 Scrapy 框架核心:深入理解其工作流程
Scrapy 框架核心:深入理解其工作流程
# Scrapy 框架核心:深入理解其工作流程
# 一、初识 Scrapy 框架
# 1.1 什么是 Scrapy?
Scrapy 不是一个简单的库,而是一个为了爬取网站数据、提取结构化数据而编写的、功能强大的应用程序框架。你可以把它想象成一个高度集成化的“爬虫工厂”,它已经为你搭建好了生产线(请求调度、异步处理、数据管道、反爬支持),你只需要作为“总工程师”,专注于设计蓝图(编写数据提取规则)即可。
# 1.2 为什么选择 Scrapy?
当我们处理简单的爬虫任务时,requests + BeautifulSoup 的组合拳非常灵活高效。但随着项目规模的扩大,我们需要面对以下挑战:
- 性能:如何同时发送上百个请求以提高效率?
- 调度:如何管理成千上万个待爬取的 URL,并有效去重?
- 工程化:如何让数据提取、数据清洗、数据存储的流程解耦,易于维护?
- 扩展性:如何方便地加入代理 IP、随机 User-Agent 等反爬策略?
Scrapy 正是为解决这些问题而生的。它的核心优势在于:
- 天生异步:基于 Twisted 异步网络框架,Scrapy 可以在等待一个请求响应的同时,发送其他请求,极大地提升了爬取效率。
- 高度模块化:架构清晰,组件分离,让你可以独立地处理请求、解析、数据存储等不同环节。
- 强大的中间件和管道系统:提供了丰富的钩子,可以轻松定制和扩展功能,实现复杂的反爬策略和数据处理流程。
- 自带选择器:内置了强大的 CSS 和 XPath 选择器,无需额外安装解析库。
# 二、从传统爬虫到 Scrapy 架构的演进
要理解 Scrapy 为何如此设计,我们可以回顾一下爬虫程序的演进过程。
# 2.1 传统爬虫的线性流程
最基础的爬虫是一个线性的、同步的过程:发送请求 -> 获取响应 -> 解析数据 -> 保存数据 -> 发送下一个请求... 这种模式简单直观,但效率低下,因为程序在等待网络响应时完全处于阻塞状态。
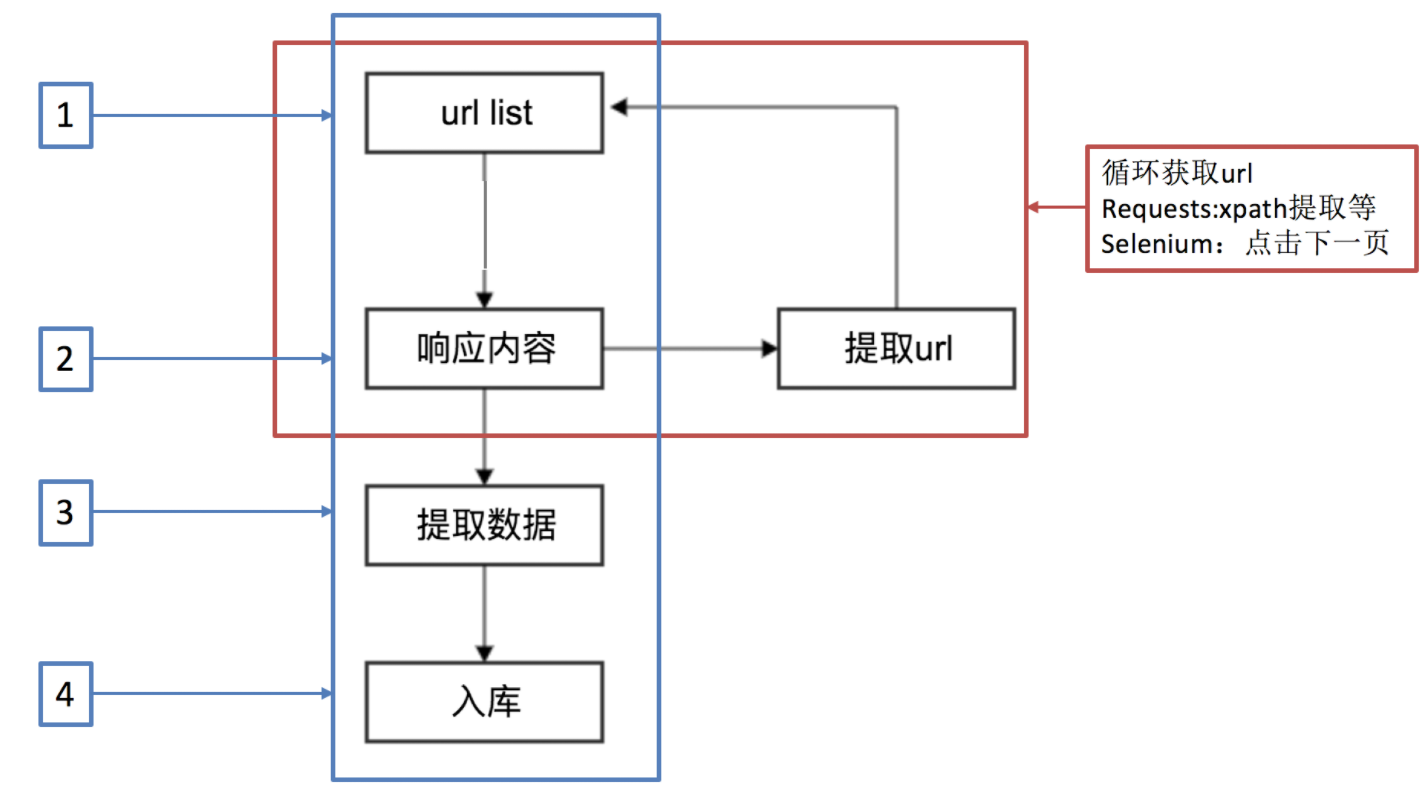
# 2.2 引入调度器:解耦与复用
为了管理大量的 URL 并避免重复抓取,我们自然会想到引入一个“URL 管理器”(即调度器)。爬虫不再自己决定下一个抓取谁,而是将新发现的 URL 都交给调度器,然后从调度器获取下一个任务。这实现了爬取逻辑和 URL 管理的解耦。
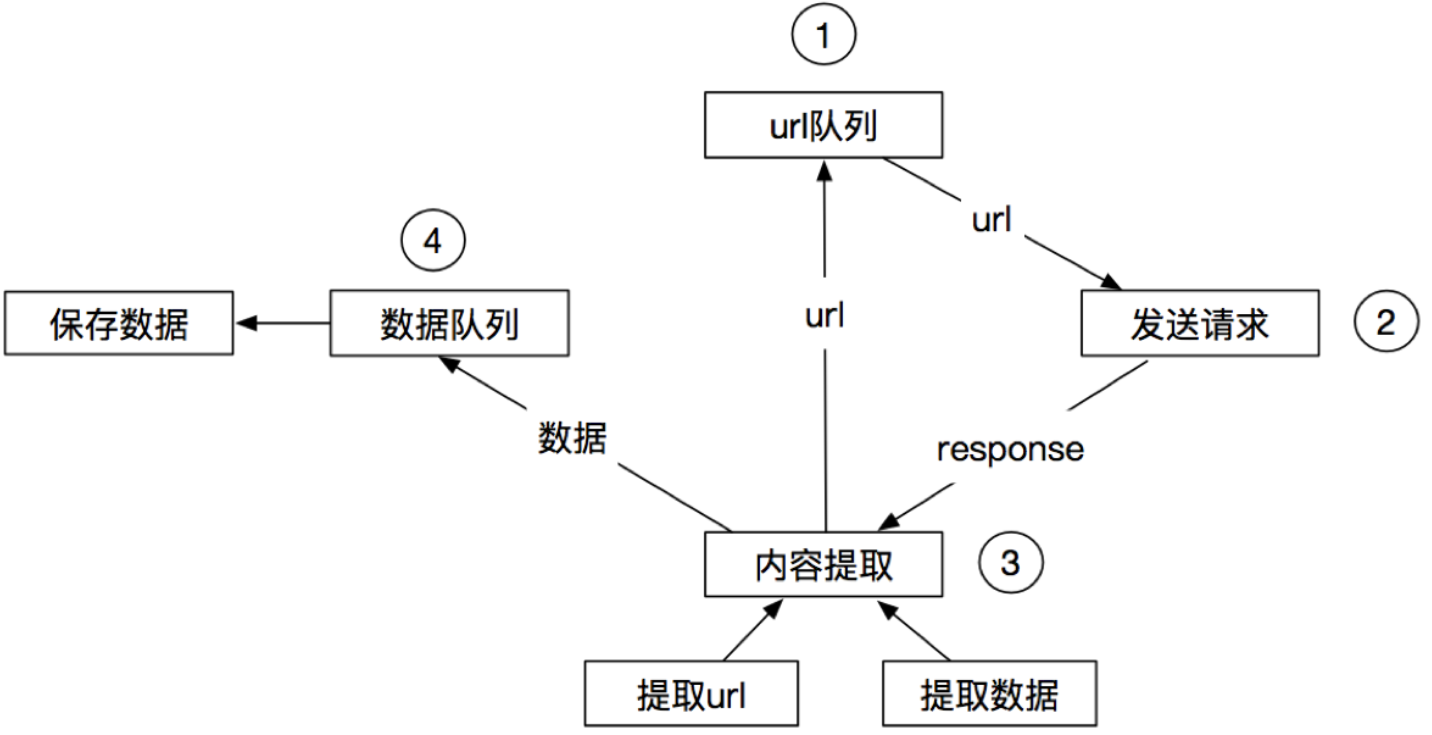
Scrapy 的设计正是基于这种思想,并将其发展到了极致,形成了一套完整、高效的分布式数据流系统。
# 三、Scrapy 的核心工作流程详解
这是 Scrapy 的灵魂所在。理解这张图,你就理解了 Scrapy 的一半。
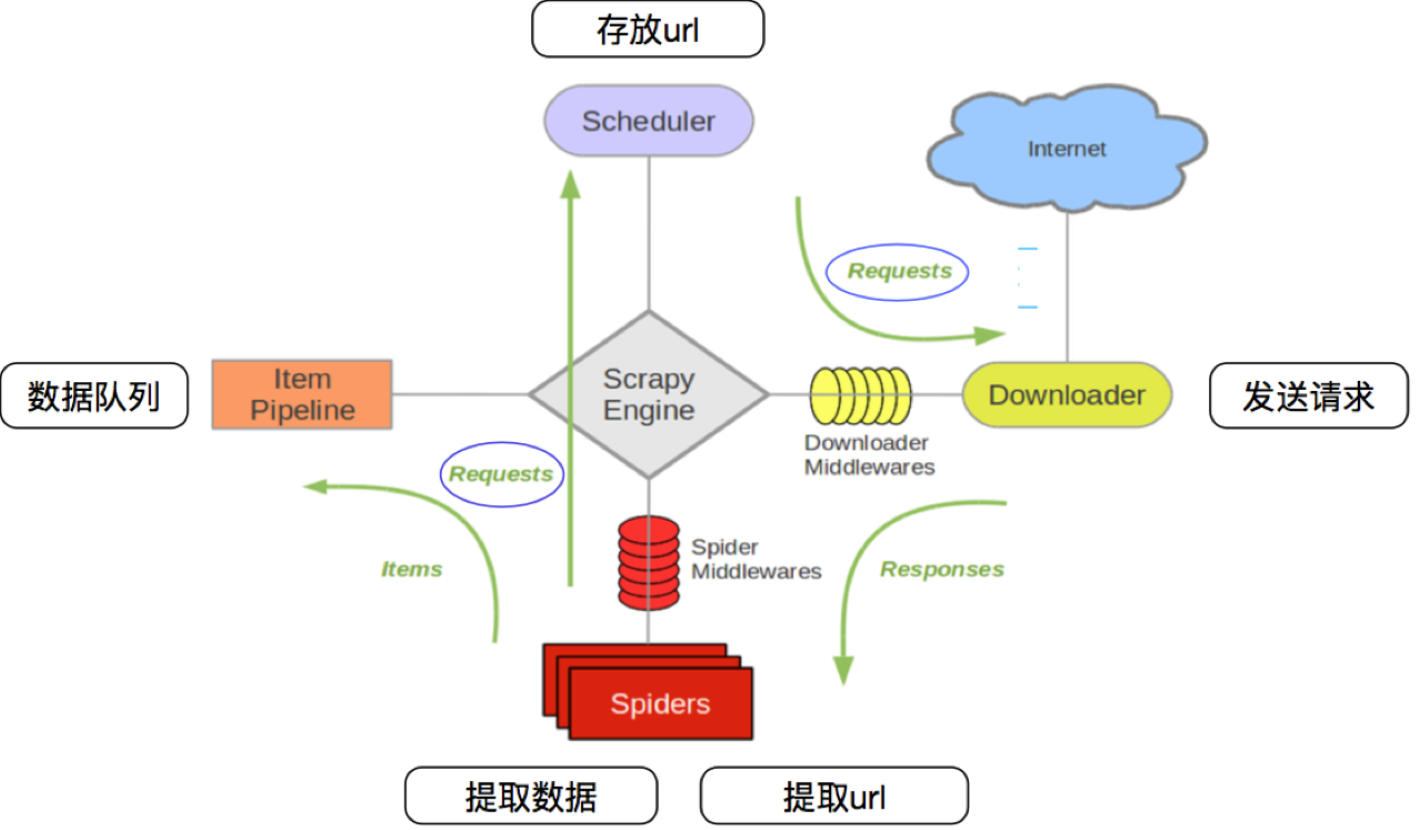
整个数据流由引擎 (Engine) 统一协调,可以描述为以下步骤:
- 引擎启动:引擎从爬虫 (Spider) 中获取初始请求(
start_requests)。 - 请求入队:引擎将这些请求交给调度器 (Scheduler)。调度器会将请求放入队列,并进行去重等管理。
- 请求出队:引擎向调度器索要下一个要抓取的请求。
- 发送请求:引擎将从调度器拿到的请求,通过下载中间件 (Downloader Middlewares),发送给下载器 (Downloader)。
- 执行下载:下载器执行网络请求,获取服务器的响应 (Response)。
- 响应返回:下载器将响应通过下载中间件,返回给引擎。
- 响应送达爬虫:引擎将响应通过爬虫中间件 (Spider Middlewares),发送给我们编写的爬虫 (Spider) 进行处理。
- 爬虫处理:爬虫的
parse等回调方法被调用,处理这个响应。在处理过程中,爬虫会:- 提取数据:解析响应,生成结构化的数据 (Item)。
- 生成新请求:发现新的 URL,生成新的请求 (Request) 对象。
- 数据处理:如果爬虫生成了数据 (Item),引擎会将其送往项目管道 (Item Pipeline) 进行后续处理(如清洗、存入数据库)。
- 新请求入队:如果爬虫生成了新的请求 (Request),引擎会将其再次送往调度器(回到第2步),形成循环,直到调度器中再也没有新的请求为止。
注意:图中的绿色线条代表数据(请求、响应、Item)的传递路径。所有组件都只与引擎交互,实现了高度的解耦。
# 四、Scrapy 各核心组件解析
现在,我们来详细了解每个组件的具体职责。

引擎 (Engine)
- 职责:Scrapy 的“中央处理器”,是整个框架的心脏。它负责在所有组件之间驱动数据流,并根据不同事件(如新的请求、新的响应)调用相应的组件来处理。你通常不需要直接与引擎交互。
调度器 (Scheduler)
- 职责:一个智能的“任务队列管理器”。它接收引擎发来的请求,并按照一定的策略(如 LIFO, FIFO)将其存入队列。最重要的是,它会自动对请求进行去重,避免重复抓取同一个 URL。
下载器 (Downloader)
- 职责:一个勤勤恳恳的“下载工人”。它负责根据引擎传递过来的请求对象 (Request),发起 HTTP/HTTPS 请求,并将获取到的响应对象 (Response) 返回给引擎。它是基于
Twisted异步库实现的,能处理大量并发请求。
- 职责:一个勤勤恳恳的“下载工人”。它负责根据引擎传递过来的请求对象 (Request),发起 HTTP/HTTPS 请求,并将获取到的响应对象 (Response) 返回给引擎。它是基于
爬虫 (Spiders)
- 职责:这是我们代码逻辑的核心。开发者通过继承
scrapy.Spider类,定义如何从一个页面开始爬取、如何从响应中提取数据、以及如何发现新的链接并生成新的请求。
- 职责:这是我们代码逻辑的核心。开发者通过继承
项目管道 (Item Pipeline)
- 职责:数据的“加工流水线”。当爬虫提取出数据 (Item) 后,会将其送入管道。在这里,你可以按顺序执行一系列处理操作,例如:
- 清洗数据(去除 HTML 标签、格式化数据)。
- 验证数据(检查字段是否缺失)。
- 丢弃无效数据。
- 将数据持久化存储(写入文件、存入 MySQL、MongoDB 等数据库)。
- 职责:数据的“加工流水线”。当爬虫提取出数据 (Item) 后,会将其送入管道。在这里,你可以按顺序执行一系列处理操作,例如:
下载器中间件 (Downloader Middleware)
- 职责:介于引擎和下载器之间的“安检口”。它可以在请求被发送前(
process_request)和响应被接收后(process_response)对其进行全局性的修改。这是实现反爬策略的核心位置,例如:- 设置随机的
User-Agent。 - 添加代理 IP。
- 处理 Cookies。
- 设置随机的
- 职责:介于引擎和下载器之间的“安检口”。它可以在请求被发送前(
爬虫中间件 (Spider Middleware)
- 职责:介于引擎和爬虫之间的“过滤器”。它可以在响应被爬虫处理前(
process_spider_input)和爬虫生成的数据/请求被引擎接收前(process_spider_output)进行干预。
- 职责:介于引擎和爬虫之间的“过滤器”。它可以在响应被爬虫处理前(
# 五、总结
Scrapy 的概念:Scrapy 是一个为了爬取网站数据、提取结构性数据而专门编写的高性能应用框架,其核心是异步IO和模块化设计。
Scrapy 的优势:通过预置的架构和异步机制,开发者只需编写少量的核心逻辑代码,就能实现快速、稳定、可扩展的数据抓取。
核心组件:必须深刻理解引擎、调度器、下载器、爬虫、管道这五大核心组件的职责和它们之间的数据流转关系。
扩展性:下载器中间件和爬虫中间件为我们提供了强大的定制能力,是实现高级功能(如反爬、数据过滤)的关键。
异步与非阻塞:要记住,Scrapy 的高性能源于其异步非阻塞的特性。这意味着它在等待网络IO时不会被卡住,可以同时处理多个任务,这是它与传统同步爬虫最根本的区别。