 Map接口
Map接口
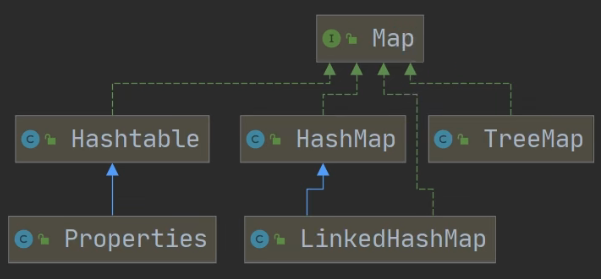
Map为双列集合,Set集合的底层也是Map,只不过有一列是常量所占,只使用到了一列。
# 1. Map 接口实现类的特点
- Map 存放数据的 key - value 示意图,一对 k - v 是放在一个 HashMap$Node 中的,又因为 Node 实现了 Entry 接口,所以也可以说,一对 k - v 就是一个 Entry ;
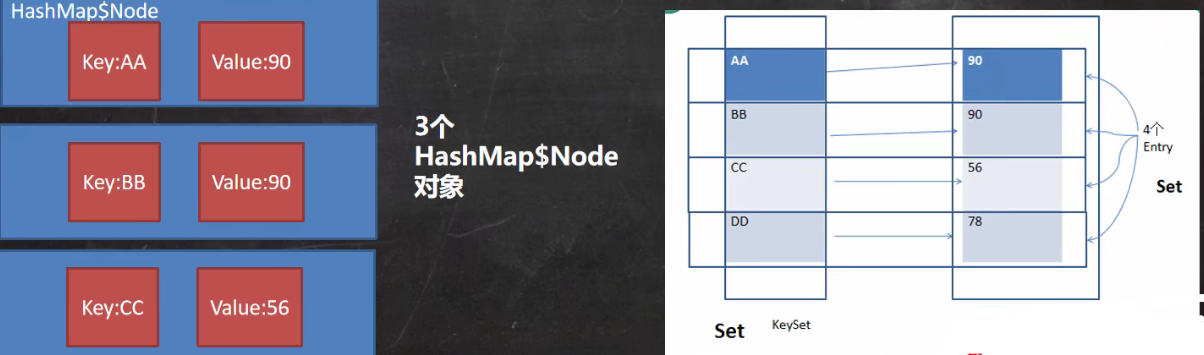
- Map 与 Collection 并列存在,用于保存具有映射关系的数据:Key - Value;
- Map 中的 Key 和 Value 可以是任何引用类型的数据,会封装到 HashMap$Node对象中;
- Map中的 Key 不允许重复,原因和 HashSet 一样;
- Map 中的 Value 可以重复;
- Map 的 Key 可以为 null,value 也可以为 null,但 key 为 null 只能有一个;
- 常用 String 类作为 Map 的 key,当然,其他类型也可以,但不常用;
- Key 和 Value 之间存在单向一对一关系,即通过指定的 Key 总能找到对应的 Value;
import java.util.HashMap;
import java.util.Map;
public class Map_ {
//分析Map接口实现类的特点
public static void main(String[] args){
//1. Map 与 Collection 并列存在,用于保存具有映射关系的数据:Key - Value;
Map map = new HashMap();
map.put("No.1","我");//Key-Value
map.put("No.2","你");// K-V
map.put("No.3","他");// K-V
System.out.println(map);//{No.2=你, No.1=我, No.3=他}
//2. Map 中的 Key 和 Value 可以是任何引用类型的数据,会封装到 HashMap$Node对象中
//3. Map中的 Key 不允许重复,原因和HashSet一样
//4.Map 中的 Value 可以重复
map.put("No.2","X"); //替换机制
map.put("No.4","他");
System.out.println(map);//{No.2=X, No.1=我, No.4=他, No.3=他}
//5. Map 的 Key 可以为 null,value 也可以为 null,但 key 为 null 只能有一个;
map.put("null","1");
map.put("null","2");
map.put("No.2","null");
map.put("No.3","null");
System.out.println(map);//{No.2=null, No.1=我, No.4=他, No.3=null, null=2}
//6. 常用 String 类作为 Map 的 key,当然,其他类型也可以,但不常用;
//7. Key 和 Value 之间存在单向一对一关系,即通过指定的 Key 总能找到对应的 Value;
//通过get方法,传入key,会返回对应的value
System.out.println(map.get("No.1"));//我
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 2. Map 接口和常用方法
| 方法 | 解释 |
|---|---|
| V get (Object key) | 返回 key 对应的 value |
| V getOrDefault (Object key, V defaultValue) | 返回 key 对应的 value , key 不存在,返回默认值 |
| V put (K key, V value) | 设置 key 对应的 value |
| V remove (Object key) | 删除 key 对应的映射关系 |
Set<K> keySet () | 返回所有 key 的不重复集合 |
Collection<V> values () | 返回所有 value 的可重复集合 |
Set<Map.Entry<K, V>> entrySet () | 返回所有的 key-value 映射关系 |
| boolean containsKey (Object key) | 判断是否包含 key |
| boolean containsValue (Object value) | 判断是否包含 value |
| boolean isEmpty() | 判断映射是否为空 |
| int size() | 获取映射中元素的数量 |
| void clear() | 清空映射 |
- Map 是一个接口,不能直接实例化对象 ,如果 要实例化对象只能实例化其实现类 TreeMap 或者 HashMap。
- Map 中存放键值对的 Key 是唯一的, value 是可以重复的(重复的情况,后面put的覆盖前面的)。
- Map 中的 Key 可以全部分离出来,存储到 Set 中 来进行访问 ( 因为 Key 不能重复 ) 。
- Map 中的 value 可以全部分离出来,存储在 Collection 的任何一个子集合中 (value 可能有重复 ) 。
- Map 中键值对的 Key 不能直接修改, value 可以修改,如果要修改 key ,只能先将该 key 删除掉,然后再来进行重新插入。
其中 Set<Map.Entry<K, V>> entry Set() 这个方法非常复杂但也非常重要,所以要做一些具体的说明:
Map.Entry<K, V> 是 Map 内部实现的用来存放 <key, value> 键值对映射关系的内部类 ,该内部类中主要提供了 <key, value> 的获取, value 的设置以及 Key 的比较方式。
如何理解?通俗来说就是:
Entry是Map里面的一个内部类,而 Map.Entry<key,val> 的作用就是把一个个map元素(key,val) 打包成一个整体,而这个整体的类型就是 Map.Entry<K,V>, 然后我们有一个Set集合,它里面存放的每个元素的类型就是 Map.Entry<K,V>。这里可以联想到我们的单链表的内部类ListNode,将 val,next 打包成一个整体,那么它的类型就是ListNode。

所以下面这段代码运行起来一定会把Set集合中存放的map中的每一个元素都输出出来:
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("hello",2);
map.put("world",1);
map.put("bit",3);
Set<Map.Entry<String, Integer>> entrySet = map.entrySet();
for (Map.Entry<String,Integer> entry:entrySet) {
System.out.println("key: "+entry.getKey()+" val: "+entry.getValue());
}
}
2
3
4
5
6
7
8
9
10
该内部类Entry提供的一些方法也是比较重要的:
| 方法 | 解释 |
|---|---|
| K getKey () | 返回 entry 中的 key |
| V getValue () | 返回 entry 中的 value |
| V setValue(V value) | 将键值对中的 value 替换为指定 value |
下面是一下常用方法示例:
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class MapMethodExamples {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
// put:添加元素
map.put("apple", 10); // 添加苹果的价格
map.put("banana", 20); // 添加香蕉的价格
// get:根据键获取值
System.out.println("apple的价格:" + map.get("apple")); // 获取苹果的价格
// getOrDefault:获取键对应的值,如果键不存在,返回默认值
System.out.println("orange的价格(默认值5):" + map.getOrDefault("orange", 5)); // 获取橘子的价格,如果不存在,则为默认值5
// remove:根据键删除映射关系
map.remove("banana"); // 删除香蕉的价格
System.out.println("删除banana后的map:" + map);
// keySet:获取所有键的集合
Set<String> keys = map.keySet();
System.out.println("map中的所有键:" + keys);
// values:获取所有值的集合
System.out.println("map中的所有值:" + map.values());
// entrySet:获取所有键值对的集合
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry.getKey() + " => " + entry.getValue());
}
// containsKey:判断是否包含指定的键
System.out.println("是否包含apple:" + map.containsKey("apple"));
// containsValue:判断是否包含指定的值
System.out.println("是否有价格为10的商品:" + map.containsValue(10));
// isEmpty:判断映射是否为空
System.out.println("map是否为空:" + map.isEmpty());
// size:获取映射中元素的数量
System.out.println("map的大小:" + map.size());
// putAll:将另一个映射的所有映射关系复制到此映射中
Map<String, Integer> anotherMap = new HashMap<>();
anotherMap.put("cherry", 30);
map.putAll(anotherMap);
System.out.println("合并后的map:" + map);
// clear:清空映射
map.clear();
System.out.println("清空后的map:" + map);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
# 3. Map的七种遍历方式
- containsKey : 查找键是否存在
- keySet : 获取所有的键
- entrySet :获取所有关系
- values : 获取所有的值
import java.util.*;
public class MapFor {
public static void main(String[] args) {
// 创建一个HashMap实例
Map<String, String> map = new HashMap<>();
map.put("海绵宝宝", "派大星");
map.put("熊大", "熊二");
map.put("大头儿子", "小头爸爸");
map.put("黑猫警长", null);
map.put(null, "奥特曼");
// 第一种遍历方式:通过keySet遍历
System.out.println("----通过keySet遍历----");
for (String key : map.keySet()) {
System.out.println("键:" + key + ",值:" + map.get(key));
}
// 第二种遍历方式:通过values遍历所有值
System.out.println("----通过values遍历所有值----");
for (String value : map.values()) {
System.out.println("值:" + value);
}
// 第三种遍历方式:通过entrySet遍历所有键值对
System.out.println("----通过entrySet遍历所有键值对----");
for (Map.Entry<String, String> entry : map.entrySet()) {
System.out.println("键:" + entry.getKey() + ",值:" + entry.getValue());
}
// 第四种遍历方式:使用迭代器遍历keySet
System.out.println("----使用迭代器遍历keySet----");
Iterator<String> keyIterator = map.keySet().iterator();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
System.out.println("键:" + key + ",值:" + map.get(key));
}
// 第五种遍历方式:使用迭代器遍历values
System.out.println("----使用迭代器遍历values----");
Iterator<String> valueIterator = map.values().iterator();
while (valueIterator.hasNext()) {
System.out.println("值:" + valueIterator.next());
}
// 第六种遍历方式:使用迭代器遍历entrySet
System.out.println("----使用迭代器遍历entrySet----");
Iterator<Map.Entry<String, String>> entryIterator = map.entrySet().iterator();
while (entryIterator.hasNext()) {
Map.Entry<String, String> entry = entryIterator.next();
System.out.println("键:" + entry.getKey() + ",值:" + entry.getValue());
}
// 第七种遍历方式:Java 8 forEach方法遍历
System.out.println("----Java 8 forEach方法遍历----");
map.forEach((key, value) -> System.out.println("键:" + key + ",值:" + value));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
# 4. HashMap 底层&扩容机制
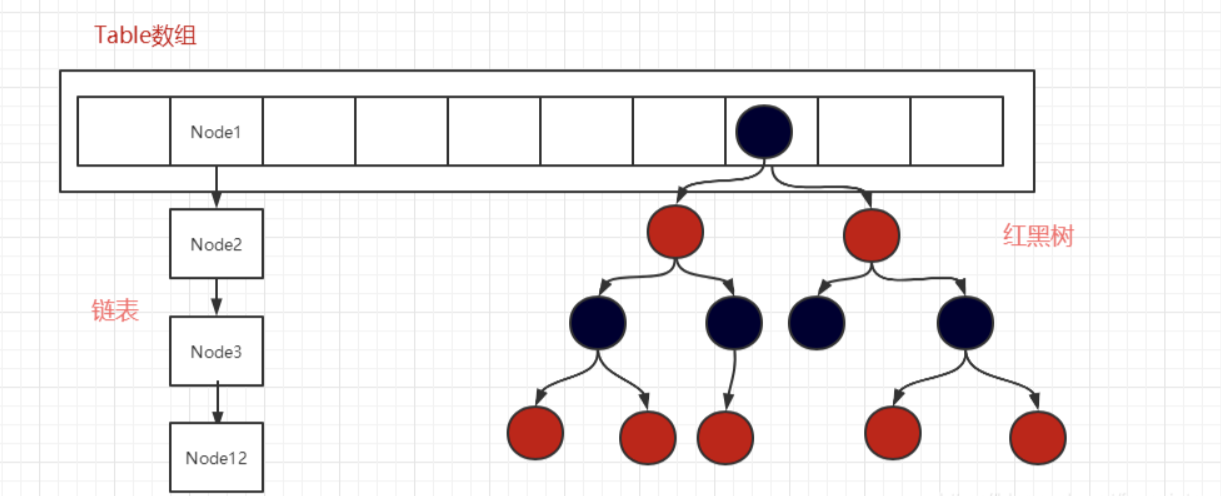
- HashMap 底层维护了 Node 类型的数组 table ,默认为 null;
- 当创建对象时,将负载因子(loadfactor)初始化为0.75;
- 当添加 key-value 时,通过 key 的哈希值得到在 table的索引,然后判断该索引处是否有元素,如果没有元素则直接添加。如果该索引处有元素,继续判断该元素的 key 是否和准备加入的 key 相等,如果相等,则直接替换 value;如果不相等,则需要判断是树结构还是链表结构,做出相应处理。如果添加时发现容量不够,则需要扩容。(扩容机制和HashSet完全一样,因为HashSet底层就是HashMap)
- 第一次添加,会扩容 table 容量为16,临界值(threshold)为12(
临界值 = 数组的长度 * 负载因子); - 以后再扩容,会扩容 table 容量为原来的2倍,临界值为原来的2倍,即24,以此类推;
- 在Java8中,如果一条链表的元素个数超过 TREEIFY_THRESHOLD(默认是8),并且 table的大小>= MIN_CAPACITY(默认是64),就会进行树化(红黑树);
哈希表底层部分成员属性的分析: 
put操作所对应的实现流程如下图所示: 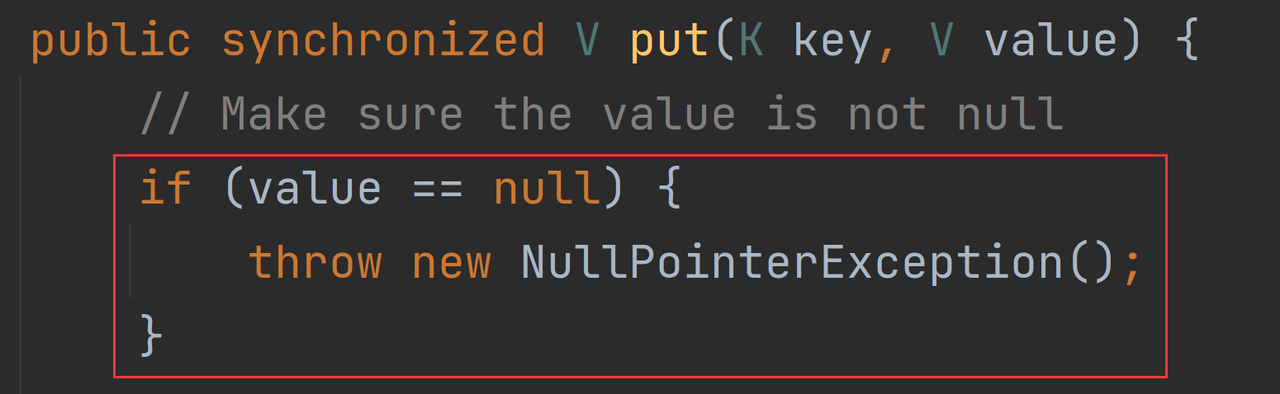
初始化和扩容的具体流程如下: 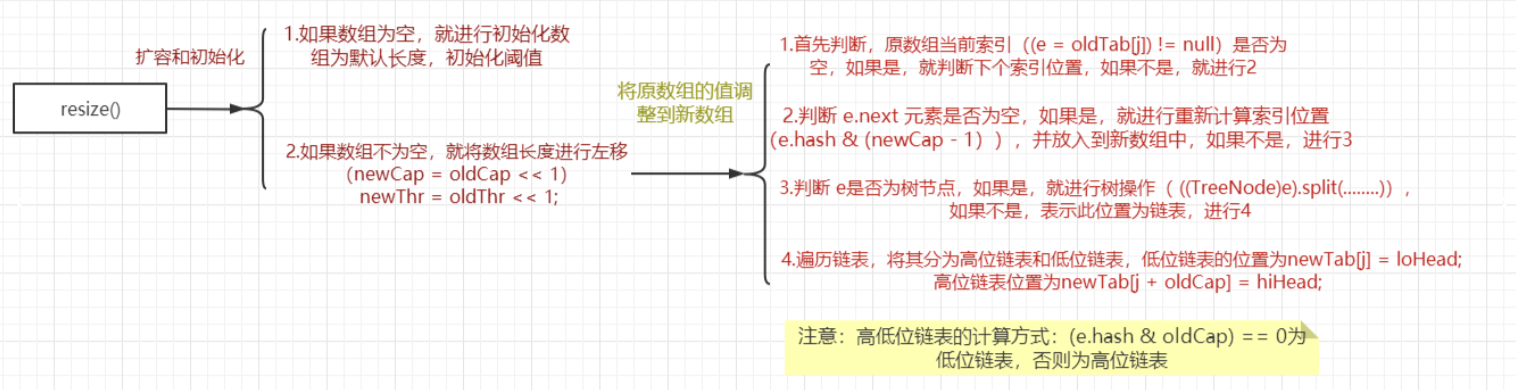
面试问题:以下两个桶的数组容量分别是多大?
HashMap<String,Integer> map = new HashMap<>(19); // 桶1答案是32
HashMap<String,Integer> map = new HashMap<>(); // 桶2答案是0
2
刚刚我们分析了成员属性和成员方法,桶的只是定义了,并没有看见给桶开辟大小??那我们如何put 进去元素呢?
首先可以确定的是桶 2 的大小为 0,至于为什么没开辟空间也可以 put 元素,我们就需要分析底层的 put 函数,接下来我们带着疑惑继续分析源码
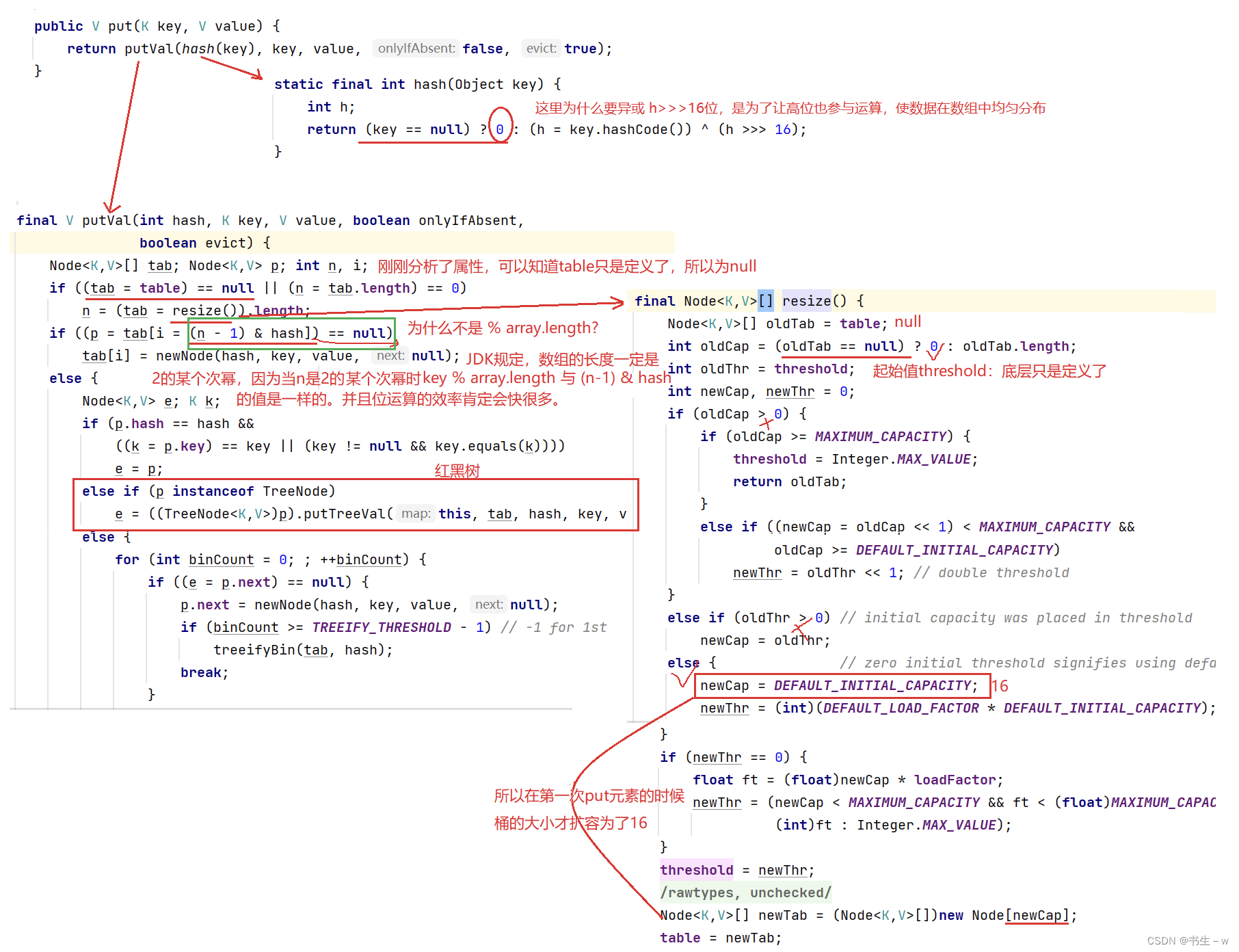
结论:
- 桶2的默认大小是0,但是在put进去第一个元素时,它的容量就扩容为了16.
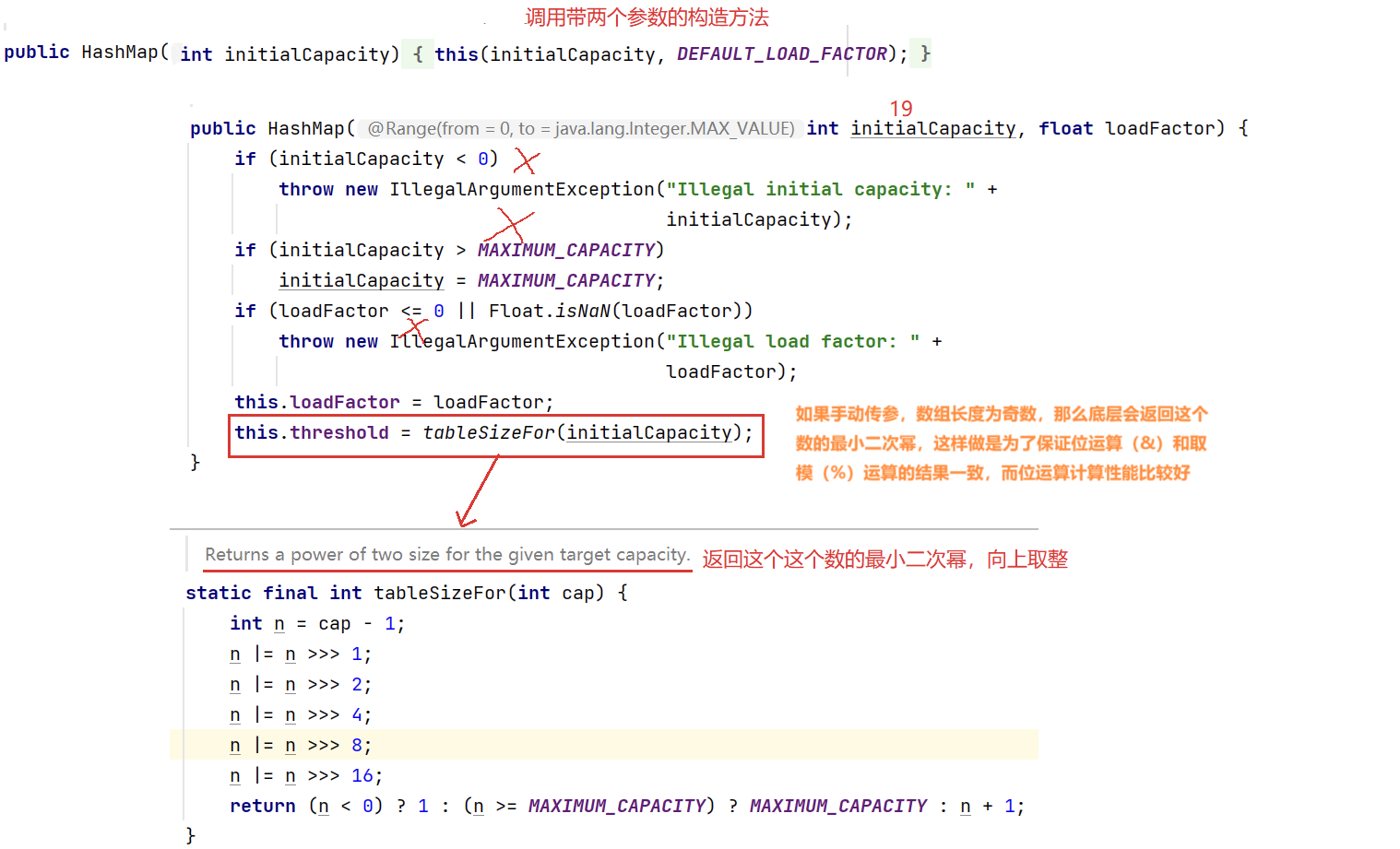
- 我们可以看到底层寻址的方式不是 hash % array.length,而是 (n-1) & hash,因为 JDK规定数组的长度必须是 2 的某个次幂。因为当 n 是 2 的某个次幂时,hash % array.length 与(n-1) & hash 得到的值是一样的,并且位运算的效率高。所以桶1的容量就不是19,而是2的某个次幂向上取整,所以桶1大小为32,我们可以继续看带一个参数的构造方法的源码:
# 5. HashMap 在多线程环境中的线程安全问题
- 并发修改异常: 当多个线程同时修改
HashMap时,比如一个线程在遍历HashMap,而另一个线程同时修改它(添加、删除或更新元素),这可能导致ConcurrentModificationException异常。 - 数据不一致性: 在多线程环境下,如果一个线程对
HashMap进行了修改,而这个修改没有被适当地同步,那么其他线程可能看不到这个修改。这意味着不同的线程可能看到HashMap的不同状态,从而导致数据不一致。 - 扩容问题:
HashMap在扩容时,需要重新计算存储元素的位置并将它们复制到新的更大的数组中。如果多个线程同时触发扩容,可能会导致数据丢失或覆盖,以及其他不可预见的问题。 - 数据覆盖: 如果两个线程尝试在相同的键上插入不同的值,可能会出现一个线程的插入操作覆盖另一个线程的操作,这可能导致某些更改被意外丢弃。
- 死锁的风险: 虽然比较少见,但在特定的情况下,尤其是在扩容操作期间,
HashMap的并发修改可能导致死锁。
为了避免这些问题,可以采取以下措施:
- 使用
ConcurrentHashMap:它是专门设计用于多线程环境的,提供更好的线程安全性能,同时保持较高的处理效率。 - 使用
Collections.synchronizedMap(new HashMap<...>()):它提供了基本的同步,但可能不如ConcurrentHashMap那样高效。 - 手动同步:在对
HashMap进行操作的关键部分添加同步块,这需要程序员对并发编程有一定的了解,能够正确地管理锁。
# 6. Hashtable
 Hashtable的基本介绍:
Hashtable的基本介绍:
- 存放的元素都是键值对,即 key - value;
- Hashtable 的键和值都不能为 null,否则会抛出NullPointerException
- Hashtable 使用方法基本上和 HashMap 一样;
- Hashtable 是线程安全的(synchronized), HashMap是线程不安全的;
Hashtable 不能存储 null 键和 null 值是因为,它的 key 值要进行哈希计算,如果为 null 的话,无法调用该方法,还是会抛出空指针异常。而 value 值为 null 的话,Hashtable 源码中会主动抛出空指针异常。
HashMap 允许 key 和 value 为 null 的原因是因为在 HashMap 中对 null 值进行了特殊处理,如果为 null 时会把它赋值为 0,如下源码所示:

Hashtabel table = new Hashtable();
table.put("John",100);//OK
table.put(null,100);//异常 NullPointerException
table.put("",null);//异常
table.put("John",128);//替换
Hashtable的底层原理:
1.底层有数组 Hashtables$Entry[] 初始化大小为1;
2.临界值 threshold 8 = 11 * 0.75;
3.扩容机制:执行方法 addEntry(hash,key,value,index);添加 K-V,封装到Entry;
4.当 if(count >= threshold) 满足就扩容;
5.按照 int newCapacity = (oldCapacity << 1)+1; 扩容
2
3
4
5
6
7
8
9
10
11
12
| 对比 | 线程安全(同步) | 效率 | 允许 null 键 null 值 |
|---|---|---|---|
| HashMap | 不安全 | 高 | 可以 |
| Hashtable | 安全 | 较低 | 不可以 |
# 7. HashTable的底层机制
Hashtable 是使用
synchronized来实现线程安全的,给整个哈希表加了一把大锁,多线程访问时候,只要有一个线程访问或操作该对象,那其他线程只能阻塞等待需要的锁被释放,在竞争激烈的多线程场景中性能就会非常差!
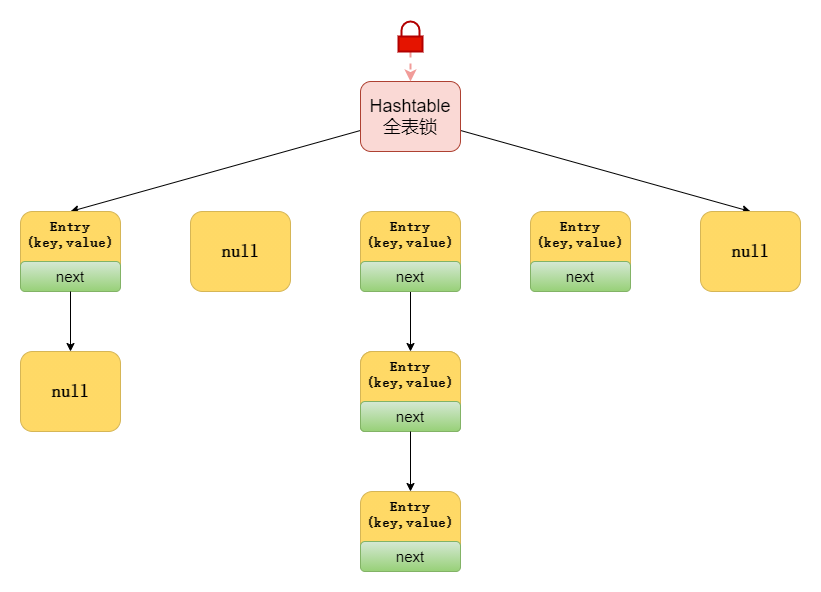
- HashTable 使用的数据结构是 数组 + 链表
- 因为HashTable无脑加锁的原因,现在Java官方已经不推荐使用HashTable了
- 不涉及线程安全问题时使用HashMap,如果要保证线程安全就使用ConcurrentHashMap
put和扩容操作所对应的实现流程如下图所示: 
# 8. HashMap 和 HashTable的区别
- 存储结构和解决冲突的方法:
- 它们的存储结构(数组+链表,1.8后HashMap加入了红黑树)和解决冲突的方法(链地址法)是相同的。
- 默认容量和容量要求:
HashTable的默认容量为 11,HashMap的默认容量为 16。HashTable不要求容量是 2 的幂,而HashMap要求容量必须是 2 的整数次幂。
- null 值:
HashMap允许 key 和 value 为 null(key 只能有一个 null,value 可以多个)。HashTable中 key 和 value 都不能为 null,否则会抛出NullPointerException。
- 扩容方式:
Hashtable扩容为原来容量的 2 倍加 1。HashMap扩容为原来的 2 倍。
- hash 值计算和索引位置确定:
Hashtable直接使用key.hashCode(),使用%运算来定位索引。HashMap重新计算 hash 值,使用&运算来定位索引。
# 9. TreeMap
TreeMap 构造器可以传入比较器,所以TreeMap常用来排序,可以自定义存放数据顺序。
import java.util.Comparator;
import java.util.TreeMap;
public class TreeMap_ {
public static void main(String[] args) {
TreeMap treeMap = new TreeMap();//默认构造器,默认比较:自然排序
treeMap.put("Jack","杰克");
treeMap.put("Tom","汤姆");
treeMap.put("Smith","史密斯");
System.out.println(treeMap);//{Jack=杰克, Smith=史密斯, Tom=汤姆}由小到大排序
//如果按照传入的key由大到小排序:
treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o2).compareTo((String)o1);
//如果是按照长度由大到小:return ((String)o1).length()-((String)o2).length();
}
});
treeMap.put("Jack","杰克");
treeMap.put("Tom","汤姆");
treeMap.put("Smith","史密斯");
System.out.println(treeMap);//{Tom=汤姆, Smith=史密斯, Jack=杰克} 由大到小排序
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 10. TreeMap 和 HashMap 的区别
| Map 底层结构 | TreeMap | HashMap |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入 / 删除 / 查找时间复杂度 | O(log2^N) | O(1) |
| 是否有序 | 关于key有序 | 无序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 需要进行元素比较 | 通过哈希函数计算哈希地址 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要 Key 有序场景下 | Key 是否有序不关心,需要更高的时间性能 |
# 11. Properties
- Properties 类继承自 Hashtable 类并且实现了Map接口,也是使用一种键值对的形式来保存数据;
- 使用特点和 Hashtable 相似;
- Properties 还可以用于从 xxx.properties 文件中,加载数据到Properties类对象,并进行读取和修改;
- 说明:xxx.properties 文件通常作为配置文件,这在 IO流 也有讲解