 Queue接口
Queue接口

# 1. 队列的概念和基本使用
1. 什么是队列 (参考博客 (opens new window))
只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出的特点:进行插入操作的一端称为队尾(Tail/Rear) 出队列:进行删除操作的一端称为队头(Head/Front)
2. 普通队列和双端队列
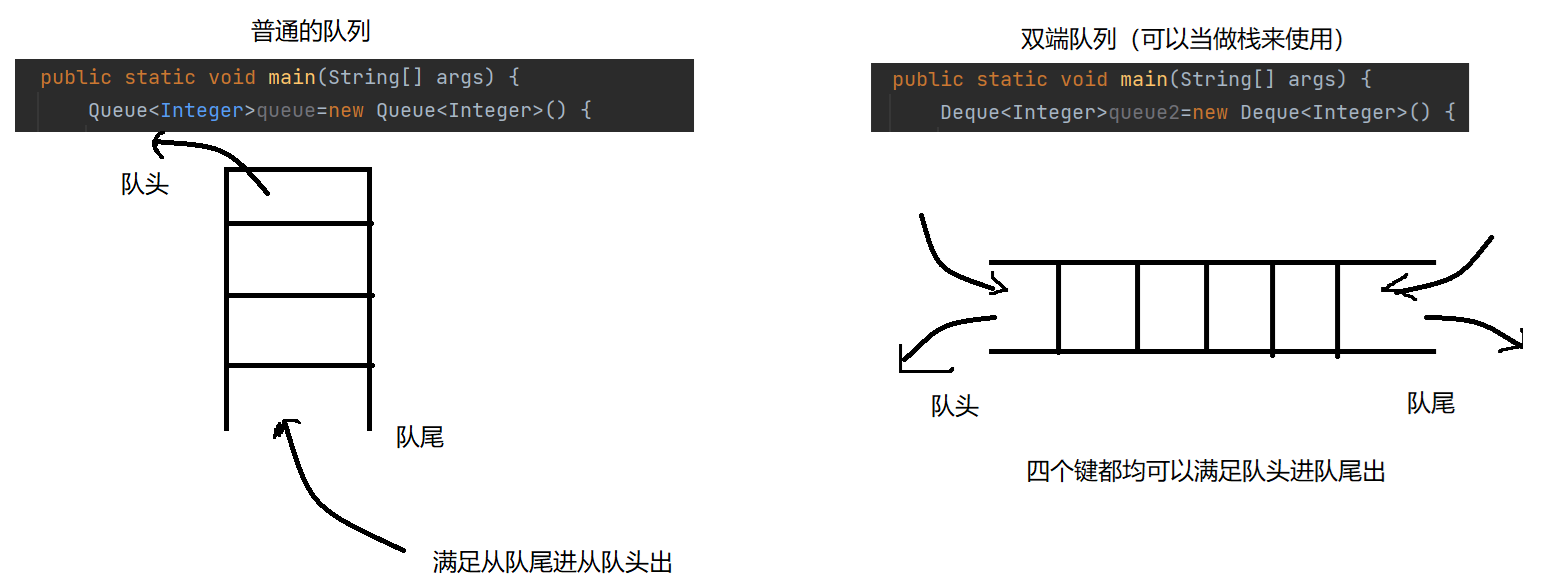
3. 关于队列一些操作的实现
① 普通队列
Queue(一般多使用返回特殊值的处理,更加方便)
| 错误处理 | 抛出异常 | 返回特殊值 |
|---|---|---|
| 入队列 | add(e) | offer(e) |
| 出队列 | remove() | poll() |
| 队首元素 | element() | peak() |
方法简单演示:
public class Test {
public static void main(String[] args) {
Queue<Integer> queue = new LinkedList<>();
queue.offer(1);
queue.offer(2);
System.out.println("该队列队头元素为:");
System.out.println(queue.peek());
System.out.println("出队元素为");
System.out.println(queue.poll());
}
}
2
3
4
5
6
7
8
9
10
11
② 双端队列
Deque(一般多使用返回特殊值的处理,更加方便)
| 头部/尾部 | 头部元素(队首) | 尾部元素(队尾) | ||
|---|---|---|---|---|
| 错误处理 | 抛出异常 | 返回特殊值 | 抛出异常 | 返回特殊值 |
| 入队列 | addFirst(e) | offerFirst(e) | addLast(e) | offerLast(e) |
| 出队列 | removeFirst() | pollFirst() | removeLast() | pollLast() |
| 获取元素 | getFirst() | peekFirst() | getLast() | peekLast() |
方法简单演示:
import java.util.*;
public class Test {
public static void main(String[] args) {
Deque<Integer> queue = new LinkedList<>();
queue.offerFirst(2);
queue.offerLast(1);
System.out.println("该队列队头元素为:");
System.out.println(queue.peek());
System.out.println("出队元素为");
System.out.println(queue.poll());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
● 顺序队:Queue接口+实现类ArrayDeque
// 基于数组实现,适用于队列大小预知且变动不大的场景。
// 特点是随机访问快,但扩容可能代价较高
Queue<Integer> queue = new ArrayDeque<>();//顺序队列
2
3
● 链式队:Queue接口+实现类LinkedList
// 基于链表实现,适用于队列大小频繁变动的场景
// 特点是插入和删除操作快,但随机访问慢。
Queue<Integer> queue2 = new LinkedList<>();//链式队列
2
3
# 2. 优先级队列和堆的概念
1.1.什么是优先级队列?
我们都学过队列,队列是一种先进先出的数据结构,但有些情况下,操作的数据可能带有优先级,一般出队列时,可能需要优先级高的元素先出队列,这就是优先级队列。比如有时候我们在打游戏的时候,别人打电话给你,那么系统一定是先处理打进来的电话。
1.2.什么是堆?
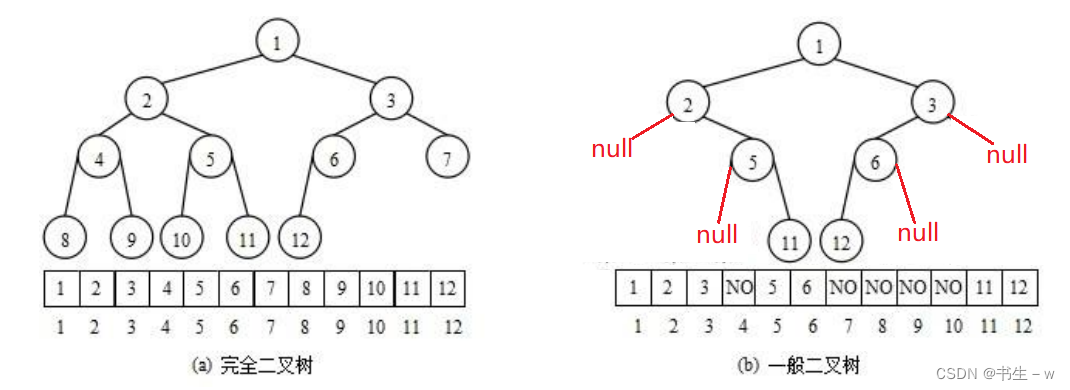
堆是一个(特殊的)完全二叉树,每个父节点都不大于或者不小于自己的孩子节点,层序遍历这个二叉树,顺序的放入一个数组中,这就是堆的存储。从逻辑上来说,堆是一棵完全二叉树,从存储底层来说,堆底层是一个数组。按种类分,它又分为大根堆和小根堆,请看下图:

将元素存储到数组后,在以实现树的方式对堆进行实现。 设 i 结点为数组中的下标,则有以下特点:
- 如果 i 为0,则 i 表示的结点为根节点,否则 i 结点的双亲结点为(i - 1)/ 2;
- 如果 2 * i + 1 小于结点个数,则节点 i 的左孩子下标为 2 * i + 1,否则没有左孩子;
- 如果 2 * i + 2 小于结点个数,则节点 i 的左孩子下标为 2 * i + 2,否则没有右孩子。
注意:堆是一棵完全二叉树,它有着层序遍历的规则,所以采用顺序存储的方式来提高效率,而非完全二叉树不适合用顺序存储的方式来进行存储的,因为它为了能够还原二叉树,空间中必须要存储空节点,就会导致空间利用率比较低。

# 3. 向下调整算法
向下调整算法(Heapify Down)是一种用于维护堆(最大堆或最小堆)性质的算法。当堆中的某个节点的值不满足堆性质(在最大堆中,每个节点的值都应大于或等于其子节点的值;在最小堆中,每个节点的值都应小于或等于其子节点的值)时,向下调整算法会将该节点向下移动,直到它满足堆性质。
向下调整算法通常用于以下场景:
- 当从堆中删除最大值(最大堆)或最小值(最小堆)时,通常将堆的最后一个元素移动到堆顶,然后进行向下调整,以重新满足堆的性质。
- 当初始化一个堆时,可以自底向上地对所有非叶子节点进行向下调整,以构建一个有效的堆结构。
向下调整算法的过程如下:
- 从不满足堆性质的节点开始,找到其子节点中的最大值(最大堆)或最小值(最小堆)。
- 如果当前节点的值小于(最大堆)或大于(最小堆)子节点中的最大值或最小值,则将当前节点与该子节点交换。
- 重复以上过程,直到当前节点满足堆的性质,或已经到达堆的底部。
图示: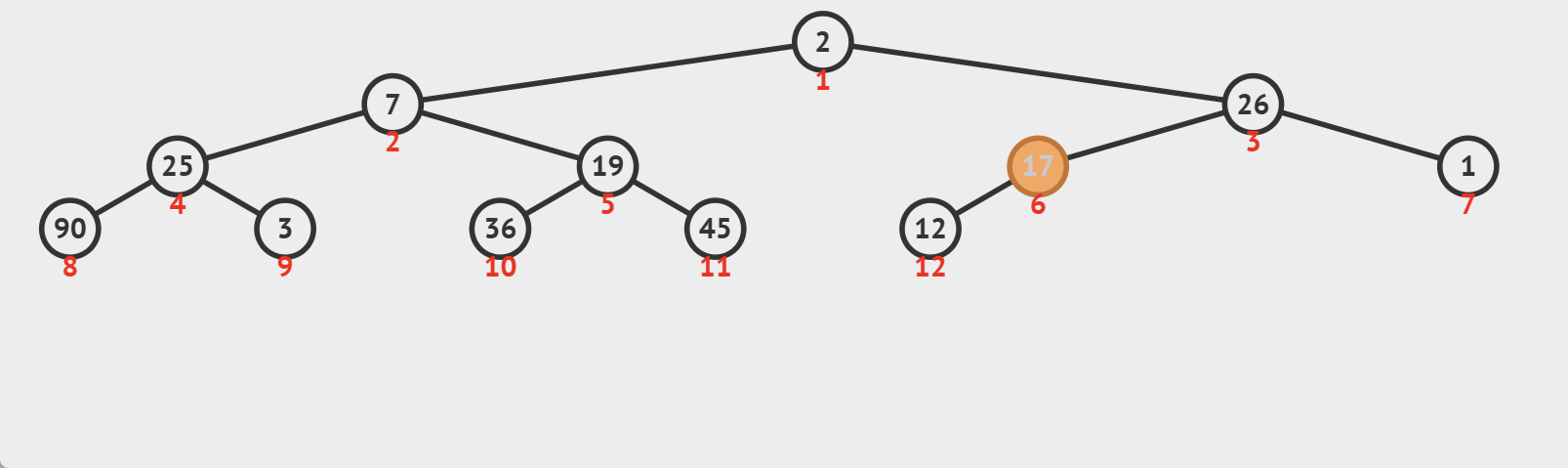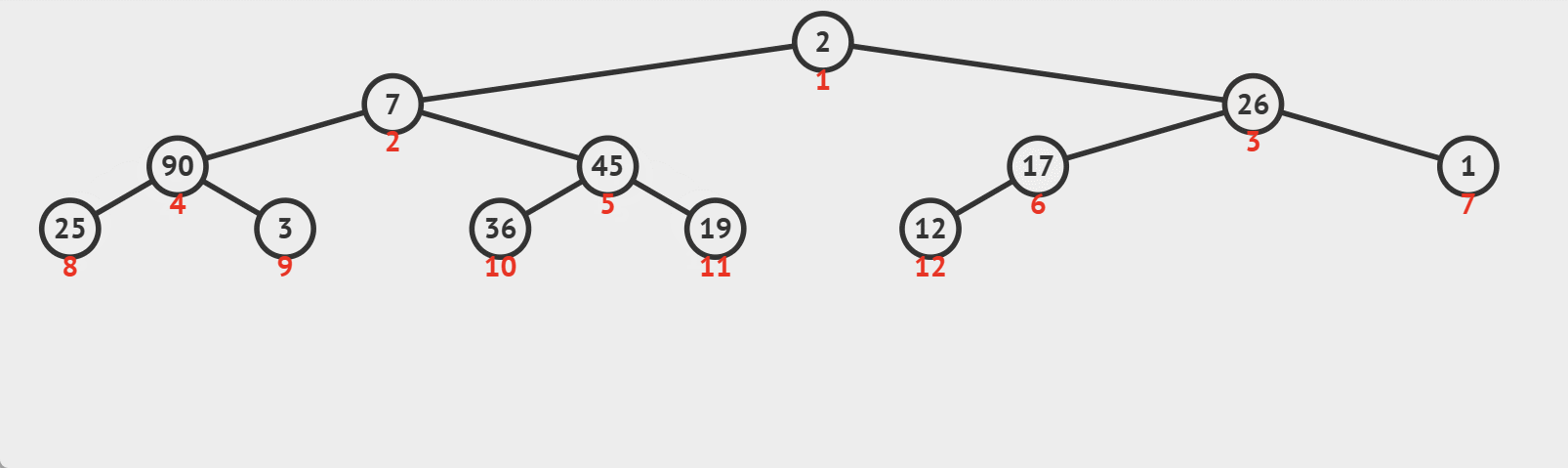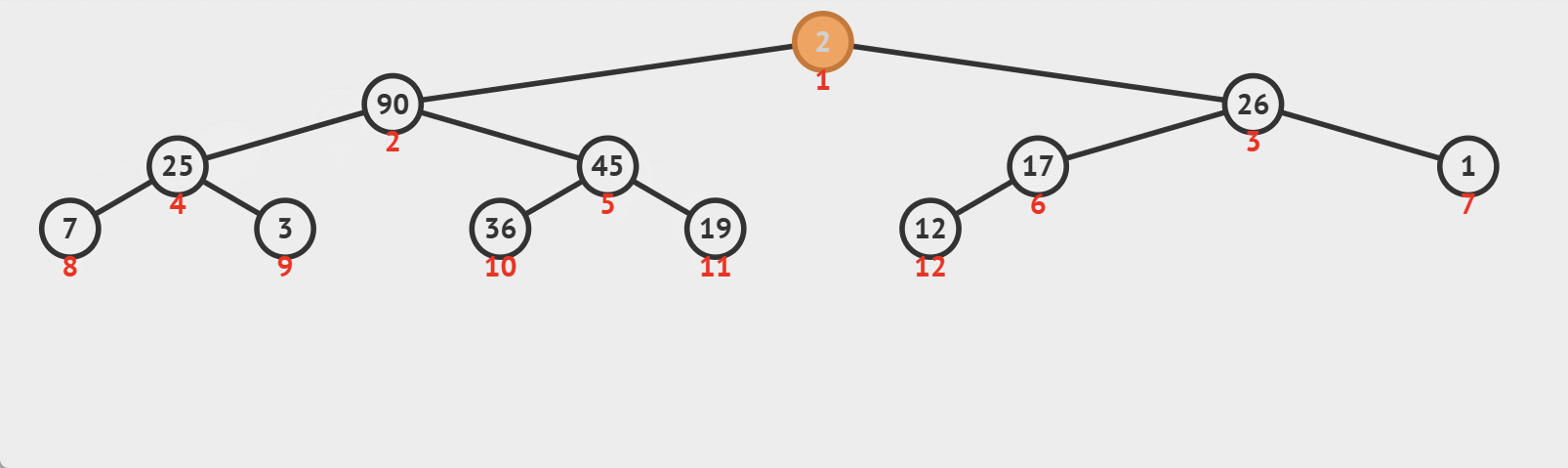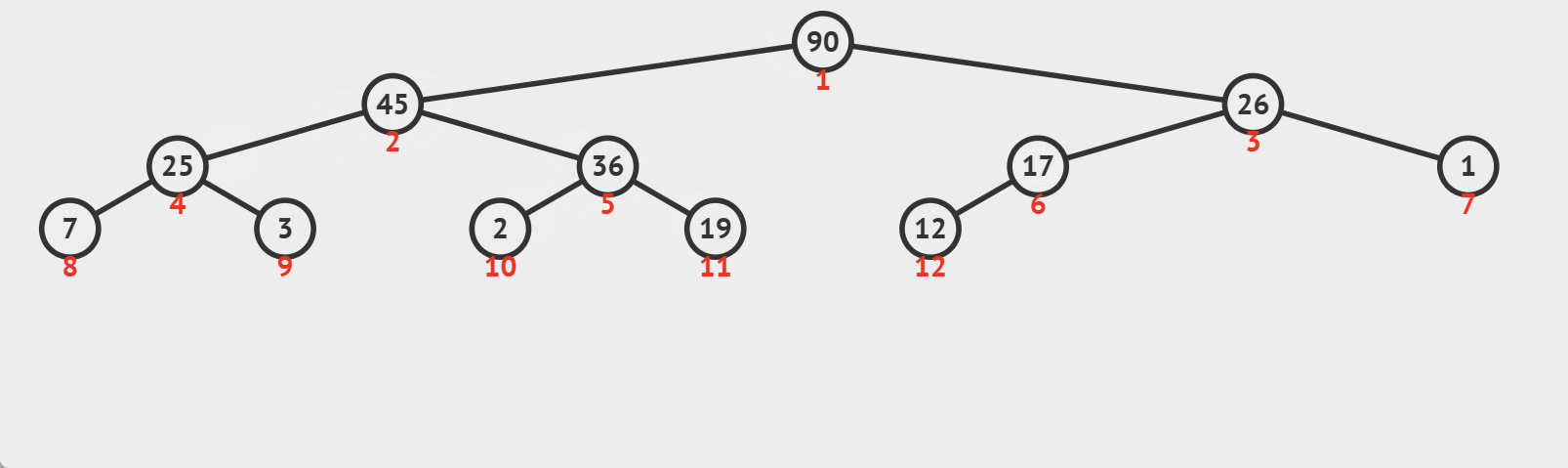
这种算法通过不断地将不满足堆性质的节点向下移动,直到找到合适的位置,从而维护了堆的性质。注意,向下调整算法在最坏情况下的时间复杂度为O(logn),其中n是堆中元素的数量。
# 4. 向上调整算法
向上调整算法(Heapify Up)是一种用于维护堆(最大堆或最小堆性质的算法。当堆中的某个节点的值不满足堆性质(在最大堆中,每个节点的值都应大于或等于其子节点的值;在最小堆中,每个节点的值都应小于或等于其子节点的值)时,向上调整算法会将该节点向上移动,直到它满足堆性质。
向上调整算法通常用于以下场景:
- 当向堆中插入一个新元素时,通常将该元素添加到堆的末尾,然后进行向上调整,以重新满足堆的性质。
向上调整算法的过程如下:
- 从不满足堆性质的节点开始,找到其父节点。
- 如果当前节点的值大于(最大堆)或小于(最小堆)其父节点的值,则将当前节点与其父节点交换。
- 重复以上过程,直到当前节点满足堆的性质,或已经到达堆的顶部。
这种算法通过不断地将不满足堆性质的节点向上移动,直到找到合适的位置,从而维护了堆的性质。注意,向上调整算法在最坏情况下的时间复杂度为O(logn),其中n是堆中元素的数量。
向上调整算法(Heapify Up)和向下调整算法(Heapify Down)都可以用于建堆,它们的时间复杂度有所不同。
# 5. 向上调整算法和向下调整算法的建堆时间复杂度
# 5.1 向上调整算法建堆
向上调整算法建堆的过程是从一个空堆开始,依次将数组中的元素插入堆中。对于每个插入的元素,执行向上调整。在这个过程中,每个元素的向上调整最多需要O(logn)时间(其中n是堆中元素的数量),因为堆的高度是logn。
为什么向下调整算法建堆的时间复杂度为O(logn)?
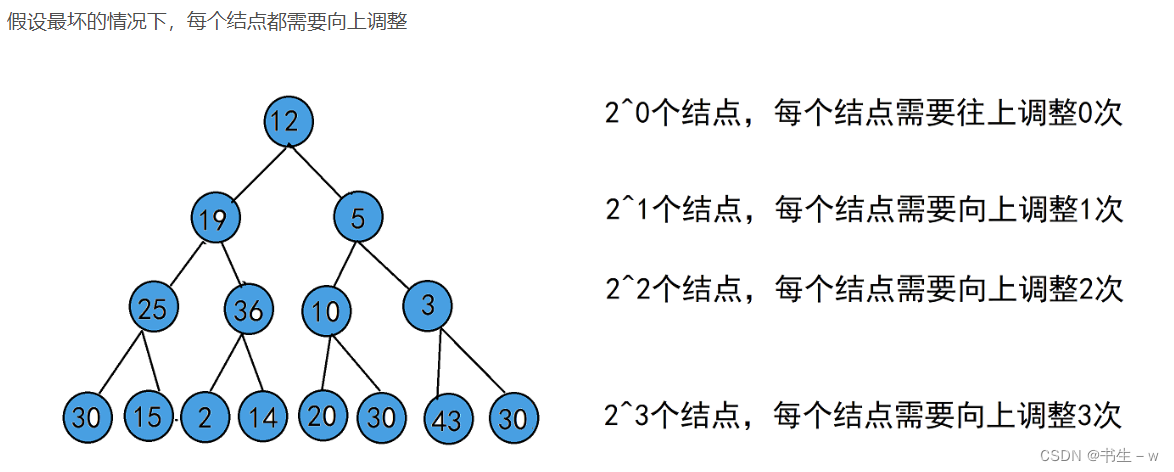
由二叉树的性质可以得知,每层结点的个数是2^(h-1),在第几层的结点如果需要调整的话,最多需要向上调整h-1次。那么,调整次数将与高度相关,如下
因此,向上调整算法建堆的总时间复杂度为O(nlogn)。这是因为我们需要对n个元素执行向上调整操作,每个操作的时间复杂度为O(logn)。
# 5.2 向下调整算法建堆
向下调整算法建堆的过程是自底向上地对所有非叶子节点进行向下调整。从最后一个非叶子节点开始,依次向前遍历,对每个节点进行向下调整。这种方法的时间复杂度为O(n)。
为什么向下调整算法建堆的时间复杂度为O(n)?
因为堆是完全二叉树,而满二叉树也是完全二叉树,此处为了简化使用满二叉树来证明(时间复杂度本来看的就是近似值,多几个节点不影响最终结果)
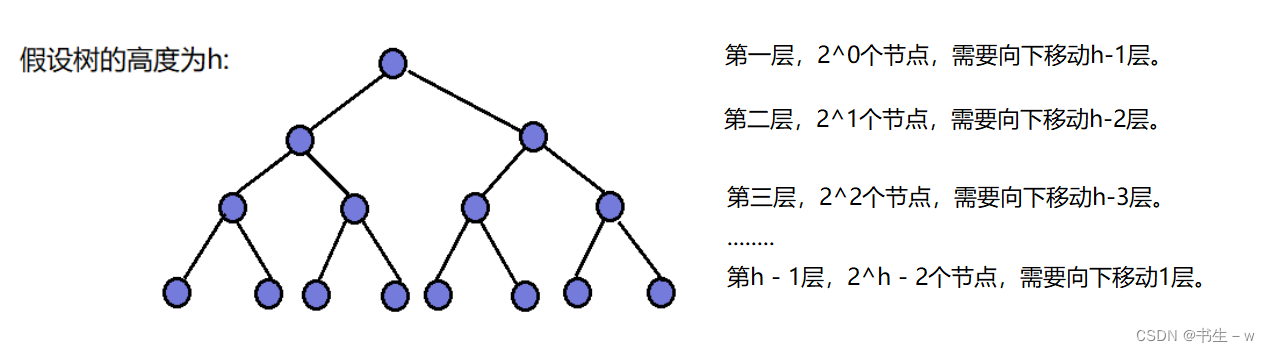

综上所述,向上调整算法建堆的时间复杂度为O(nlogn),而向下调整算法建堆的时间复杂度为O(n)。在实际应用中,向下调整算法建堆通常比向上调整算法建堆更高效。
# 6. PriorityQueue

1. PriorityQueue的特性
- PriorityQueue 中放置的 元素必须要能够比较大小,不能插入无法比较大小的对象,否则会抛出 ClassCastException 异常
- 不能 插入 null 对象,否则会抛出 NullPointerException,而Queue是可以插入null的
- 没有容量限制,可以插入任意多个元素,其内部可以自动扩容
- 插入和删除元素的时间复杂度为O(log(N))
- PriorityQueue 底层使用了堆数据结构
- PriorityQueue 默认情况下是小堆 --- 即每次获取到的元素都是最小的元素
2. PriorityQueue的使用
构造方法
| 构造方法 | 说明 |
|---|---|
| PriorityQueue() | 不带参数,默认容量为11 |
| PriorityQueue(int initialCapacity) | 参数为初始容量,该初始容量不能小于1 |
| PriorityQueue(Collection<? extends E> c) | 参数为一个集合 |
| PriorityQueue(Comparator<? super E> comparator) | 创建一个优先队列,使用提供的 Comparator 对象定义元素的排序规则,不指定初始容量。 |
| PriorityQueue(int initialCapacity, Comparator<? super E> comparator) | 创建一个具有指定初始容量的优先队列,并使用提供的 Comparator 对象定义元素的排序规则 |
常用方法
| 方法 | 说明 |
|---|---|
| boolean offer(E e) | 插入元素e,返回是否插入成功,e为null,会抛异常 |
| E peek() | 获取堆顶元素,如果队列为空,返回null |
| E poll() | 删除堆顶元素并返回,如果队列为空,返回null |
| int size() | 获取有效元素个数 |
| void clear() | 清空队列 |
| boolean isEmpty() | 判断队列是否为空 |
第一个构造方法:
// 创建一个空的优先级队列,底层默认容量是11
PriorityQueue<Integer> q1 = new PriorityQueue<>();
2
第二个构造方法:
// 创建一个容量为100的优先级队列,
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
2
第三个构造方法:
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
// 用ArrayList对象来构造一个优先级队列的对象
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
//此时q3中已经包含了四个元素
System.out.println(q3.size());//4
System.out.println(q3.peek());//默认小根堆所以堆顶元素是1
2
3
4
5
6
7
8
9
10
11
12
注意: 默认情况下,PriorityQueue队列是小堆,如果要转换成大堆需要用户提供比较器
class intCmp implements Comparator<Integer> {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;//大根堆
//o2-o1 小根堆
}
}
public class PriorityQueueDemo {
public static void main(String[] args) {
intCmp intcmp = new intCmp();
PriorityQueue<Integer> priorityQueue = new PriorityQueue<>(intcmp) ;
priorityQueue.offer(4);
priorityQueue.offer(3);
priorityQueue.offer(2);
priorityQueue.offer(1);
System.out.println(priorityQueue.peek());//4
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
也可以用匿名内部类的写法:
public static void main(String[] args) {
PriorityQueue<Integer> priorityQueue =
new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
}) ;
priorityQueue.offer(12);
priorityQueue.offer(2);
priorityQueue.offer(80);
System.out.println(priorityQueue.peek());//80
}
2
3
4
5
6
7
8
9
10
11
12
13
Lambda表达式写法(推荐使用):
PriorityQueue<Integer> queue = new PriorityQueue<>((o1 , o2) -> o1 - o2); // 小根堆
PriorityQueue<Integer> queue = new PriorityQueue<>((o1 , o2) -> o2 - o1); // 大根堆
2
# 7. PriorityQueue源码剖析
- 使用Student对象来创建一个优先级队列的对象
- 当我们在priorityQueue中存放一个Student 对象时, 可以正常放入且不发生报错。
- 但是当我们存放两个Studnet对象时,程序报错,出现类型不兼容异常。
public class TestDemo2 {
// 注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
public static void main(String[] args) {
PriorityQueue<Student> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(new Student(10));
priorityQueue.offer(new Student(5));
}
}
2
3
4
5
6
7
8
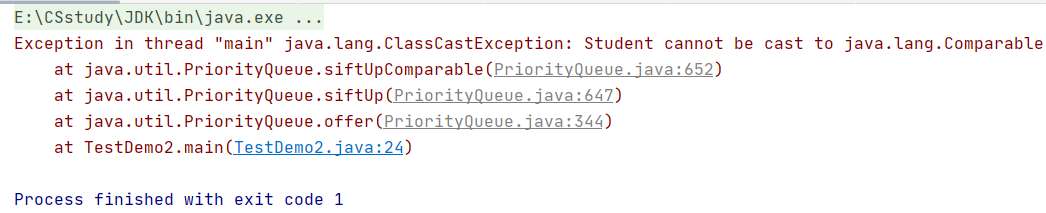
前边学习抽象类和常用接口时,我们了解到Java中对于引用数据类型的比较或者排序,一般都要用到使用Comparable接口中的compareTo() 方法
此时我们可以实现Comparable接口,并且重写 compare()方法。
class Student implements Comparable<Student>{
public int age;
public Student(int age) {
this.age = age;
}
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
public class TestDemo2 {
// 注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
public static void main(String[] args) {
PriorityQueue<Student> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(new Student(10));
priorityQueue.offer(new Student(5));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
经过调试我们可以发现,此时优先级队列中的两个元素已经按照小根堆的方式调整好了。
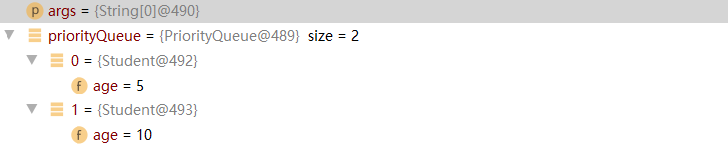
那么PriorityQueue是怎么对其中的引用数据类型进行调整的呢?

使用this引用指向了下边的方法,并传递参数。

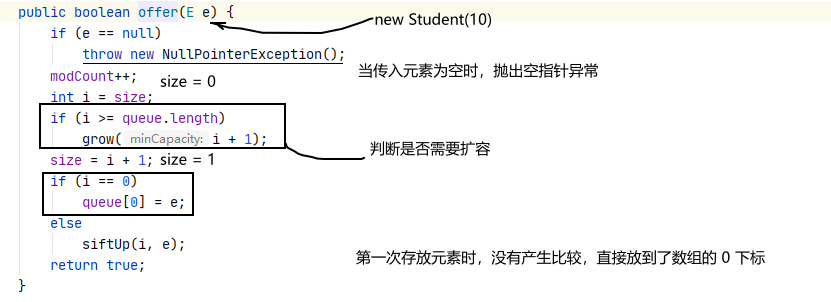
当queue数组初始化完毕时, 需要向数组中存放元素,即进行 priorityQueue.offer(new Student(10));
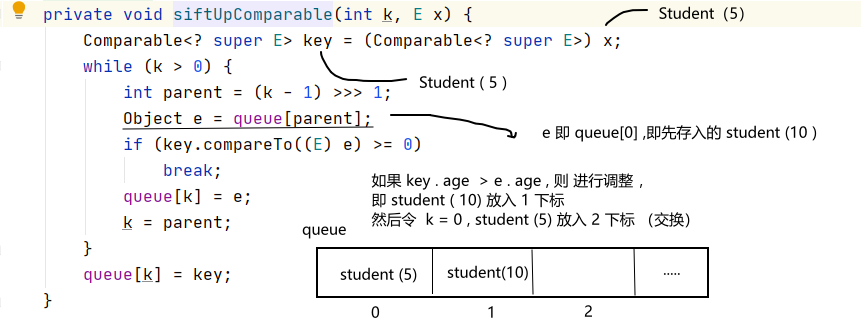
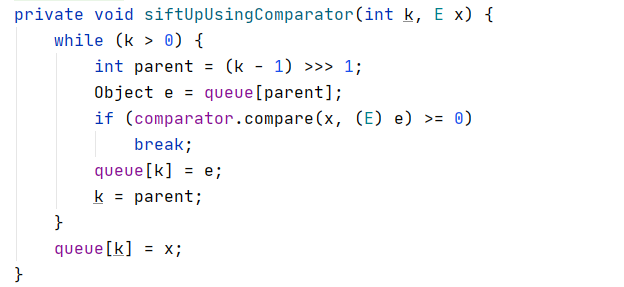
存放第二个元素时,i = 1 , size = 2 ,则需要执行 siftUp(1 , e) ,对 元素进行向上调整为小根堆 。

向下调整的过程中,使用了我们所重写的compareTo()方法,然后判断e,key对应的age的值,进行交换,如果此处不需要交换,则直接将key放入queue[1] 中即可 , 此时,小根堆调整完成
如果想要调整为大根堆的话,只需要修改Student类中的compareTo()方法即可
class Student implements Comparable<Student>{
public int age;
public Student(int age) {
this.age = age;
}
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
public class TestDemo2 {
// 注意:默认情况下,PriorityQueue队列是小堆,如果需要大堆需要用户提供比较器
public static void main(String[] args) {
PriorityQueue<Student> priorityQueue = new PriorityQueue<>();
priorityQueue.offer(new Student(10));
priorityQueue.offer(new Student(5));
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
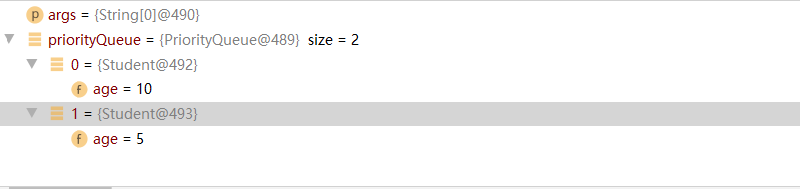
那么Integer类型的参数该如何修改为大根堆 呢? ,Integer类型已经重写了compareTo方法,但是已经写死了,默认为小根堆的实现方式,无法修改源码,此时,我们就应该 构造Comparator 比较器来实现。
// 用户自己定义的比较器:直接实现Comparator接口,然后重写该接口中的compare方法即可
class IntCmp implements Comparator<Integer>{
@Override
public int compare(Integer o1, Integer o2) {
//return o2-o1;
return o2.compareTo(o1);
}
}
public class TestPriorityQueue {
public static void main(String[] args) {
PriorityQueue<Integer> p = new PriorityQueue<>(new IntCmp());
p.offer(4);
p.offer(3);
p.offer(2);
p.offer(1);
p.offer(5);
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
❗当传入比较器时,PriorityQueue会按照 比较器的方式进行 比较,与实现Comparable 接口的方法类似,此处不再赘述,元素进而被调整为大根堆。

✅另一种写法 :
public class TestPriorityQueue {
public static void main(String[] args) {
//匿名内部类,这里有一个类,实现了Comparator 这个接口,并重写了compare这个方法
PriorityQueue<Integer> p = new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2 - o1;
}
});
}
}
2
3
4
5
6
7
8
9
10
11
🔻PriorityQueue的扩容机制:

优先级队列的扩容说明:
- 如果容量小于64时,是按照约oldCapacity的2倍方式扩容的(2*OldCapacity+2)
- 如果容量大于等于64,是按照oldCapacity的1.5倍方式扩容的
- 如果容量超过MAX_ARRAY_SIZE,按照MAX_ARRAY_SIZE来进行扩容
# 8. Top-K问题
对于Top-K问题,能想到的最简单直接的方式就是排序,但是:如果数据量非常大,排序就不太可取了(可能数据都不能一下子全部加载到内存中)。最佳的方式就是用堆来解决,基本思路如下:
1. 用数据集合中前K个元素来建堆 前k个最大的元素,则建小堆 前k个最小的元素,则建大堆
2. 用剩余的N-K个元素依次与堆顶元素来比较,不满足则替换堆顶元素 将剩余N-K个元素依次与堆顶元素比完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
为什么建小堆可以求出前k个最大元素呢?(求大根堆同理)
我们可以这样来理解,最开始我们拿数组的前k个元素建立成小堆,那么此时堆顶元素一定是前k个元素中的最小值数组,那此时我们剩下的元素与堆顶元素比较时,如果比堆顶元素还小,那么它一定不是前k个中的最大值,当数组元素大于堆顶元素时,这个值可能是要求的最大值,我们删除堆顶元素添加这个值,重新调整为小根堆,重复上述操作,最后小根堆里面就是我们要求的最大值。
class Solution {
public int[] smallestK(int[] arr, int k) {
int[] vec = new int[k];
if (vec == null || k == 0) {
return vec;
}
//传入比较器,按照大根堆调整
PriorityQueue<Integer> queue = new PriorityQueue<Integer>(new Comparator<Integer>() {
public int compare(Integer num1, Integer num2) {
return num2 - num1;
}
});
//存入K个 元素
for (int i = 0; i < k; ++i) {
queue.offer(arr[i]);
}
//比较堆顶元素与剩余n - k个元素的值的大小
//如果堆顶元素较大,则弹出堆顶,重新调整,元素入堆
for (int i = k; i < arr.length; ++i) {
if (queue.peek() > arr[i]) {
queue.poll();
queue.offer(arr[i]);
}
}
//将堆中元素存入数组中
for (int i = 0; i < k; ++i) {
vec[i] = queue.poll();
}
return vec;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
# 9. Comparable和Comparator的区别
# 9.1 Comparable(内部比较器)
- 内部比较:
Comparable接口用于定义对象的默认排序。实现Comparable接口的类必须实现compareTo(T o)方法。 - 默认排序实现:当一个类实现了
Comparable接口,它就具备了默认的排序能力。这意味着,这个类的实例可以直接被排序函数(如Collections.sort()或Arrays.sort())所使用,而不需要指定额外的比较逻辑。 - 使用场景:
Comparable接口通常在类的设计阶段被实现,当类的创建者有权修改类的源代码时。它适用于那些有明确和单一的排序逻辑的场合。例如,一个Person类可能根据年龄或姓名进行自然排序。
- 从小到大(升序)排序:
- 在
compareTo方法中,如果当前对象(this)小于参数对象(o),则返回负值;如果大于,返回正值;如果等于,返回零。- 例如,对于整数,
return this.value - o.value;实现升序排序。- 从大到小(降序)排序:
- 在
compareTo方法中,如果当前对象(this)大于参数对象(o),则返回负值;如果小于,返回正值;如果等于,返回零。- 例如,对于整数,
return o.value - this.value;实现降序排序。
class People implements Comparable<People> {
public int age;
public String name;
public People(int age, String name) {
this.age = age;
this.name = name;
}
// 重写compareTo方法进行比较。这里我们按年龄比较,不考虑姓名。
// 认为null值的对象是最小的。
@Override
public int compareTo(People o) {
if (o == null) {
return 1; // 如果比较的对象是null,我们认为当前对象更大。
}
return this.age - o.age; // 按年龄升序排序,年龄小的在前。
}
}
public class TestDemo1 {
public static void main(String[] args) {
People p1 = new People(18, "zhangsan");
People p2 = new People(20, "lisi");
People o = new People(18, "lisi");
// 比较三个人的年龄大小
System.out.println(p1.compareTo(o)); // 结果为0,因为年龄相同
System.out.println(p1.compareTo(p2)); // 结果为负数,因为p1年龄小于p2
System.out.println(p2.compareTo(p1)); // 结果为正数,因为p2年龄大于p1
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
# 9.2 Comparator(外部比较器)
- 外部比较:
Comparator是一个独立的接口,它有一个compare(T o1, T o2)方法,用于定义两个对象间的排序。 - 多重排序:如果一个对象有多个排序方式,或者排序逻辑不能修改对象的类(例如,类没有实现
Comparable或者是一个第三方库的类),那么可以使用Comparator。 - 灵活性:可以创建多个不同的
Comparator实现类,以便在不同的场景下使用不同的排序策略。 - 使用场景:不需要修改类的源码,可以在任何时候定义对象的排序逻辑。可以对第三方库中的对象进行排序,即使这些类没有实现
Comparable接口。
- 从小到大(升序)排序:
- 在
compare方法中,如果第一个参数对象(o1)小于第二个参数对象(o2),则返回负值;如果大于,返回正值;如果等于,返回零。- 例如,
return o1.age - o2.age;会按照年龄升序排序。- 从大到小(降序)排序:
- 在
compare方法中,如果第一个参数对象(o1)大于第二个参数对象(o2),则返回负值;如果小于,返回正值;如果等于,返回零。- 例如,
return o2.age - o1.age;会按照年龄降序排序。
class People {
public int age;
public String name;
public People(int age, String name) {
this.age = age;
this.name = name;
}
}
// 自定义比较器,用于比较People对象。
class PeopleComparator implements Comparator<People> {
@Override
public int compare(People o1, People o2) {
if (o1 == o2) {
return 0; // 如果两个对象是相同的,返回0。
}
if (o1 == null) {
return -1; // 如果第一个对象是null,我们认为它小于非null的对象。
}
if (o2 == null) {
return 1; // 如果第二个对象是null,我们认为第一个对象大于null。
}
return o1.age - o2.age; // 按年龄升序排序。
}
}
public class TestDemo2 {
public static void main(String[] args) {
People p1 = new People(18, "zhangsan");
People p2 = new People(20, "lisi");
People o = new People(18, "lisi");
// 创建一个自定义的比较器对象
PeopleComparator comparator = new PeopleComparator();
// 使用比较器对象进行比较
System.out.println(comparator.compare(p1, o)); // 结果为0,因为年龄相同
System.out.println(comparator.compare(p1, p2)); // 结果为负数,因为p1年龄小于p2
System.out.println(comparator.compare(p2, p1)); // 结果为正数,因为p2年龄大于p1
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42