 Set接口
Set接口
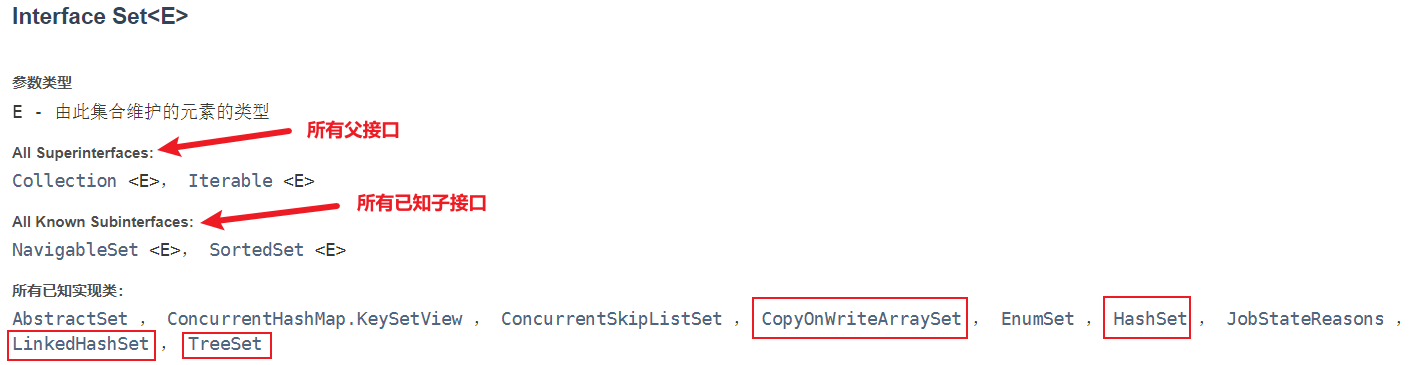
Set 接口介绍:
- 唯一性:不允许重复的元素。
- 无序性:不保证元素的存储顺序。
- 常用实现:包括
HashSet(无序,基于哈希表)、TreeSet(有序,基于红黑树)和LinkedHashSet(保持插入顺序,基于哈希表和链表)。 null值:大多数实现(如HashSet)允许一个null元素,但TreeSet不允许。
# 1. Set 接口和常用方法
Set 接口的常用方法
- 和 List 接口一样,Set 接口也是 Collection 的子接口,所以常用方法和Collection接口一样
| 方法 | 解释 |
|---|---|
| boolean add (E e) | 添加元素,但重复元素不会被添加成功 |
| void clear () | 清空集合 |
| boolean contains (Object o) | 判断 o 是否在集合中 |
Iterator<E> iterator () | 返回迭代器 |
| boolean remove (Object o) | 删除集合中的 o |
| int size() | 返回set 中元素的个数 |
| boolean isEmpty() | 检测 set 是否为空,空返回 true ,否则返回 false |
| Object[] toArray() | 将 set 中的元素转换为数组返回 |
| boolean containsAll(Collection<?> c) | 集合 c 中的元素是否在 set 中全部存在,是返回 true ,否则返回false |
| boolean addAll(Collection<? extendsE> c) | 将集合 c 中的元素添加到 set 中,可以达到去重的效果 |
Set 接口的遍历方式
- 同 Collection 的遍历一样:
- 迭代器遍历
- 增强 for
- 但 不能用索引 的方式来获取; (因为Set无序)
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
public class SetMethod {
public static void main(String[] args) {
//以Set接口的实现类 HashSet 来演示
//Set接口的实现类对象(Set接口对象),不能存放重复元素
//Set接口对象存放和读取数据无序
//取出的顺序虽然不是添加的顺序,但是,是固定有序的
Set set = new HashSet();
set.add("John");
set.add("Lucy");
set.add("Jack");
set.add(null);
set.add(null);
System.out.println(set);//[null, John, Lucy, Jack] 执行多遍都是这个结果
set.remove(null);//等常用方法可以依照Colleciotn常用方法,是一致的
//遍历:迭代器
Iterator iterator = set.iterator();
while(iterator.hasNext()){
Object o = iterator.next();
System.out.println(o);
}
//遍历:增强for (底层还是迭代器)
for(Object o:set){
System.out.println(o);
}
//不能索引遍历,且set接口对象没有get()方法
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 2. HashSet
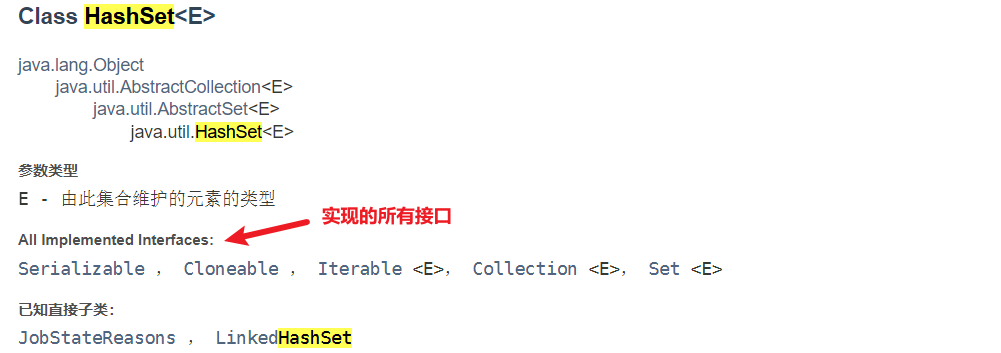
- HashSet实现了Set接口;
- HashSet实际上是HashMap,可以从源码看出;
- 可以存放 null 值,但是只能有一个null;
- HashSet 不保证元素是有序的,取决于hash后,再确定索引的结果;
- 不能有重复元素 / 对象;
import java.util.HashSet;
public class HashSetExample {
public static void main(String[] args) {
HashSet<String> hashSet = new HashSet<>();
// 添加元素到 HashSet
System.out.println(hashSet.add("john")); // 输出 true,因为 "john" 成功添加
System.out.println(hashSet.add("lucy")); // 输出 true,因为 "lucy" 成功添加
System.out.println(hashSet.add("john")); // 输出 false,因为 "john" 已存在,不能重复添加
System.out.println(hashSet.add("jack")); // 输出 true,因为 "jack" 成功添加
System.out.println(hashSet.add("rose")); // 输出 true,因为 "rose" 成功添加
// 删除元素
hashSet.remove("john"); // 删除 "john"
System.out.println("hashSet = " + hashSet); // 输出剩余元素
// 重置 HashSet 并测试添加重复元素
hashSet = new HashSet<>();
hashSet.add("lucy"); // 添加 "lucy"
hashSet.add("lucy"); // 尝试再次添加 "lucy",但不会成功因为已存在
// 添加字符串 "ok" (String类底层重写了hashCode 和 equals 方法,这使得两个相同内容的 String 对象是相等的)
String str1 = new String("ok");
String str2 = new String("ok");
hashSet.add(str1); // 添加 "ok"
hashSet.add(str2); // 尝试再次添加 "ok",但不会成功,即使是不同的对象
System.out.println("hashSet = " + hashSet); // 输出集合内容
// "坑"示例:添加自定义对象
// 如果 Dog 类没有覆写 hashCode 和 equals 方法,
// 则即使两个 Dog 对象有相同的 name,它们也会被视为不同的元素
// hashSet.add(new Dog("tom")); // 添加一个名为 "tom" 的 Dog 对象
// hashSet.add(new Dog("tom")); // 再添加一个名为 "tom" 的 Dog 对象
// System.out.println("hashSet = " + hashSet); // 输出结果会显示两个 Dog 对象
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# 3. HashSet 底层机制(HashMap)
HashSet 底层其实是HashMap,HashMap底层是(数组+链表+红黑树)
在JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的链表都存储在一个链表里。但是当一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。而JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。
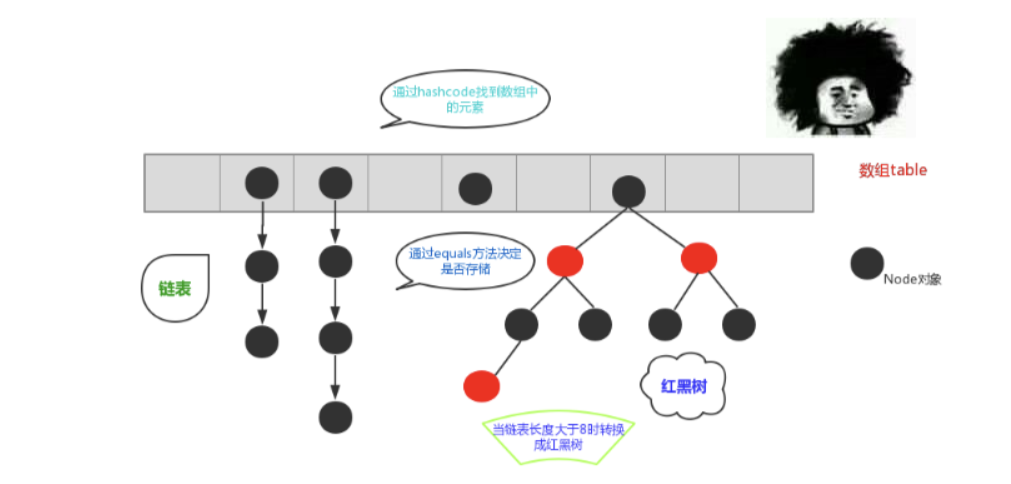
HashSet底层机制:
底层结构:
HashSet底层使用HashMap。在HashSet中添加元素实际上是向HashMap的key添加元素,而value使用的是一个固定的虚拟值。
元素添加过程:
- 当向
HashSet添加元素时,它首先计算元素的hashCode,然后将这个hashCode通过散列函数转换成数组索引。 - 接着,它检查底层
HashMap的数组(table)中该索引位置是否已经有元素。- 如果没有元素,直接将新元素存储在这个位置。
- 如果有元素(即发生了哈希冲突),则使用
equals方法与该位置上已有的元素进行比较。- 如果
equals返回true,表示元素已存在,不再添加。 - 如果
equals返回false,则元素被添加到该位置的链表或红黑树上。
- 如果

- 当向
链表和红黑树:
- 在 Java 8 中,
HashMap对冲突处理进行了优化。当任何一个桶(bucket)中的链表元素数量达到TREEIFY_THRESHOLD(默认为8)时,且整个HashMap的容量达到MIN_TREEIFY_CAPACITY(默认为64),这个桶中的链表结构就会转换为红黑树结构,以提高搜索效率。
- 在 Java 8 中,
扩容机制:
- 当
HashMap中的元素数量超过容量与加载因子(load factor)的乘积时,HashMap会进行扩容,新的容量是原来容量的两倍。 
- 当
# 4. LinkedHashSet
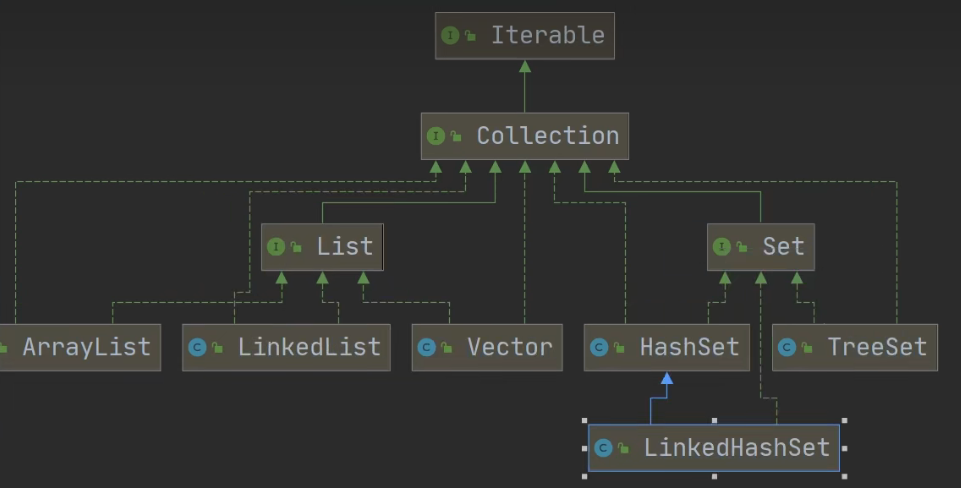
LinkedHashSet是Java集合框架中的一部分,它结合了哈希表的快速访问特性和链表维护元素顺序的特性。
- 继承与实现:
LinkedHashSet继承自HashSet并实现了Set接口,因此它继承了Set接口的所有特性,包括集合元素的不可重复性。 - 底层数据结构:
LinkedHashSet内部通过一个LinkedHashMap来实现。LinkedHashMap不仅保持了HashMap的所有特性,还通过内部的双向链表维护了元素的插入顺序。 - 元素的唯一性:
LinkedHashSet不允许重复元素。当尝试添加一个已经存在于集合中的元素时,该操作不会改变集合的内容。 - 顺序性:与
HashSet不同,LinkedHashSet会按照元素添加的顺序来迭代元素。这使得迭代访问LinkedHashSet时能够预期元素返回的顺序,这一点是通过底层LinkedHashMap的双向链表实现的。
在LinkedHashSet的默认构造函数中,它通过调用HashSet的构造函数并传递一个特殊的布尔值(true),这个布尔值在这里没有直接使用,其目的是为了选择正确的构造函数重载。在HashSet的构造函数中,它实际上初始化了一个LinkedHashMap,设置了初始容量(16)和加载因子(0.75)。这样,LinkedHashSet就结合了哈希表的快速访问能力和链表维护插入顺序的能力。
/**
* 构造一个新的空LinkedHashSet,具有默认的初始容量(16)和加载因子(0.75)。
*/
public LinkedHashSet() {
super(16, .75f, true); // 调用HashSet的构造函数
}
/**
* 构造函数,初始化一个LinkedHashMap来存储集合元素。
* @param initialCapacity 初始容量
* @param loadFactor 加载因子,用于控制何时自动扩容
* @param dummy 仅用于区分其他构造函数,没有实际用途
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor); // 初始化底层的LinkedHashMap
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
LinkedHashSet的使用场景
- 维护插入顺序:当你需要一个集合来保持元素的插入顺序时,
LinkedHashSet是一个理想的选择。这对于某些业务逻辑,如显示顺序敏感的数据列表、记录操作顺序等场景特别有用。 - 唯一性约束:与
HashSet相同,LinkedHashSet不允许重复元素。因此,它适用于需要排除重复但又要保留元素添加顺序的场景。 - 性能要求:虽然
LinkedHashSet在维护插入顺序上比HashSet稍慢,但在插入、删除、包含检查等操作上仍提供了不错的常数时间性能。因此,当需要既保持插入顺序又要求较高性能的场景下,LinkedHashSet是一个很好的选择。 - 作为缓存的使用:由于
LinkedHashSet保持了插入顺序,它可以用于实现简单的缓存策略,如最近最少使用(LRU)策略。尽管Java标准库中有更专门的类型(如LinkedHashMap)可以直接用于此目的,但在某些简化场景下LinkedHashSet也可以作为一个轻量级解决方案。 - 数据集处理:在处理数据集时,尤其是当数据的顺序很重要,同时又需要去重时,
LinkedHashSet提供了一种简洁的解决方案。
# 5. TreeSet
- TreeSet的独特之处在于它的构造器可以传入比较器,所以TreeSet常用来排序,TreeSet 底层是 TreeMap
import java.util.Comparator;
import java.util.TreeSet;
public class TreeSet_ {
public static void main(String[] args) {
TreeSet treeSet = new TreeSet();//无参构造,默认排序
//添加数据
treeSet.add("Jack");
treeSet.add("Tom");
treeSet.add("Ayo");
treeSet.add("Luck");
System.out.println(treeSet);//默认排序:首字母ASCII由小到大
//[Ayo, Jack, Luck, Tom]
//如果我们想按字符串大小排序
//使用TreeSet提供的一个构造器,传入一个比较器(匿名内部类)指定排序规则
treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o2).compareTo((String)o1);//利用String类的compareTo方法,由大到小
//如果是按照长度由大到小:return ((String)o1).length()-((String)o2).length();
}//构造器把传入的比较器对象,赋给了TreeSet的底层的TreeMap的属性this.comparator
});
treeSet.add("Jack");
treeSet.add("Tom");
treeSet.add("Ayo");
treeSet.add("Luck");
System.out.println(treeSet);//[Tom, Luck, Jack, Ayo]
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 6. TreeSet 和 HashSet 的区别
| Set 底层结构 | TreeSet | HashSet |
|---|---|---|
| 底层结构 | 红黑树 | 哈希桶 |
| 插入/删除/查找时间复杂度 | O(log2^N) | O(1) |
| 是否有序 | 关于 Key 有序 | 不一定有序 |
| 线程安全 | 不安全 | 不安全 |
| 插入/删除/查找区别 | 按照红黑树的特性来进行插入和删除 | 1. 先计算key的哈希地址 2. 然后进行插入和删除 |
| 比较与覆写 | key必须能够比较,否则会抛出ClassCastException异常 | 自定义类型需要覆写equals和hashCode方法 |
| 应用场景 | 需要Key有序场景下 | Key 是否有序不关心,需要更高的时间性能 |
编辑此页 (opens new window)
上次更新: 2024/12/28, 18:32:08