 Scrapy - 工业级爬虫框架
Scrapy - 工业级爬虫框架
# Scrapy - 工业级爬虫框架
当我们从简单的脚本小子成长为专业的爬虫工程师时,就需要一个更强大、更规范的工具来应对大规模、高效率的爬取任务。Scrapy 就是 Python 世界中当之无愧的王者级爬虫框架。
Scrapy 是一个为了爬取网站数据、提取结构性数据而编写的应用程序框架。它内置了异步处理机制,拥有高效的并发性能,并提供了一整套完整的架构,包括请求调度、数据处理管道、中间件等,极大地提升了开发效率和爬虫性能。
# 1. Scrapy 核心架构
理解 Scrapy 的数据流和组件是掌握它的关键。
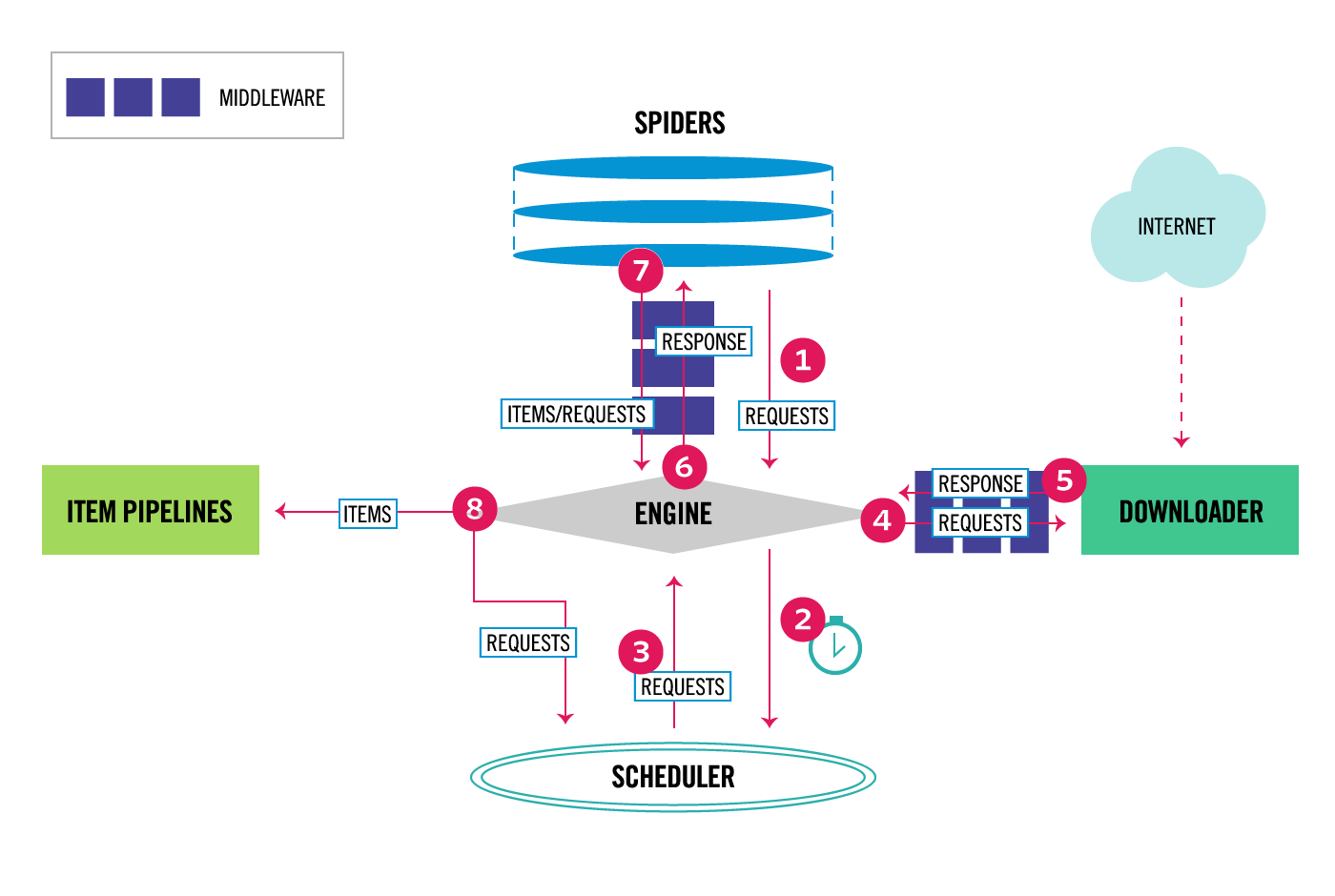
- 引擎 (Engine): 整个框架的核心,负责控制所有组件之间的数据流,并在特定事件发生时触发相应的动作。
- 调度器 (Scheduler): 接收引擎发来的请求 (Request),将它们放入一个队列中,并在引擎请求时提供下一个要抓取的 URL。
- 下载器 (Downloader): 负责获取页面数据。它接收引擎发来的请求,执行下载,然后将响应 (Response) 返回给引擎。
- 爬虫 (Spiders): 这是我们编写主要逻辑的地方。它负责创建初始请求,并根据服务器的响应解析数据、提取出我们需要的条目 (Item),以及生成新的请求。
- 项目管道 (Item Pipeline): 负责处理由 Spider 提取出的 Item。典型的应用场景包括数据清洗、验证和持久化(如存入数据库)。
- 中间件 (Middlewares): 位于引擎和各个组件之间的钩子,可以自定义修改 Scrapy 的请求和响应。例如,设置随机 User-Agent、使用代理 IP 等。
# 2. 安装 Scrapy
通过 pip 可以轻松安装 Scrapy。
pip install scrapy
# 3. 创建你的第一个 Scrapy 项目
Scrapy 提供了命令行工具来快速生成项目骨架。
打开你的终端,进入你想要创建项目的目录。
执行
startproject命令:scrapy startproject my_first_scraper1这个命令会创建一个名为
my_first_scraper的文件夹,其内部结构如下:my_first_scraper/ ├── scrapy.cfg # 项目的配置文件 └── my_first_scraper/ ├── __init__.py ├── items.py # 定义要抓取的数据结构 (Item) ├── middlewares.py # 中间件 ├── pipelines.py # 项目管道 ├── settings.py # 项目的全局设置 └── spiders/ # 存放所有爬虫 (Spider) 的目录 └── __init__.py1
2
3
4
5
6
7
8
9
10
# 4. 定义要抓取的数据 (items.py)
在 items.py 文件中,我们通过定义一个 scrapy.Item 的子类,来声明我们需要从网页中提取哪些字段。这就像是为你的数据创建了一个结构化的模板。
例如,我们要爬取名言警句网站,需要提取“内容”、“作者”和“标签”。
# my_first_scraper/items.py
import scrapy
class QuoteItem(scrapy.Item):
# 使用 scrapy.Field() 来定义每一个你想要抓取的字段
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
2
3
4
5
6
7
8
9
# 5. 编写爬虫 (Spider)
爬虫是 Scrapy 的核心,是我们定义爬取逻辑的地方。
在终端中,进入项目的主目录 (包含
scrapy.cfg的那层)。使用
genspider命令创建一个新的爬虫:# scrapy genspider <爬虫名字> <允许爬取的域名> scrapy genspider quotes quotes.toscrape.com1
2这会在
spiders目录下创建一个quotes.py文件。编辑
quotes.py文件:# my_first_scraper/spiders/quotes.py import scrapy from ..items import QuoteItem # 从 items.py 导入我们定义的 QuoteItem class QuotesSpider(scrapy.Spider): # 爬虫的唯一标识名,在项目中不能重复 name = 'quotes' # (可选) 允许爬虫爬取的域名列表。如果请求的 URL 不在此列表中,将被忽略。 allowed_domains = ['quotes.toscrape.com'] # 爬虫启动时请求的第一个 URL 列表 start_urls = ['http://quotes.toscrape.com/'] def parse(self, response): """ 这是 Scrapy 默认的回调方法。 当 start_urls 中的请求完成后,下载器返回的响应 (Response) 会作为参数传递给这个方法。 这个方法的核心任务是: 1. 解析响应内容,提取数据。 2. 找到新的链接,并生成新的请求。 """ # response 对象内置了强大的选择器 (CSS 和 XPath) # 我们使用 CSS 选择器来定位所有包含名言的 div 标签 all_quotes = response.css('div.quote') # 遍历所有找到的名言 div for quote in all_quotes: # 创建一个我们之前定义的 Item 实例 item = QuoteItem() # 使用选择器提取数据,并存入 item 对应的字段 # .css('span.text::text') 表示选择 class="text" 的 span 标签,并提取其文本内容 # .get() 获取第一个匹配项,如果没有则返回 None item['text'] = quote.css('span.text::text').get() # .css('small.author::text').get() 提取作者 item['author'] = quote.css('small.author::text').get() # .css('div.tags a.tag::text') 提取所有标签 # .getall() 获取所有匹配项,返回一个列表 item['tags'] = quote.css('div.tags a.tag::text').getall() # 使用 yield 将填充好的 item 交给 Scrapy 引擎,引擎会将其送入 Pipeline 处理 yield item1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
# 6. 运行爬虫并保存数据
回到终端,确保你还在项目的根目录下。
# scrapy crawl <爬虫名字>
scrapy crawl quotes
2
你会在终端看到大量的日志输出,包括你提取出的数据。
如果想将数据保存到文件,Scrapy 提供了极其方便的 Feed Exports 功能,无需编写任何代码。
# 保存为 JSON 文件 (-o 表示输出文件)
scrapy crawl quotes -o quotes.json
# 保存为 CSV 文件
scrapy crawl quotes -o quotes.csv
# 保存为 XML 文件
scrapy crawl quotes -o quotes.xml
2
3
4
5
6
7
8
# 7. 实现翻页 (生成新的请求)
目前我们的爬虫只能抓取第一页。要实现自动翻页,我们需要在 parse 方法中找到“下一页”的链接,并生成一个新的 scrapy.Request。
修改 parse 方法:
# my_first_scraper/spiders/quotes.py
# ... (前面的代码不变) ...
class QuotesSpider(scrapy.Spider):
# ... (name, allowed_domains, start_urls 不变) ...
def parse(self, response):
# ... (提取当前页数据的 for 循环不变) ...
for quote in response.css('div.quote'):
# ... (yield item 的代码不变) ...
yield { # 也可以直接 yield 字典
'text': quote.css('span.text::text').get(),
'author': quote.css('small.author::text').get(),
}
# --- 新增翻页逻辑 ---
# 1. 使用 CSS 选择器找到“下一页”的 a 标签
next_page_link = response.css('li.next a::attr(href)').get()
# 2. 检查是否找到了链接
if next_page_link is not None:
# 3. response.follow() 是一个快捷方式,用于创建对相对 URL 的请求。
# 它会自动处理拼接完整 URL 的工作。
# 我们指定 callback=self.parse,意味着当这个新请求完成后,
# 其响应会再次由 parse 方法来处理,从而形成一个循环。
yield response.follow(next_page_link, callback=self.parse)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
现在再次运行 scrapy crawl quotes,你会发现它会自动一页一页地抓取下去,直到最后一页。
# 8. 使用 Item Pipeline 处理数据
虽然 -o 参数很方便,但对于复杂的数据处理(如去重、存入数据库),我们需要使用 Item Pipeline。
一个 Pipeline 就是一个 Python 类,它必须实现一个 process_item(self, item, spider) 方法。
让我们来写一个简单的 Pipeline,它会打印出作者和内容。
编辑
pipelines.py文件:# my_first_scraper/pipelines.py class MyFirstScraperPipeline: def process_item(self, item, spider): # item 就是爬虫 yield 出来的对象 # spider 就是产生这个 item 的爬虫实例 print("="*20 + " [Pipeline] " + "="*20) print(f"作者: {item['author']}") print(f"内容: {item['text']}") print("="*52) # 必须返回 item,这样后续的 Pipeline (如果有的话) 才能继续处理 return item1
2
3
4
5
6
7
8
9
10
11
12
13在
settings.py中启用 Pipeline: 找到ITEM_PIPELINES设置,取消它的注释,并设置一个 1-1000 的优先级(数字越小,越先执行)。# my_first_scraper/settings.py # ... ITEM_PIPELINES = { 'my_first_scraper.pipelines.MyFirstScraperPipeline': 300, } # ...1
2
3
4
5
6
7
现在再次运行 scrapy crawl quotes,你不仅会看到 Scrapy 的日志,还会看到我们 Pipeline 打印出的格式化信息。在这里,你可以加入连接数据库、写入文件的代码,实现任何你想要的数据持久化逻辑。
掌握了 Scrapy,你就从一个“爬虫工匠”迈向了“爬虫架构师”。虽然入门曲线比 requests 陡峭,但它带来的工程化、高性能和高扩展性是无与伦比的。