)
at StringTest3.main(StringTest3.java:16) // 指向 set.add(...)
Process finished with exit code 1
2
3
4
5
6
7
8
结论:程序抛出的是 Java heap space OOM,而不是 Metaspace OOM。这证明了在 JDK 8+ 中,intern() 操作尝试放入的字符串常量池位于 Java 堆中。如果 StringTable 在元空间,应该抛出 Metaspace OOM。
# 3. String 的基本操作示例
字符串字面量的复用:
Java 语言规范要求,内容相同的字符串字面量必须指向常量池中的同一个 String 实例。
// 文件名: StringTest4.java
public class StringTest4 {
public static void main(String[] args) {
// JVM 启动时和执行代码过程中会加载很多类,这些类中包含的字符串字面量会进入常量池
// System.out.println(); // 打印空行,可能也涉及字符串处理
System.out.println("1"); // "1" 进入常量池
System.out.println("2"); // "2" 进入常量池
// ... (打印 "3" 到 "10")
System.out.println("10"); // "10" 进入常量池
System.out.println("--- 分割线 ---");
// 再次使用相同的字面量,它们会指向常量池中已存在的对象
String s1 = "1";
String s2 = "1";
System.out.println("s1 == \"1\": " + (s1 == "1")); // true
System.out.println("s1 == s2: " + (s1 == s2)); // true
// ... (其他字面量类似)
String s10 = "10";
System.out.println("s10 == \"10\": " + (s10 == "10")); // true
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
(可以通过 -XX:+PrintStringTableStatistics 观察常量池大小和条目数变化)
对象创建时的内存交互:
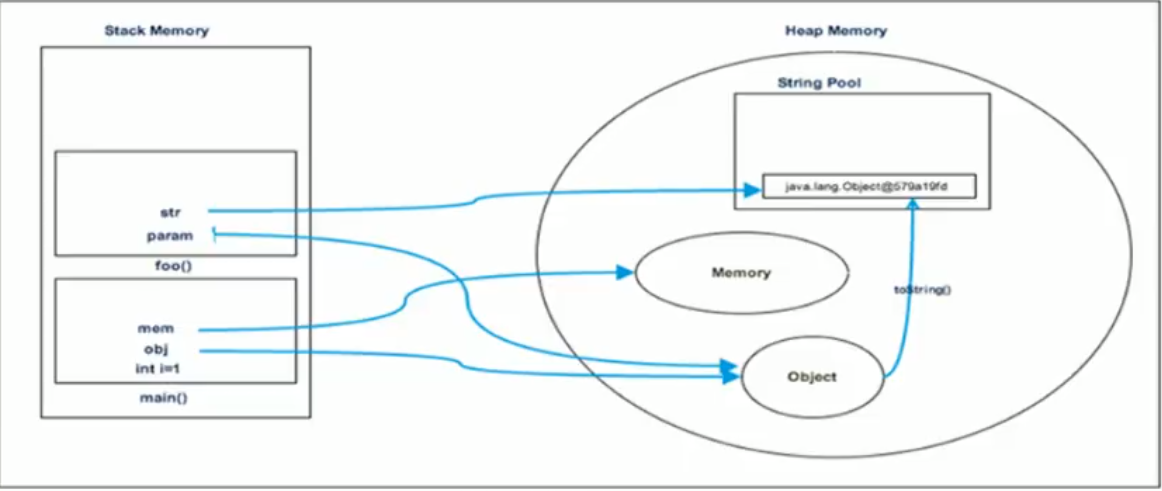
分析一个包含对象创建和方法调用的简单例子中,栈、堆、方法区(常量池)的交互。
// 文件名: Memory.java (官方示例)
class Memory {
public static void main(String[] args) { // line 1
int i = 1; // line 2: 局部变量 i 在栈帧中
Object obj = new Object(); // line 3: 局部变量 obj 在栈帧中,指向堆中的 Object 实例
Memory mem = new Memory(); // line 4: 局部变量 mem 在栈帧中,指向堆中的 Memory 实例
mem.foo(obj); // line 5: 调用实例方法 foo
} // line 9: main 方法结束,栈帧销毁
private void foo(Object param) { // line 6: param 是局部变量,接收 obj 的地址副本
String str = param.toString(); // line 7: 调用 obj.toString(),结果(字符串)在堆或常量池,str 指向它
System.out.println(str); // 打印字符串
} // line 8: foo 方法结束,栈帧销毁
}
2
3
4
5
6
7
8
9
10
11
12
13
14
运行时内存示意图 (执行到 line 7):
 (注意:实例方法
(注意:实例方法 foo 调用时,其栈帧的局部变量表中除了参数 param 和局部变量 str,还隐含一个 this 引用,指向调用该方法的 mem 对象)
# 4. 字符串拼接操作 (String Concatenation)
字符串拼接是常见操作,其底层实现和性能需要关注。
规则总结:
常量 vs 常量: 如果拼接
+两边的操作数都是编译期常量(字面量、final基本类型/String),结果在编译期直接计算出来,等同于一个常量字符串,存储在字符串常量池中。这是编译期优化。String s1 = "a" + "b" + "c"; // 编译后等同于 String s1 = "abc"; String s2 = "abc"; System.out.println(s1 == s2); // true1
2
3字节码验证 (
test1方法):// 编译后的字节码直接加载 "abc" 0: ldc #2 // String "abc" 2: astore_1 // s1 = "abc" 3: ldc #2 // String "abc" 5: astore_2 // s2 = "abc" // ... 比较 s1 和 s2 ...1
2
3
4
5
6变量 vs 常量/变量: 只要拼接
+两边有任何一个是变量(非final编译期常量),编译器就会在运行时使用StringBuilder(JDK 5+)或StringBuffer(JDK 5 之前)来完成拼接。最终调用toString()方法会在堆上创建一个新的String对象。String s1 = "javaEE"; // 常量池 String s2 = "hadoop"; // 常量池 String s3 = "javaEEhadoop"; // 常量池 String s4 = "javaEE" + "hadoop"; // 常量池 ("javaEEhadoop") String s5 = s1 + "hadoop"; // 运行时 new StringBuilder().append(s1).append("hadoop").toString() -> 新对象在堆 String s6 = "javaEE" + s2; // 运行时 new StringBuilder().append("javaEE").append(s2).toString() -> 新对象在堆 String s7 = s1 + s2; // 运行时 new StringBuilder().append(s1).append(s2).toString() -> 新对象在堆 System.out.println(s3 == s4); // true (都是常量池中的 "javaEEhadoop") System.out.println(s3 == s5); // false (常量池 vs 堆) System.out.println(s3 == s6); // false (常量池 vs 堆) System.out.println(s3 == s7); // false (常量池 vs 堆) System.out.println(s5 == s6); // false (堆中不同对象) System.out.println(s5 == s7); // false (堆中不同对象) System.out.println(s6 == s7); // false (堆中不同对象)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16intern()的影响: 如果对变量拼接的结果调用intern()方法,JVM 会检查常量池。如果池中已存在等值的字符串,返回池中引用;如果不存在,则根据 JDK 版本行为(JDK 7+ 可能会将堆中对象的引用放入池表)将字符串(或其引用)放入池中,并返回池中的引用。String s8 = s6.intern(); // s6 是堆中的 "javaEEhadoop" // intern() 查找常量池,发现 s3 ("javaEEhadoop") 已经在池中 // 所以 intern() 返回常量池中 s3 的引用 System.out.println(s3 == s8); // true1
2
3
4
变量拼接底层原理 (StringBuilder):
String s1 = "a";
String s2 = "b";
String s4 = s1 + s2; // 运行时实际执行类似以下代码
/*
// 1. 创建 StringBuilder 对象
StringBuilder sb = new StringBuilder();
// 2. 追加第一个操作数
sb.append(s1); // append("a")
// 3. 追加第二个操作数
sb.append(s2); // append("b")
// 4. 调用 toString() 生成最终的 String 对象(在堆中)
String result = sb.toString(); // 内部会 new char[], new String(...)
*/
String s3 = "ab"; // 常量池
System.out.println(s3 == s4); // false (常量池 vs 堆)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
字节码验证 (test3 方法): 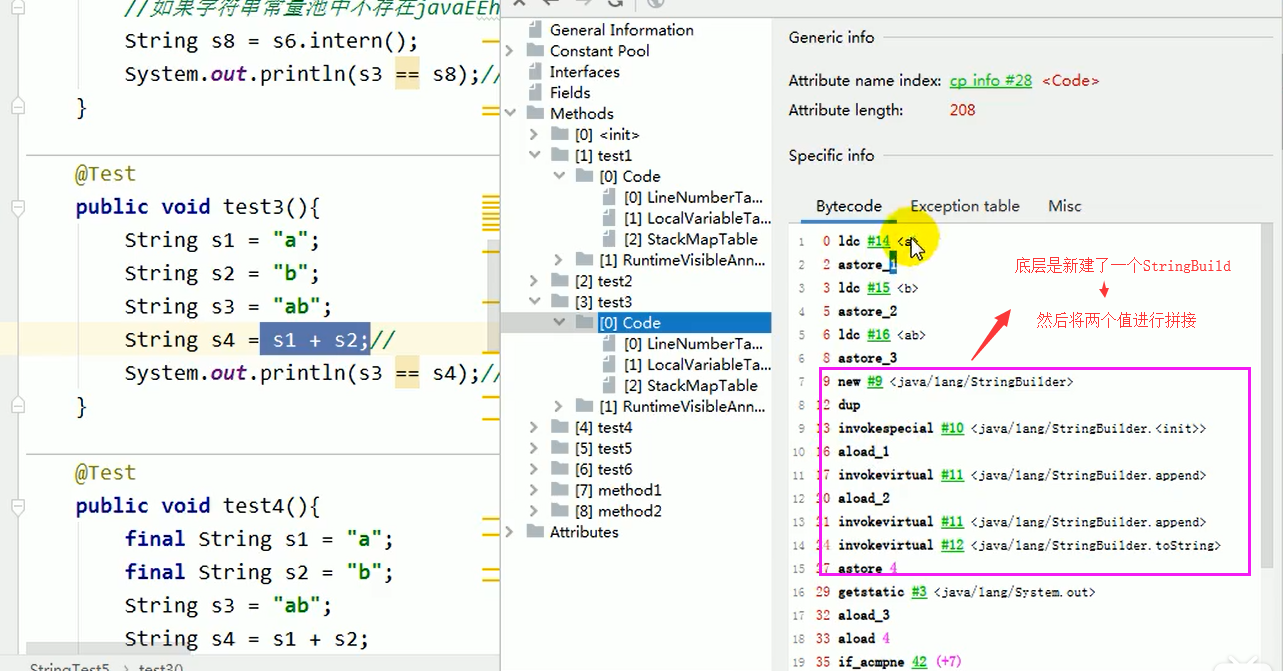 (可以看到
(可以看到 new StringBuilder, append, toString 的调用)
String vs StringBuffer vs StringBuilder:
| 特性 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 可变性 | 不可变 (Immutable) | 可变 (Mutable) | 可变 (Mutable) |
| 线程安全 | 天生线程安全 (因为不可变) | 线程安全 (Synchronized) | 线程不安全 (Not Synchronized) |
| 性能 | 拼接/修改性能低 (创建新对象) | 性能较高 (内部数组可扩展) | 性能最高 (无同步开销) |
| 适用场景 | 字符串内容基本不变 | 多线程环境下的字符串拼接/修改 | 单线程环境下的字符串拼接/修改 |
final 变量的拼接优化:
如果参与拼接的变量被 final 修饰,并且其值在编译期可知(即 compile-time constant),编译器可能会将其视为常量进行优化,直接计算结果放入常量池。
final String s1 = "a"; // s1 是编译期常量
final String s2 = "b"; // s2 是编译期常量
String s3 = "ab"; // 常量池
String s4 = s1 + s2; // 编译器优化为 "a" + "b" -> "ab"
System.out.println(s3 == s4); // true (都指向常量池的 "ab")
// 对比:如果 s4 不是 final
String s5 = "javaEE";
String s6 = s5 + "hadoop"; // s5 是变量,使用 StringBuilder -> 堆对象
String s1_pool = "javaEEhadoop"; // 常量池
System.out.println(s1_pool == s6); // false
// 如果 s5 是 final
final String s7 = "javaEE"; // s7 是编译期常量
String s8 = s7 + "hadoop"; // 编译器优化为 "javaEE" + "hadoop" -> "javaEEhadoop"
System.out.println(s1_pool == s8); // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
建议: 在开发中,如果一个变量的值不会改变,尽量使用 final 修饰,有助于编译器优化和提高代码可读性。
循环内拼接性能对比:
在循环中反复使用 += 进行字符串拼接性能极差,因为每次循环都会创建一个新的 StringBuilder 和 String 对象。应使用显式的 StringBuilder.append()。
// 方法1:低效拼接
public static void method1(int highLevel) {
String src = "";
for (int i = 0; i < highLevel; i++) {
src += "a"; // 每次循环都会隐式创建 StringBuilder 和 String
}
}
// 方法2:高效拼接
public static void method2(int highLevel) {
// 只需要创建一个 StringBuilder
StringBuilder sb = new StringBuilder(highLevel); // 优化:预设容量避免扩容
for (int i = 0; i < highLevel; i++) {
sb.append("a");
}
String result = sb.toString(); // 最后生成一次 String
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
性能差异巨大: method2 比 method1 快几个数量级。
# 5. intern() 方法详解
intern() 是 String 类的一个 native 方法,其核心作用是规范化字符串表示,确保内容相同的字符串在内存中只有一份(在字符串常量池中)。
public native String intern();
工作机制:
当调用一个 String 对象(假设为 str)的 intern() 方法时:
- JVM 会检查字符串常量池中是否已经存在一个内容与
str相等(通过equals()判断)的字符串。 - 如果池中已存在: 直接返回池中那个字符串对象的引用。
- 如果池中不存在:
- JDK 6 及之前: 会将
str对象的内容复制一份,在永久代的字符串常量池中创建一个新的String对象,并返回这个新创建的池中对象的引用。 - JDK 7 及之后:
- 首先,不会立即在池中创建新对象。
- 它会检查Java 堆中是否存在一个内容与
str相等的String对象(这个检查主要是针对new String("literal")这种场景,字面量可能已经在堆中有一个实例)。 - 如果堆中存在一个等值的对象(假设为
heapObj),则将heapObj的引用添加到字符串常量池的内部哈希表中,然后返回这个指向堆对象的引用 (heapObj)。注意,此时常量池存的是指向堆对象的引用,而不是复制对象本身到常量池(堆区域)。 - 如果堆中也不存在等值的对象(例如
str是通过StringBuilder.toString()生成的,且其内容从未作为字面量出现过),则在字符串常量池(位于堆中) 中创建一个新的String对象(其内容与str相同),并返回这个新创建的池中对象的引用。
- JDK 6 及之前: 会将
关键区别总结:
- JDK 6: 不存在则复制内容到永久代的常量池,返回新池对象引用。
- JDK 7+: 不存在则先看堆中有无等值对象,有则将堆对象引用放入池表,返回堆对象引用;若堆中也无,则在堆的常量池区域创建新池对象,返回新池对象引用。核心变化是优先复用堆中已存在的对象引用。
示例:new String("kele") 的过程
String s1 = new String("kele");
- JVM 看到字面量
"kele",检查字符串常量池。 - 假设池中没有
"kele":- 在常量池中创建
"kele"对象。 - 在堆中
new一个String对象,其value指向(或复制)常量池"kele"的内容。
- 在常量池中创建
- 假设池中已有
"kele":- 直接在堆中
new一个String对象,其value指向(或复制)常量池"kele"的内容。
- 直接在堆中
- 最终,
s1变量持有的是堆中新创建的String对象的引用。
示例:intern() 的使用与理解
String myInfo = new String("I love kele").intern();
// 1. new String("I love kele"):
// - 检查常量池,假设没有 "I love kele",则在常量池创建 "I love kele"。
// - 在堆中创建 new String 对象,内容为 "I love kele"。
// 2. .intern():
// - 检查常量池,发现刚刚创建了 "I love kele"。
// - 返回常量池中 "I love kele" 的引用。
// 3. myInfo = ...: myInfo 指向常量池中的 "I love kele"。
// "I love kele" 字面量本身也指向常量池中的同一个对象。
System.out.println(myInfo == "I love kele"); // true
2
3
4
5
6
7
8
9
10
11
另一个经典例子 (StringIntern.java)
// 文件名: StringIntern.java
public class StringIntern {
public static void main(String[] args) {
// 场景1: "1" 字面量在类加载时已放入常量池
String s = new String("1"); // s 指向堆对象,常量池已有 "1"
String s_pool_1 = s.intern(); // intern() 发现池中有 "1",返回池中引用
String s2 = "1"; // s2 指向常量池中的 "1"
System.out.println("s == s2: " + (s == s2)); // false (堆 vs 常量池) - 对 JDK 6/7/8 都一样
System.out.println("s_pool_1 == s2: " + (s_pool_1 == s2)); // true (都是常量池引用)
System.out.println("---");
// 场景2: "11" 在拼接前常量池中不存在
String s3 = new String("1") + new String("1"); // s3 指向堆中新创建的 "11" 对象 (通过 StringBuilder)
// 此时常量池还没有 "11"
// 调用 intern() 将 "11" 放入常量池
String s3_pool_11 = s3.intern();
/*
* JDK 6: 常量池(永久代)没有 "11",将 s3 的内容复制一份,创建新的 "11" 对象在常量池,s3_pool_11 指向它。
* JDK 7/8: 常量池(堆)没有 "11",将 s3(堆对象)的引用放入常量池表,s3_pool_11 指向 s3。
*/
String s4 = "11"; // s4 查找常量池
/*
* JDK 6: 池中已有 s3.intern() 创建的 "11",s4 指向它。
* JDK 7/8: 池表中已有指向 s3 的引用,s4 得到这个引用,也指向 s3。
*/
System.out.println("s3 == s4 (JDK 6): false"); // JDK 6: s3(堆) vs s4(常量池新对象) -> false
System.out.println("s3 == s4 (JDK 7/8): true"); // JDK 7/8: s3(堆) vs s4(指向s3的池引用) -> true
System.out.println("s3_pool_11 == s4: " + (s3_pool_11 == s4)); // true (在各自 JDK 版本下,它们都指向池中的表示)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
图解 JDK 7/8 场景 2:
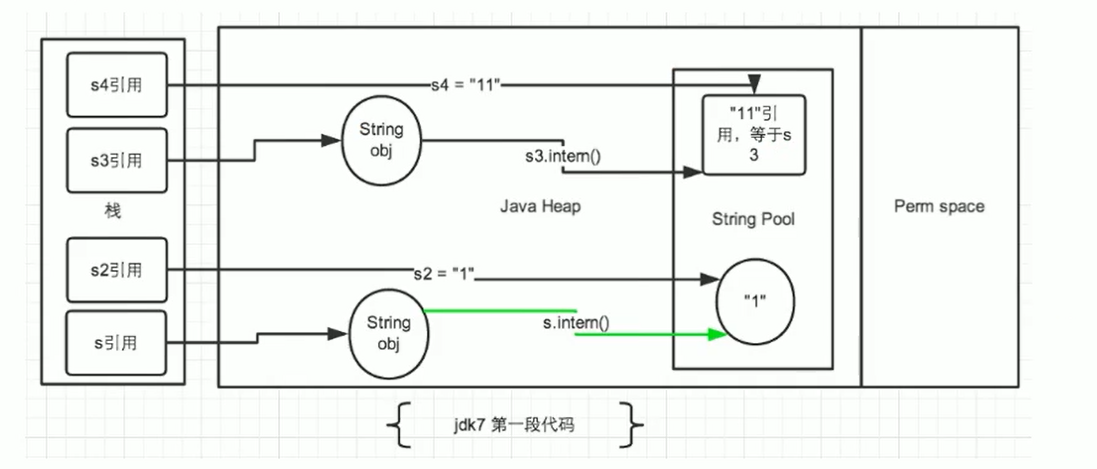
扩展题 (StringIntern1.java): 调换 s4 = "11" 和 s3.intern() 的顺序
// 文件名: StringIntern1.java
public class StringIntern1 {
public static void main(String[] args) {
String s3 = new String("1") + new String("1"); // s3 指向堆中 "11"
// 先执行这行:查找常量池,没有 "11",于是在常量池创建 "11" 对象,s4 指向它。
String s4 = "11";
// 再执行 intern():查找常量池,发现 s4 对应的 "11" 已存在。
String s5 = s3.intern(); // s5 指向常量池中的 "11" (即 s4 指向的对象)
System.out.println("s3 == s4: " + (s3 == s4)); // false (s3 堆 vs s4 常量池)
System.out.println("s5 == s4: " + (s5 == s4)); // true (s5 和 s4 都指向常量池的 "11")
System.out.println("s5 == s3: " + (s5 == s3)); // false (s5 常量池 vs s3 堆)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
练习题分析:
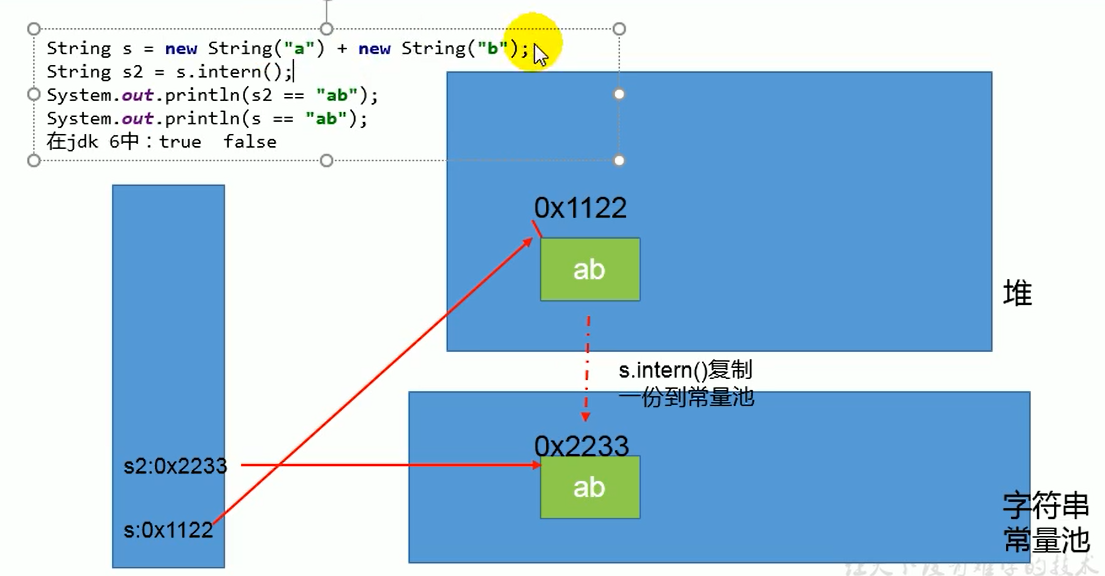
练习 1 (
StringExer1- 无String x = "ab";):String s = new String("a") + new String("b"); // s 指向堆 "ab",池无 "ab" String s2 = s.intern(); // JDK 6: 复制到池,s2 指池; JDK 7/8: 引用 s 放入池表,s2 指 s System.out.println(s2 == "ab"); // "ab" 字面量在比较时查找/创建常量池对象。 // JDK 6: s2(池新对象) == "ab"(池新对象) -> true // JDK 7/8: s2(指向s) == "ab"(池新对象) -> false (这里需要再确认,"ab"字面量应该是指向池里的,如果s2指向s,那应该false) // 重新思考:s2 == "ab" 比较。 "ab" 字面量在比较时,会查找常量池。 // JDK 6: s2是池中新创建的"ab", "ab"字面量也指向池中这个对象,所以 true。 // JDK 7/8: s2指向堆中的s。"ab"字面量查找常量池,发现没有,创建"ab"在池中。所以 s2(指向s) == "ab"(池中新对象) -> false。 System.out.println(s == "ab"); // JDK 6: s(堆) == "ab"(池新对象) -> false // JDK 7/8: s(堆) == "ab"(池新对象) -> false1
2
3
4
5
6
7
8
9
10图解 JDK 6:
 图解 JDK 7/8:
图解 JDK 7/8: 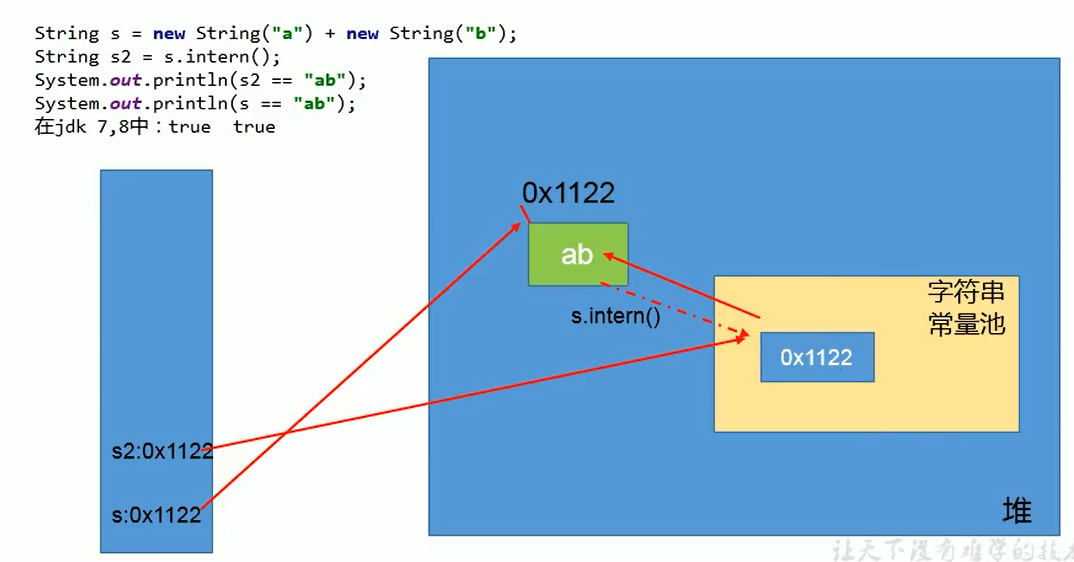 (注:原文档对 JDK 7/8 的
(注:原文档对 JDK 7/8 的 s2 == "ab"结果标记为 true 似有误,根据机制应为 false。s == "ab"结果标记为 true 也有误,应为 false。可能是笔误或基于特定 JVM 实现的观察?但理论分析倾向于 false。) 让我们坚持理论分析:s指向堆,"ab"指向池,s2在 JDK6 指向池中副本,在 JDK7+ 指向堆中s。所以s2 == "ab"在 JDK6 中为 true,JDK7+ 中为 false。s == "ab"始终为 false。练习 2 (
StringExer1- 有String x = "ab";):String x = "ab"; // 常量池已有 "ab", x 指向它 String s = new String("a") + new String("b"); // s 指向堆 "ab" String s2 = s.intern(); // 查找常量池,发现 x 对应的 "ab" 已存在,返回池中引用 (即 x) System.out.println(s2 == x); // true (s2 和 x 都指向池中 "ab") - 对 JDK 6/7/8 都一样 System.out.println(s == x); // false (s 堆 vs x 常量池) - 对 JDK 6/7/8 都一样1
2
3
4
5图解:
 (这次结果分析与原文档一致)
(这次结果分析与原文档一致)练习 3 (
StringExer2):String s1 = new String("ab"); // s1 指向堆对象。同时确保常量池有 "ab"。 // 对比:// String s1 = new String("a") + new String("b"); // s1 指向堆对象。常量池此时没有 "ab"。 s1.intern(); // 查找常量池,发现 "ab" 已存在,返回池中引用(但 s1 变量本身没变,仍然指向堆) String s2 = "ab"; // s2 指向常量池中的 "ab" System.out.println(s1 == s2); // false (s1 堆 vs s2 常量池) // 如果用注释掉的第二种方式创建 s1: // String s1 = new String("a") + new String("b"); // s1 指堆,池无 "ab" // s1.intern(); // JDK 6: 复制到池; JDK 7/8: 引用 s1 放入池表 // String s2 = "ab"; // JDK 6: 指向池中新对象; JDK 7/8: 指向池中新对象 // System.out.println(s1 == s2); // JDK 6: false; JDK 7/8: true (因为 s2 会找到池表中指向 s1 的引用)1
2
3
4
5
6
7
8
9
10
11
12
intern() 总结 (再强调):
- JDK 6: 池无则复制内容创建新对象入池(永久代),返回池对象引用。
- JDK 7+: 池无则先查堆,堆有等值对象则将堆对象引用入池表,返回堆对象引用;堆也无则在池(堆区域)创建新池对象,返回新池对象引用。
# 7. intern() 的效率测试 (空间角度)
intern() 的主要价值在于通过复用字符串对象来节省内存空间,尤其是在处理大量重复字符串的场景下。
测试代码 (StringIntern2.java):
// 文件名: StringIntern2.java
import java.util.ArrayList;
import java.util.List;
/**
* 测试 intern() 对内存空间使用的影响
*/
public class StringIntern2 {
static final int MAX_COUNT = 1000 * 10000; // 一千万次
// 使用 List<String> 代替数组,更灵活,避免 OOM 时无法观察
static final List<String> list = new ArrayList<>(MAX_COUNT / 10); // 预设容量减少扩容
public static void main(String[] args) {
// 模拟有限的几种字符串重复出现
Integer[] data = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
long start = System.currentTimeMillis();
for (int i = 0; i < MAX_COUNT; i++) {
String str = new String(String.valueOf(data[i % data.length]));
// 选择下面两种方式之一进行测试:
// 方式一:不使用 intern,每次都持有堆中的新对象
// list.add(str);
// 方式二:使用 intern,持有常量池中的对象引用
list.add(str.intern());
}
long end = System.currentTimeMillis();
System.out.println("添加 " + MAX_COUNT + " 个字符串到 List 花费时间:" + (end - start) + "ms");
System.out.println("List size: " + list.size());
System.out.println("程序将休眠,请使用内存分析工具观察堆内存...");
// 保持运行以便使用 JVisualVM 等工具分析内存
try {
Thread.sleep(Long.MAX_VALUE); // 无限期休眠
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
e.printStackTrace();
}
// System.gc(); // 手动 GC 仅供参考,不保证效果
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
运行与观察 (使用 JVisualVM 或类似工具分析堆内存):
- 方式一 (不使用
intern()):- 代码:
list.add(str); - 观察结果:堆内存占用会非常高。因为
list中持有了MAX_COUNT个不同的String对象(即使它们的内容只有 10 种重复),这些对象都在堆上,无法被 GC 回收。
- 代码:
- 方式二 (使用
intern()):- 代码:
list.add(str.intern()); - 观察结果:堆内存占用会显著降低。因为
intern()返回的是字符串常量池中的对象引用。list中虽然有一千万个引用,但它们实际上只指向常量池中那 10 个不同的字符串对象 ("1" 到 "10")。而每次循环中new String(...)创建的临时堆对象,因为没有被list直接引用(list引用的是intern()返回的池对象),很快就变得不可达,可以被 GC 回收。
- 代码:
结论:
对于程序中存在大量重复字符串的场景,使用 intern() 可以极大地节省内存空间。代价是 intern() 本身有一定的性能开销(查找哈希表),需要权衡。大型网站、社交平台等存储大量用户信息的场景,对地名、标签等重复率高的字符串使用 intern() 可能带来显著的内存优化效果。
# 8. 字符串创建方式回顾
总结创建 String 对象的三种主要方式及其内存影响:
直接赋值 (字面量
""):- 对象在字符串常量池中创建(如果池中尚无)。
- 变量持有常量池对象的引用。
- 效率高,推荐用于常量字符串。
String s = "aaa"; // s 指向常量池1new String(...):- 总是在堆内存中创建新的
String对象实例。 - 如果参数是字面量,会确保该字面量存在于常量池中。
- 变量持有堆对象的引用。
String s1 = new String("aaa"); // s1 指向堆,常量池也有 "aaa"1- 总是在堆内存中创建新的
intern()方法:- 作用于一个
String对象(通常是堆对象)。 - 查找常量池,返回池中等值对象的引用(如果池中没有,则根据 JDK 版本将对象或引用放入池中再返回)。
- 用于将堆对象规范化到常量池引用。
String s1 = new String("aaa"); String s2 = s1.intern(); // s2 指向常量池中的 "aaa" System.out.println(s1 == s2); // false1
2
3- 作用于一个
# 9. StringTable 的垃圾回收
字符串常量池中的 String 对象是可以被垃圾回收的。
回收条件: 当一个存在于字符串常量池中的 String 对象,不再被任何活动的 GC Root(如栈帧中的局部变量、静态变量、JNI 引用等)直接或间接引用时,它就满足了被回收的条件。
验证:
// 文件名: StringGCTest.java
/**
* 演示 StringTable 的垃圾回收
* VM Options: -Xms15m -Xmx15m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails
*/
public class StringGCTest {
public static void main(String[] args) {
// 循环创建大量字符串并 intern,但循环结束后这些字符串不再被引用
for (int i = 0; i < 100000; i++) {
// String.valueOf(i).intern() 会将 "0", "1", ... 等放入常量池
// 但循环变量 i 结束后,这些引用就丢失了
String temp = String.valueOf(i).intern();
// 注意:如果没有地方持有 temp 的引用,GC 可能回收常量池中的字符串
}
System.out.println("循环结束,尝试触发 GC...");
// 建议 GC (不保证执行,但有助于观察)
System.gc();
// 保持运行以便观察统计信息
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("程序结束。");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
运行并观察输出 (使用 -XX:+PrintStringTableStatistics 和 -XX:+PrintGCDetails):
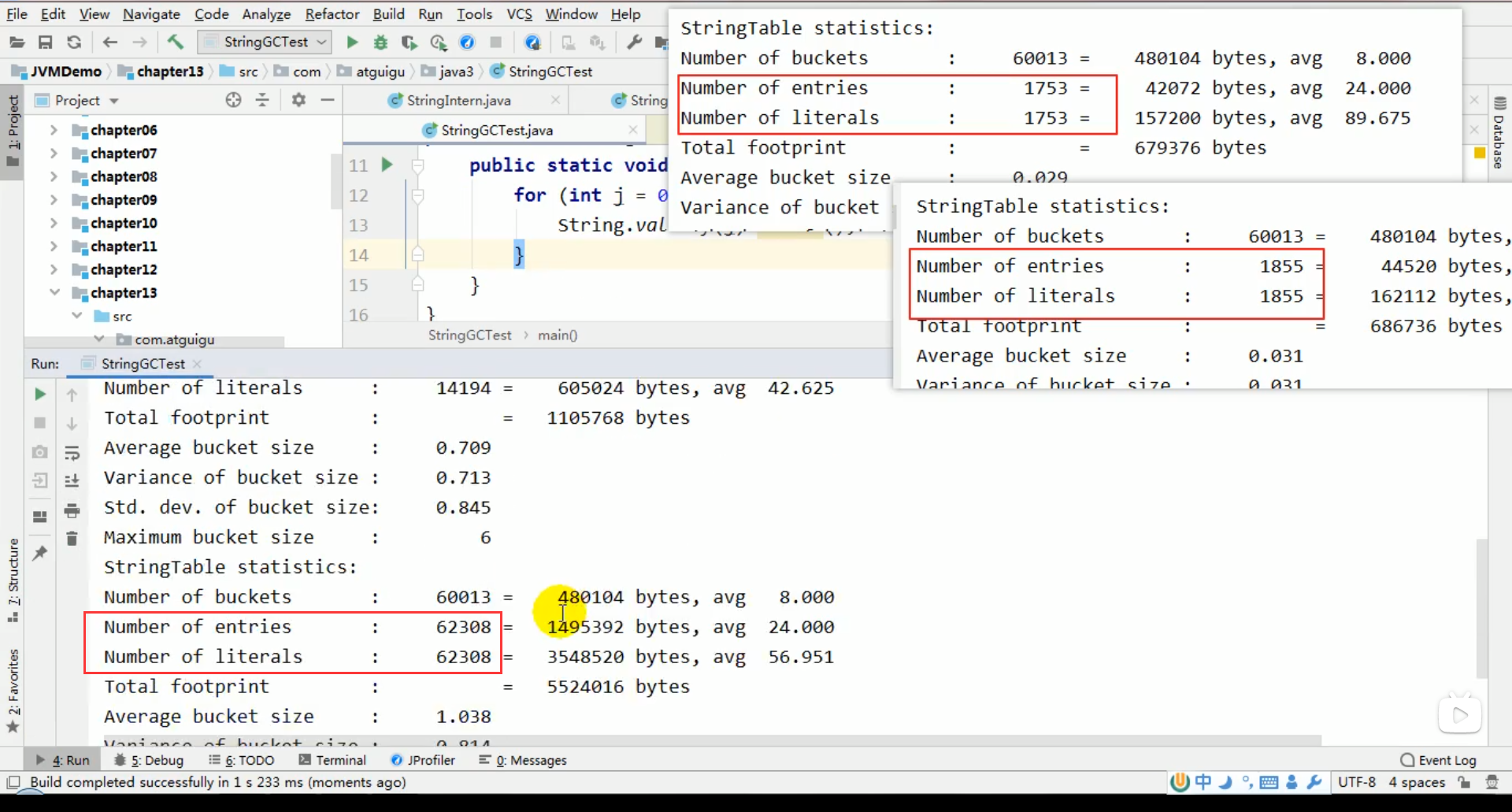
- 观察点 1: GC 日志(
PrintGCDetails)会显示发生了 GC(可能是 Young GC 或 Full GC)。 - 观察点 2: StringTable 统计信息(
PrintStringTableStatistics)会在 JVM 退出时打印。其中的Number of entries(条目数)通常会远小于循环次数(100000)。这表明在程序运行过程中或退出前的 GC 中,常量池里不再被引用的字符串被成功回收了。
# 10. G1 垃圾收集器中的 String 去重操作
背景: 根据对大量 Java 应用的分析,发现:
- Java 堆中存活对象约 25% 是
String对象。 - 其中约 13.5% 的
String对象是重复的(即s1.equals(s2)为 true,但s1 != s2)。这些重复对象主要由new String(...)、substring()、StringBuilder.toString()等操作产生在堆上,而非通过字面量或intern()进入常量池。 - 这种堆上的字符串重复造成了显著的内存浪费。
G1 String Deduplication 功能 (JEP 192, 约 Java 8u20 引入):
- 目标: 在 G1 垃圾收集过程中,自动识别并消除堆上重复的
String对象,共享底层的char[]或byte[]数组,从而节省内存。 - 注意: 这是针对堆中重复的
String实例,不是针对字符串常量池(常量池本身保证唯一性)。
实现机制:
- 候选对象识别: 在 GC 过程中(并发标记阶段),G1 会检查存活的
String对象。如果一个String对象达到了一定的“年龄”(即在 GC 中存活了足够次数,由StringDeduplicationAgeThreshold控制),它就被视为去重的候选对象。 - 排队等待处理: 将候选
String对象的引用放入一个内部队列。 - 后台线程处理: 一个专门的后台线程(String Deduplication Thread)处理这个队列。
- 查找共享数组: 对于队列中的每个
String对象,线程会计算其底层value数组的哈希值,并查询一个全局的弱引用哈希表 (WeakHashMap-like structure),看是否存在一个内容完全相同的value数组已经被其他String对象共享。 - 去重或记录:
- 如果找到共享数组: 则将当前
String对象的value引用指向那个已存在的共享数组。原来的value数组如果没有其他引用,就会在后续 GC 中被回收。 - 如果未找到: 则将当前
String对象的value数组(或其引用)放入全局哈希表中,供后续的String对象共享。
- 如果找到共享数组: 则将当前
- 效果: 多个内容相同的
String对象最终会共享同一个底层的byte[]或char[]数组,减少了内存占用。
相关 JVM 参数:
-XX:+UseStringDeduplication:开启 G1 字符串去重功能(默认关闭)。需要配合 G1 收集器 (-XX:+UseG1GC) 使用。-XX:+PrintStringDeduplicationStatistics:打印详细的去重统计信息(如去重了多少对象、节省了多少内存等)。-XX:StringDeduplicationAgeThreshold=<age>:设置String对象需要达到哪个 GC 年龄才被视为去重候选对象(默认值通常是 3)。
使用建议: 如果你的应用使用 G1 收集器,并且内存分析显示存在大量重复的 String 对象占用了较多堆内存,可以考虑开启此功能以优化内存使用。但需要注意,去重过程本身也有一定的 CPU 开销。