 Scrapy 入门实战:从零到一构建你的第一个爬虫
Scrapy 入门实战:从零到一构建你的第一个爬虫
# Scrapy 入门实战:从零到一构建你的第一个爬虫
在理解了 Scrapy 的核心工作流程之后,是时候亲自动手,体验一下这个强大框架的魅力了。本教程将带你走过一个完整的 Scrapy 项目创建、编写、运行和配置的全过程。
# 一、环境准备与安装
# 1.1 标准安装
Scrapy 的安装通常很简单,只需要一条 pip 命令。为了提高下载速度,建议使用国内的镜像源。
# 使用清华大学镜像源安装 Scrapy
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scrapy
2
安装完成后,可以在终端输入 scrapy version 来验证是否安装成功。如果能正确显示版本号,说明你的环境已经准备就绪。
# 1.2 安装疑难解答 (当标准安装失败时)
在某些 Windows 环境下,由于缺少 C++ 编译环境或特定库的兼容性问题,直接安装 Scrapy 可能会失败,其中最常见的报错来源是 Twisted 库。
如果标准安装失败,请不要灰心,可以按照以下步骤手动安装依赖:
安装
wheel:这是一个用于处理 Python.whl格式安装包的工具。pip install wheel1下载并安装
Twisted的预编译包: 访问 UCI 的 Python 库非官方二进制包网站 (opens new window),这是一个非常有用的资源站。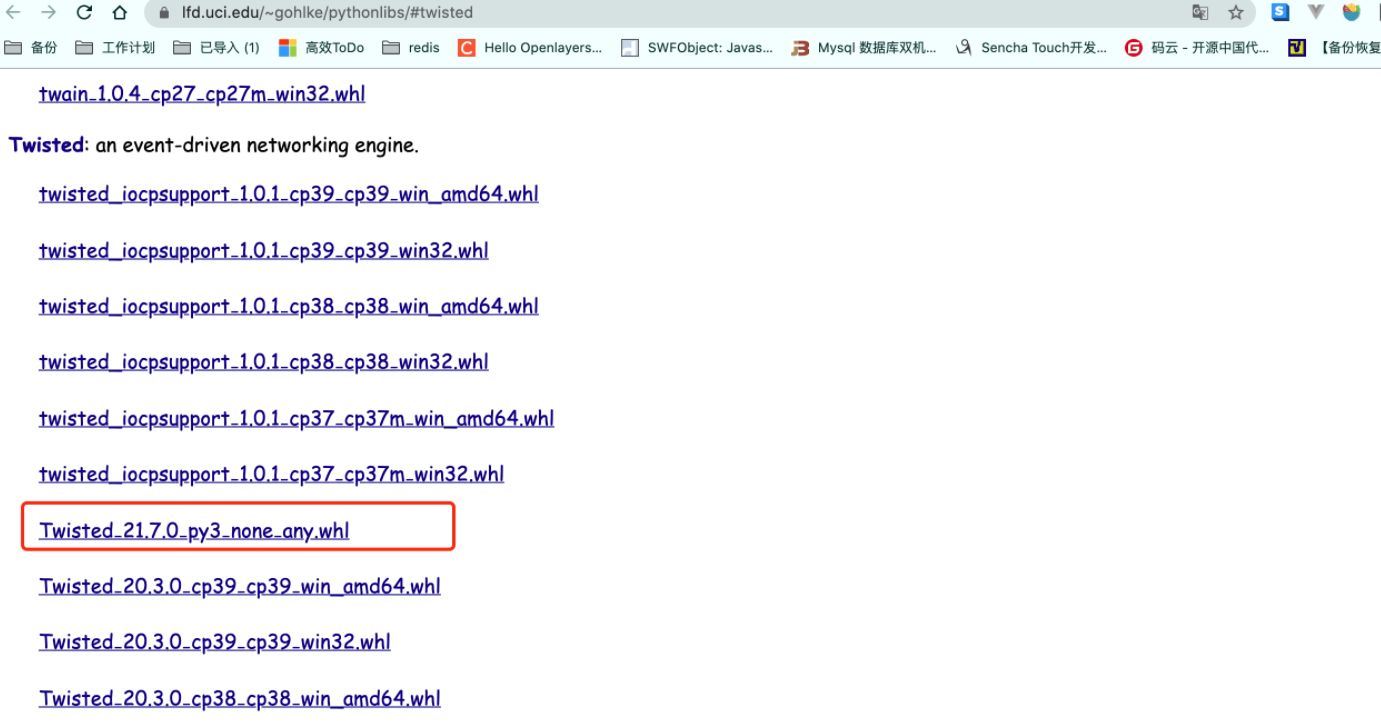 根据你的 Python 版本(如 cp39 代表 Python 3.9)和操作系统(win_amd64 代表 64 位 Windows)下载对应的
根据你的 Python 版本(如 cp39 代表 Python 3.9)和操作系统(win_amd64 代表 64 位 Windows)下载对应的 Twisted.whl文件。 下载后,在终端中进入文件所在目录,使用pip安装它:# 文件名请替换为你自己下载的实际文件名 pip install Twisted‑21.7.0‑py3‑none‑any.whl1
2安装
pywin32: 这是一个 Windows 平台下的 Python 扩展。pip install pywin321最后,再次安装 Scrapy:
pip install scrapy1通过以上步骤,基本可以解决绝大多数在 Windows 上的安装难题。
# 二、Scrapy 项目实现流程
一个标准的 Scrapy 项目开发流程可以归纳为以下四步,我们后续的教程也将围绕这四步展开:
- 创建项目: 使用
scrapy startproject <项目名>创建一个标准化的项目骨架。 - 定义数据: 在
items.py文件中,明确你想要抓取的数据字段。 - 编写爬虫: 在
spiders目录下创建爬虫文件,编写数据提取和 URL 跟进的逻辑。 - 处理数据: 在
pipelines.py文件中,编写数据清洗、验证和持久化存储的逻辑。
# 三、动手实践:创建一个段子抓取项目
# 3.1 创建 Scrapy 项目
首先,在你的工作目录下打开终端,执行以下命令:
# 创建一个名为 "mysider" 的 Scrapy 项目
scrapy startproject myspider
2
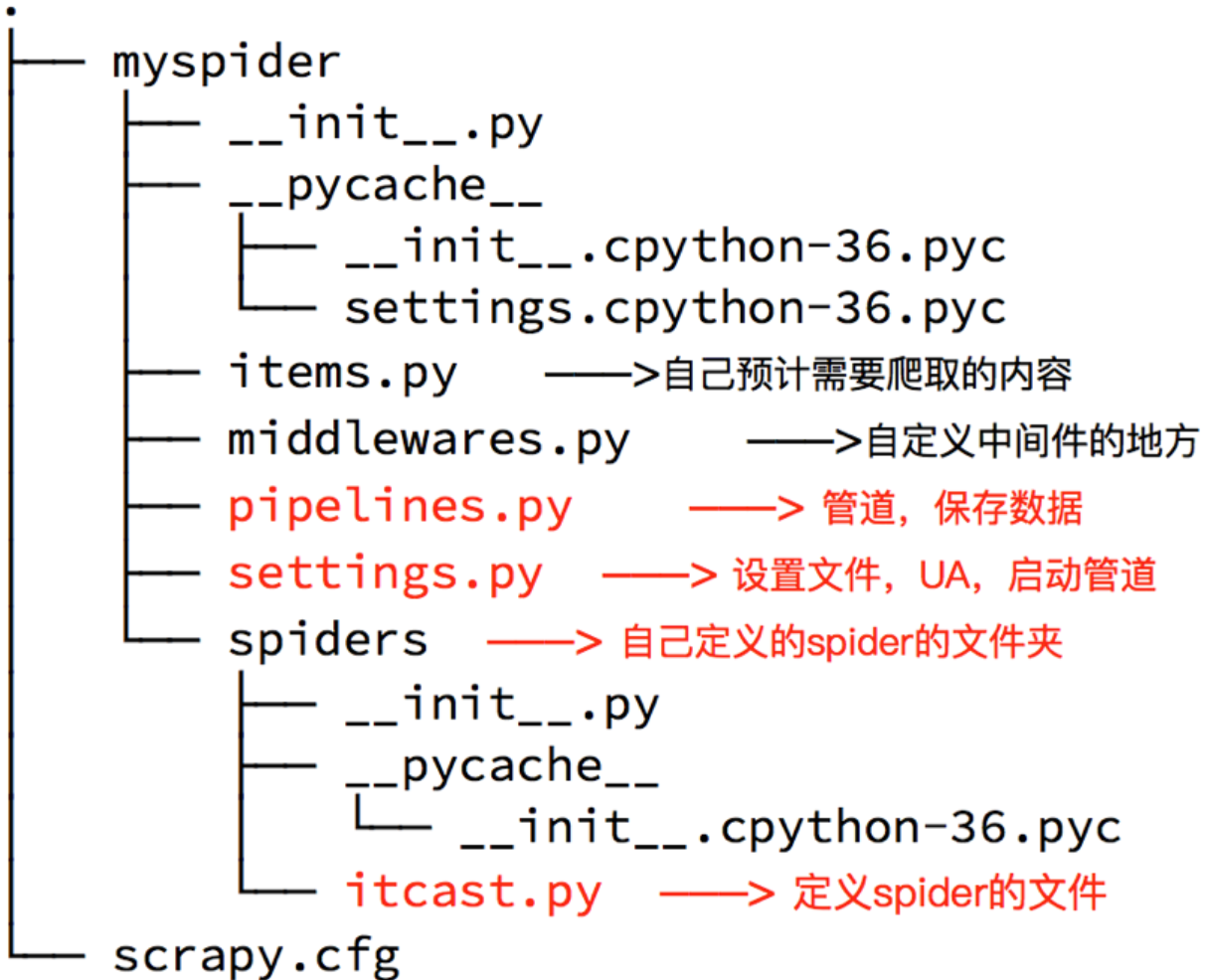
Scrapy 会自动生成一个名为 myspider 的文件夹,其内部结构如下,每个文件都有其明确的职责:

# 3.2 创建爬虫 (Spider)
进入项目的主目录(包含 scrapy.cfg 的那层),然后使用 genspider 命令生成一个爬虫。
# 首先进入项目目录
cd myspider
# 使用 genspider 命令
# 语法: scrapy genspider <爬虫名字> <允许爬取的域名>
scrapy genspider itcast duanzixing.com
2
3
4
5
6
这个命令会在 spiders 目录下创建一个 itcast.py 文件,这是我们接下来要编写主要逻辑的地方。
# 3.3 编写爬虫逻辑 (完善 Spider)
打开 /myspider/spiders/itcast.py 文件,你会看到一个基本的模板。现在,我们来填充它,让它能真正地提取数据。
import scrapy
# 自定义一个 Spider 类,必须继承自 scrapy.Spider
class DuanziSpider(scrapy.Spider):
# name: 爬虫的唯一标识名,用于在命令行中启动爬虫。
name = 'itcast'
# allowed_domains: (可选) 允许爬虫抓取的域名范围。
# 如果后续请求的 URL 超出此范围,将被自动过滤掉。
allowed_domains = ['duanzixing.com']
# start_urls: 爬虫启动时要抓取的第一个 URL 列表。
start_urls = ['http://duanzixing.com/']
# parse 方法是 Scrapy 默认的回调函数。
# 当 start_urls 中的请求成功返回响应后,此方法会被自动调用。
# response 参数就是下载器返回的、包含了整个网页内容的响应对象。
def parse(self, response, **kwargs):
# response.xpath() 使用 XPath 选择器来定位元素。
# 这里我们选取所有 class="excerpt" 的 article 标签。
article_list = response.xpath('//article[@class="excerpt"]')
# 遍历找到的每一个 article 标签
for article in article_list:
# .xpath() 的结果是一个 SelectorList 对象。
# 要获取其中的文本,我们需要继续使用 .xpath('./text()')
# 这里的 '.' 表示从当前 article 节点下开始查找。
# 使用 .extract_first() 提取第一个匹配的文本内容。
# 相比 .extract()[0],它更安全,因为即使没找到也不会报错,而是返回 None。
title = article.xpath('./header/h2/a/text()').extract_first()
# 提取 p 标签下的段子内容
con = article.xpath('./p[@class="note"]/text()').extract_first()
# 使用 yield 将提取到的数据封装成一个字典,并返回给 Scrapy 引擎。
# Scrapy 引擎接收到后,会将其传递给 Item Pipeline 进行处理。
yield {
'title': title,
'content': con
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# 3.4 启动爬虫
在终端中,确保你仍然在项目的主目录下,执行 crawl 命令:
# 语法: scrapy crawl <爬虫名字>
scrapy crawl itcast
2
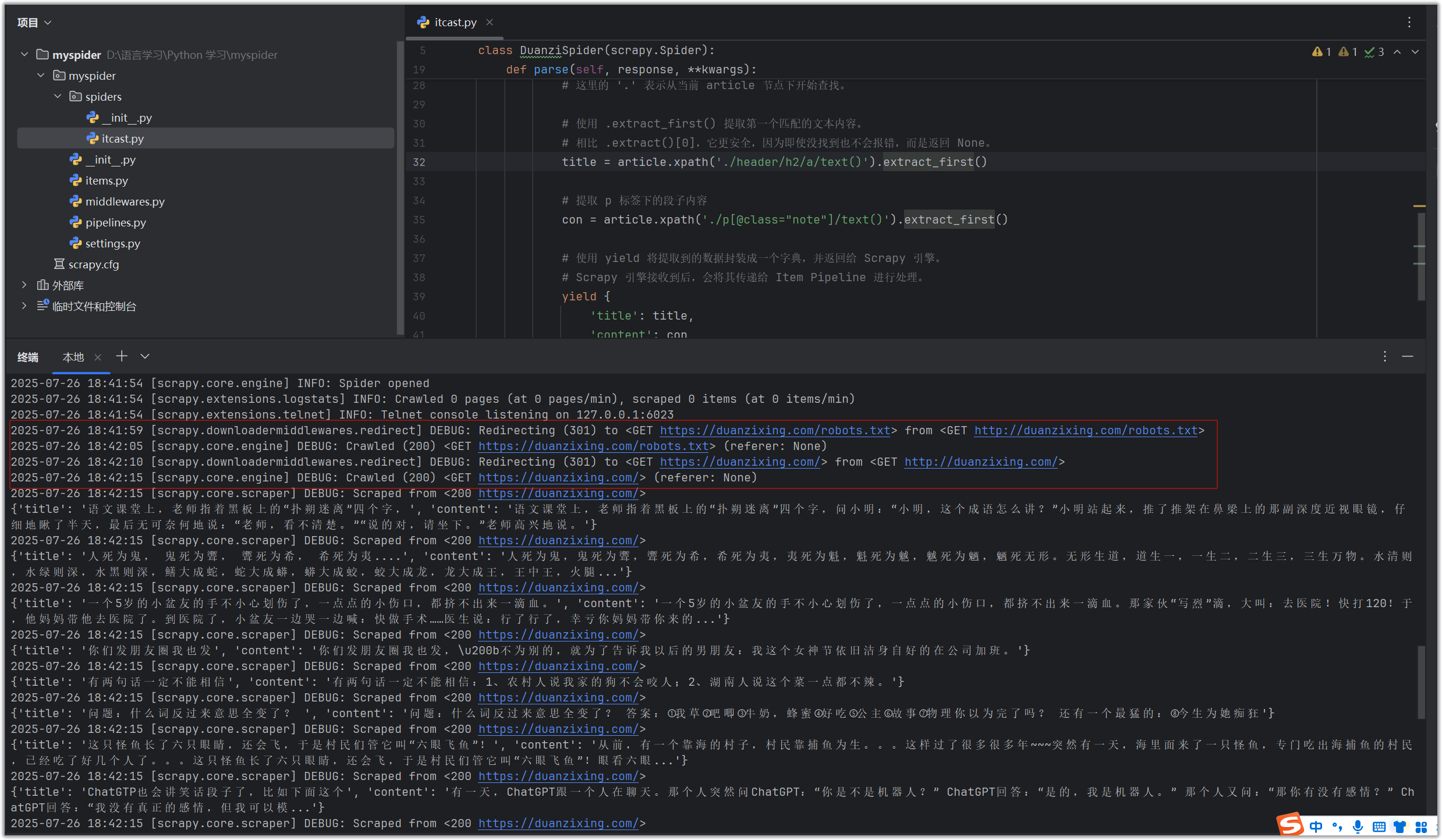
此时,你会在终端看到大量的日志信息,以及我们通过 yield 返回的数据字典。
# 四、项目配置与优化 (settings.py)
Scrapy 的强大之处在于其高度可配置性。所有的配置项都在 settings.py 文件中。
# 4.1 伪装 User-Agent
为了模拟真实的浏览器,避免被网站轻易识别为爬虫,设置 User-Agent 是最基本的操作。取消 settings.py 中 USER_AGENT 一行的注释,并换成一个常见的浏览器 User-Agent。
# settings.py
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
2
# 4.2 遵守或忽略 robots.txt
robots.txt 是网站所有者制定的君子协议,规定了允许哪些爬虫访问哪些页面。Scrapy 默认会遵守这个协议 (ROBOTSTXT_OBEY = True)。在学习阶段或确定不会对目标网站造成负担时,可以将其设置为 False。
# settings.py
ROBOTSTXT_OBEY = False
2
# 4.3 控制日志级别
默认情况下,Scrapy 会输出大量的 INFO 级别日志。为了让输出更清爽,只关注核心信息或错误,可以设置日志级别。
# settings.py
# 找到或添加这个配置项
LOG_LEVEL = 'ERROR' # 只显示错误信息
2
3
日志级别从高到低依次为:CRITICAL > ERROR > WARNING > INFO > DEBUG。
# 4.4 解决特定版本的依赖冲突
在某些 Python 或 Scrapy 版本组合下,可能会遇到 OpenSSL 相关的错误,例如 AttributeError: module 'OpenSSL.SSL' has no attribute 'SSLv3_METHOD'。
这通常是 cryptography 和 pyOpenSSL 库版本不兼容导致的。如果遇到,可以尝试降级这两个库来解决:
# 1. 卸载现有版本
pip uninstall cryptography pyOpenSSL
# 2. 安装指定的兼容版本
pip install cryptography==36.0.2 pyOpenSSL==22.0.0
2
3
4
5
这是特定时期的解决方案,随着库的更新,未来可能不再需要或需要其他版本组合。
# 五、进阶学习
恭喜你!你已经成功构建并运行了你的第一个 Scrapy 爬虫。
当你准备好深入学习时,我们强烈建议你详细了解 Scrapy 中最核心的 Response 对象,它是你进行数据提取的全部依据。
- Scrapy 核心对象:Response 超详细指南:深入探索
response.url,response.text,response.body,response.xpath(),response.css()以及强大的response.follow()方法。